基于MD5&ASCII的时序性数据一致性比较装置及方法与流程
本发明属于一致性比较领域,涉及一种基于md5&ascii的时序性数据一致性比较装置及方法。
背景技术:
1、很多企业在基于大户数据平台组件进行数据湖数据同步的时候,必须向数据应用方证明目的端数据同步的一致性,目前比对工作面临的问题是:源端和目的端的数据存储平台异构,缺乏手段,直接进行异构数据端之间数据的一致性校验;对源端和目的端基于数据库引擎直接进行数据比对,影响数据库的使用性能和可用连接数;大批量数据比对容易消耗完数据库或第三方硬件资源,造成结果无法输出;遇见长文本或二进制字段比对时,会严重消耗系统性能;源端和目的端数据类型基于数据库本身设置,类型多种多样。需实现比较时,内容格式上的一致性。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于md5&ascii的时序性数据一致性比较装置,提供一种组件类工具,实现低成本、高通用,多线程的进行异步的数据一致性比对工作。
2、为达到上述目的,本发明提供如下技术方案:
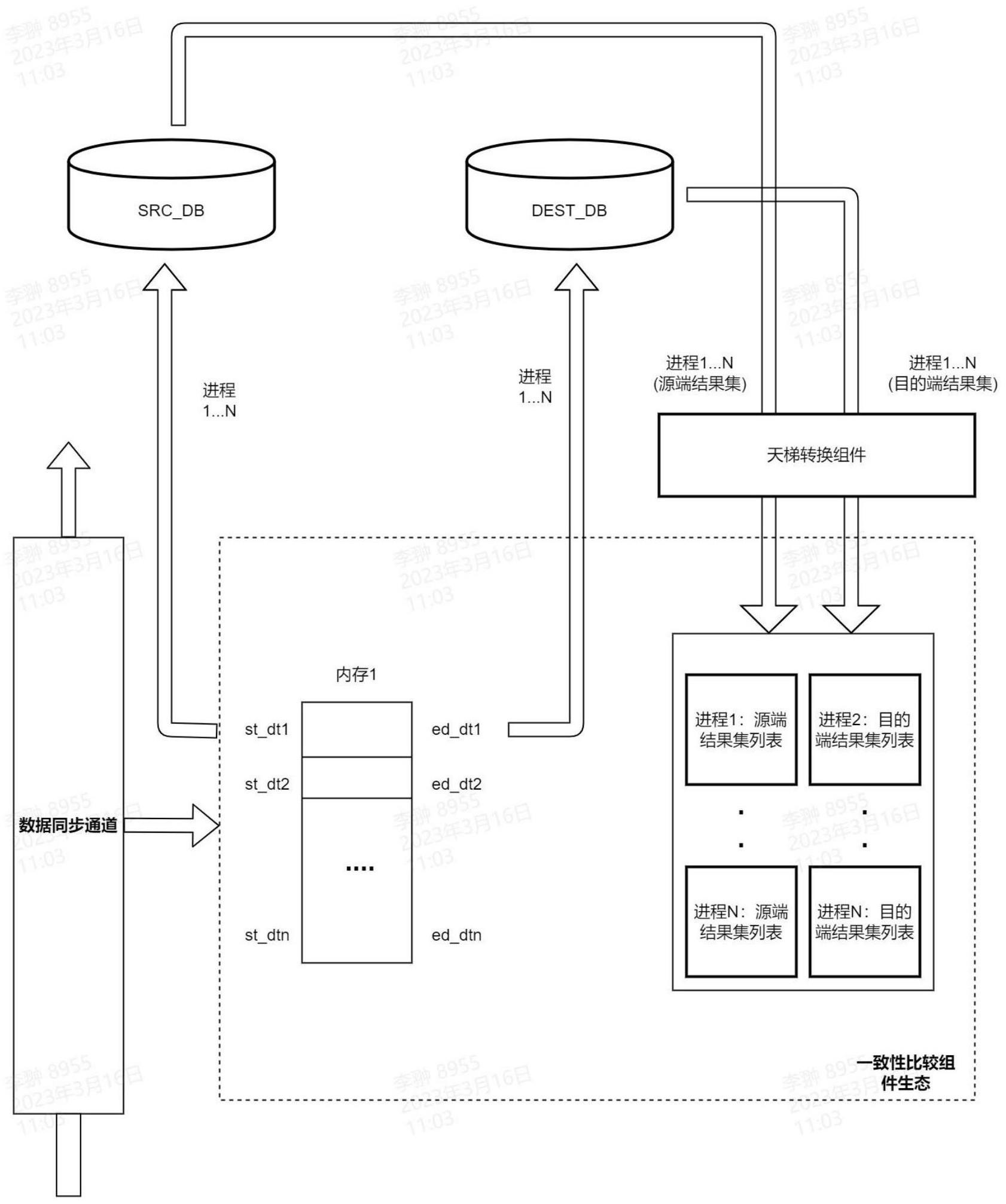
3、一种基于md5&ascii的时序性数据一致性比较装置,包括类型转换天梯系统,内存数据库,数据比较分析模块,配置文件组;
4、所述类型转换天梯系统用于将异构数据系统的数据类型以及格式进行统一,实现输入数据比较分析模块的内容是一致的;
5、所述内存数据库用于对时间切片的数据进行临时存储并在完成后销毁,还用于存储异常数据条目;
6、所述数据比较分析模块用于将同一时间切片中的两队列数据进行md5码加ascii码的转换以及基于字符代码的计算,并将异常数据输出到内存数据库;
7、所述配置文件组用于控制可同步开启的最大进程数,设置时间切片的间隔,配置内存数据库连接信息。
8、进一步,所述类型转换天梯系统由数据适配器,类型天梯对比表,数据逻辑分析模块构成;
9、所述数据适配器,负责采集源端和目的端表/流中字段类型以及相关信息,并在最后按操作逻辑,从输出端发送转换内容;
10、所述类型天梯转义模块,包含一套各数据库或系统间的类型兼容性对比表,依据兼容性高低对类型进行分层;对传入的源端的信息进行信息转换,并将包含转移后源端字段类型信息的新的参数集传递给数据元素分析模块;
11、所述数据元素分析模块,对从类型天梯转义模块传入的数据进行分析,对数据类型的多维度信息进行判断,是否要对输出或目的端字段规范进行重定义。
12、进一步,所述数据比较分析模块对同一时间切片中的两队列数据进行md5转换,变成32位长的字符串,并进行大写转换;此时列内容转写的字符串,只包括0-9、a-z;对转完后的字符串进行ascii码转换,变成32个整形数后进行求和;然后将每一列以序号从小到大的顺序,按步长1进行累加求和,直到比较完所有数据,当和值在某一轮循环累加中出现不一致时,该轮次对应的序号就是出现一致性问题的源与目的记录行所在次序,将存在一致性问题的轮次对应的联合主键和列名记录在内存数据库中。
13、另一方面,本发明提供一种基于md5&ascii的时序性数据一致性比较方法,包括以下步骤:
14、s1:定时在内存中形成时间切片,在内存中记录下时间切片中抽取的记录行的联合主键列表;
15、s2:启动线程,将联合主键作为唯一性索引,同时从源端和目的端拿到数量可接受的对应的记录行,并基于联合主键排序;在类型天梯转义模块中配置一致性比较装置与其他数据库产品类型转换的对照关系,在数据提取时,将源端和目的端的数据向一致性比较装置设置的类型转写,实现内容的格式一致;
16、s3:在数据比较分析模块中对每行记录的每一列进行数据内容md5码加ascii码的转换以及基于字符代码的计算,并将异常数据输出到内存数据库;
17、s4:基于配置文件的设置值,控制并发分析的线程的数量。
18、进一步,所述联合主键通过获取源端的系统表,或配置文件的内容来获取。
19、进一步,步骤s3具体包括:
20、s31:对列中的内容进行md5转换,变成32位长的字符串,并进行大写转换;此时列内容转写的字符串,只包括0-9、a-z;
21、s32:对转完后的字符串进行ascii码转换,变成32个整形数后进行求和;
22、s33:基于步骤s2的排序,将每一列以从小到大的顺序,按步长1进行累加求和;
23、s34:当和值在某一轮循环累加中出现不一致时,该轮次对应的序号就是出现一致性问题的源与目的记录行在步骤s2中的次序,将该轮次对应的联合主键和列名,记录在内存数据库中;
24、s35:越过步骤s34中出现问题的循环次序,继续进行和值累加的比较直到比较完成,如又出现不一致,则进入步骤s34,如果完成比较,则释放内存。
25、进一步,类型天梯转义模块的工作流程如下:
26、当数据任务进行到需要"数据类型同步兼容"步骤时,数据适配器被触发开启,通过拉取或接收数据流中的必要参数,适配器组装成查询语句,向源端数据源发出查询请求,获取数据流对应的元结构/属性信息,为后续步骤做准备;
27、当必要信息采集后,类型天梯转义模块按照源端表字段的类型取出目的端相应字段类型,为后续对比做准备;
28、在流中比较源端字段是否存在于目的端;当源端字段不在目的端中时,直接走向数据定义语言编译模块;
29、当源端字段存在于目的端结构中时,将参数包传递给数据元素分析模块,通过对比流中源端和目的端的数据信息,判定目的端流中是否需要发生调整;
30、数据定义语言模块根据前置步骤传入的参数包,利用参数自动生成对应目的端的数据定义语言脚本,并通过数据适配器向目的端发送输出转义内容。
31、进一步,所述按照源端表字段的类型取出目的端相应字段类型,具体包括以下提取策略:
32、从天梯表文件找到源端数据库在"读"分页中该字段类型对应的层级代码level;
33、从天梯表文件中,找到目的端数据库在"写"分页上对应于该层级的目的端字段类型;
34、将提取到的信息进行封包,供下一步骤使用。
35、进一步,所述通过对比流中源端和目的端的数据信息,判定目的端流中是否需要发生调整,其判定操作分为两步:
36、(1)判断流中源端字段经转义后取得的兼容性层级代码值是否比流中目的端字段现有字段类型的兼容性层级数值大:如果大于目的端字段现有兼容性层级,则目的端字段数据类型必然要调整;如果小于等于则进行下一步;
37、(2)转义前源端数据类型的长度、精度、格式,与目的端的对应字段现有长度、精度、格式作比较;当任一元素不满足目的端字段数据结构的约束,则对参数进行封包,向后续步骤传递信息。
38、本发明的有益效果在于:本发明是基于异构数据库大数据量表组同步时,需要校验源端和目的端进行同步后,数据全量与增量一致性,而又不能明显影响线上业务的需求而提出。本发明通过编程语言自带的md5和ascii码方法,利用时间戳字段,将源端与目的端的数据在工具中进行清洗转换后比较一致性情况。提供了侦测异构的数据源和目的端的同步一致性的通用方法。本方法不需要将比较的计算压力放在数据库引擎上;第三方组件跨过异构数据库间数据比较的麻烦;多时间切片多进程并发,小批量数据集合比较,处理能力提高;对数据进行多次转换后,不同数据结果一致的概率明显减小;能够快速定位错误记录的行列位置,不阻塞并发分析的进行。
39、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!