基于ReRAM的深度神经网络加速器剪枝方法及系统
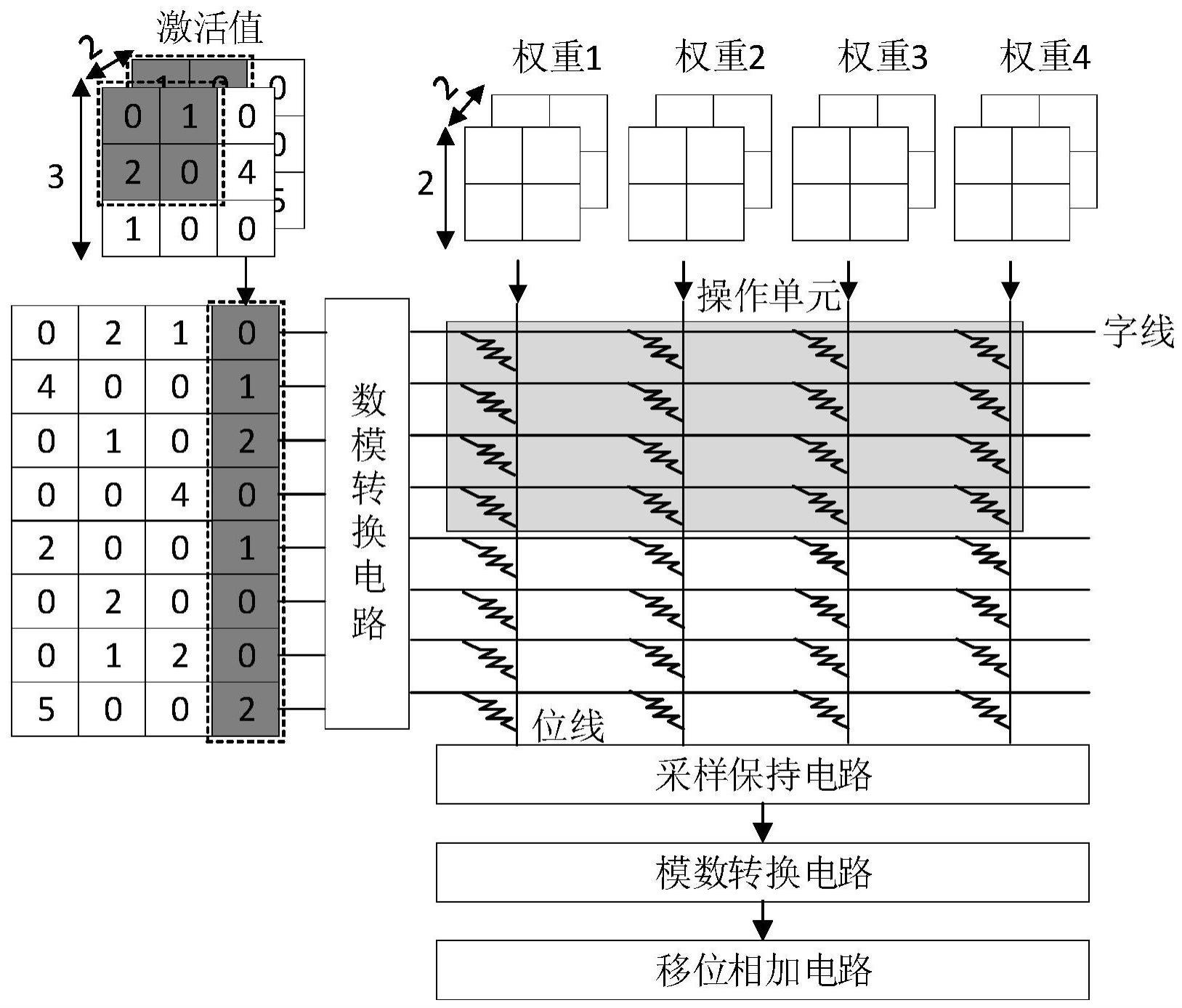
本发明涉及深度神经网络加速器设计,尤其涉及一种基于reram的深度神经网络加速器剪枝方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、近年来,深度神经网络(deep neural network dnn)在人工智能领域,包括计算机视觉、语音识别、自然语言处理方面取得了巨大成功。为了提高应用精度,增加神经网络的层数成为了一种行之有效的方法。但随着网络层数的增加,相应的所需计算的参数量也随之增长,传统的基于冯诺依曼架构的处理器在执行神经网络运算时面临着内存墙的问题,内存性能严重影响了处理器性能发挥。工业界与学术界也已经提出了一些专有的加速架构来提高dnn系统的性能,例如gpu和tpu。但这些加速器大多由于处理器和内存之间的大量数据移动,不可避免地面临高能耗和长延迟开销。随着摩尔定律达到极限,基于传统技术的加速架构潜力有限。
3、存内计算架构(processing in memory)的出现有效解决了上述问题,作为一种新型计算架构,其基本思想是将计算和存储结合在一起,将计算操作直接放在内存中完成。相较于传统的cpu和内存分离的计算架构,使用存内计算技术可以直接在内存中进行数据交互与计算处理,大大减少了数据传输造成的延迟,有望打破内存墙。在此基础上,电阻式随机存取存储器(reram)作为一种新兴的非易失性存储器件,近年来成为存内计算架构设计的热门器件选择。其通过调节电阻值来实现数据存储,与传统存储器件相比,reram具有更高的存储密度、更低的能耗、更快的读写速度和更长的寿命。以reram cell为单元组成的crossbar结构,更是凭借支持就地矩阵向量乘法(mac)操作,使reram成为加速dnn尤其是卷积神经网络的一种非常有前途的存储器件。作为一种传统的深度神经网络模型,卷积神经网络中卷积层运算占据了整体网络模型95%以上的运算量,需要大量的计算资源。传统的计算架构采用cpu或gpu来计算卷积操作,而由于reram crossbar支持就地mac操作,因此可以直接将卷积核数据存储在reram中,直接在reram中执行卷积操作,避免了大量数据的传输和存储,从而大大提高了计算速度和能效。
4、近年来,为了进一步提升基于reram的dnn加速器的处理性能,一些传统dnn加速优化方式也不断地被卸载到加速器框架设计中。在这其中,剪枝技术得到了广泛的关注。作为一种常用于神经网络加速和压缩的方法,它利用reram的非易失性和高密度存储特性,可以在不牺牲模型准确率的情况下减小神经网络的尺寸。而针对卷积层中的权重与激活值两部分,自然而然地产生了两种剪枝技术,即权重剪枝与激活值剪枝。现有针对激活值剪枝的策略研究的比较少,已知的剪枝策略中主要是通过移除被量化的激活值中的零比特位来跳过非必要的运算,进而实现运算的加速。然而上述方式在实际应用过程中的加速效果并不理想。因此,如何在不影响系统精度的前提下很大程度上提升系统运算速度并减少系统功耗,成为现有技术亟待解决的问题。
技术实现思路
1、针对现有技术存在的不足,本发明的目的是提供一种基于reram的深度神经网络加速器剪枝方法及系统,利用卷积神经网络激活值的稀疏性设计剪枝策略,适配reramcrossbar结构,通过对非敏感激活值行列进行剪枝减少系统运行过程中不必要的运算次数,维持系统运行并行性的同时提升系统运算速度并降低系统功耗。
2、为了实现上述目的,本发明是通过如下的技术方案来实现:
3、本发明第一方面提供了一种基于reram的深度神经网络加速器剪枝方法,包括以下步骤:
4、获取当前卷积层的激活值矩阵,以行列做为剪枝粒度设置标志位和阈值;
5、根据标志位统计激活值的稀疏度,根据稀疏度进行排序;
6、根据给定阈值标定敏感激活值行列与非敏感激活值行列,对非敏感激活值行列进行剪枝;
7、利用激活值高位与权重进行卷积,得到高位运算结果,并根据高位运算结果对下一层非敏感激活值行列进行剪枝;其中,根据高位运算结果对下一层非敏感激活值行列进行剪枝的过程中,根据下一层激活值矩阵中行列的产生次序,依次统计激活值矩阵行列稀疏度,并标识无需执行低位卷积运算的计算过程;对统计结果进行排序,并根据给定阈值按照排序结果对激活值矩阵非敏感行列进行剪枝。
8、进一步的,通过根据标志位统计激活值矩阵行或列中的零的个数来统计激活值的稀疏度。
9、进一步的,根据当前卷积层的激活值矩阵需要进行行剪枝或列剪枝或行列混合剪枝的情况设置标志位。
10、进一步的,根据剪枝操作中需要剪枝的行列数占当前层激活矩阵中总行列数的比例设定阈值。
11、进一步的,利用激活值高位与权重进行卷积,得到高位运算结果的具体过程为:
12、首先将激活值与权重值量化至8位,随即使用激活值的高n位与权重的全8位进行乘加操作,得到的当前层的高位运算结果。
13、进一步的,根据高位运算结果对下一层非敏感激活值行列进行剪枝的具体过程为:
14、利用高位运算结果执行下一层的非敏感激活值剪枝;同时,标记经过非线性层后仍保持正值的计算过程;
15、如果高位运算结果在经过非线性层后仍大于0且该高位运算结果所在的行列未被剪枝,则计算该高位运算结果对应的低位运算结果并与高位运算结果相加,作为下一卷积层的激活值继续参与运算。
16、更进一步的,将所有低位运算结果与高位运算结果相加,形成下一层完整的激活值并向下层传递。
17、本发明第二方面提供了一种基于reram的深度神经网络加速器剪枝系统,包括:
18、设置模块,被配置为获取当前卷积层的激活值矩阵,以行列做为剪枝粒度设置标志位和阈值;
19、排序模块,被配置为根据标志位统计激活值的稀疏度,根据稀疏度进行排序;
20、剪枝模块,被配置为根据给定阈值标定敏感激活值行列与非敏感激活值行列,对非敏感激活值行列进行剪枝;
21、卷积模块,被配置为利用激活值高位与权重进行卷积,得到高位运算结果,并根据高位运算结果对下一层非敏感激活值行列进行剪枝;其中,根据高位运算结果对下一层非敏感激活值行列进行剪枝的过程中,根据下一层激活值矩阵中行列的产生次序,依次统计激活值矩阵行列稀疏度,并标识无需执行低位卷积运算的计算过程;对统计结果进行排序,并根据给定阈值按照排序结果对激活值矩阵非敏感行列进行剪枝。
22、本发明第三方面提供了一种介质,其上存储有程序,该程序被处理器执行时实现如本发明第一方面所述的基于reram的深度神经网络加速器剪枝方法中的步骤。
23、本发明第四方面提供了一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如本发明第一方面所述的基于reram的深度神经网络加速器剪枝方法中的步骤。
24、以上一个或多个技术方案存在以下有益效果:
25、本发明公开了一种基于reram的深度神经网络加速器剪枝方法及系统,以采用新型存储介质reram的存内一体化结构为基础,提出了面向深度神经网络的动态实时激活值剪枝的存内计算策略,通过执行非敏感激活值行列剪枝,便可以跳过许多“操作单元”的运算过程,节省运算次数,进而减少reram crossbar与各种外围电路的工作次数,极大地减少了系统运算量,有效地提升了系统性能,减少了系统功耗。本发明通过剪枝大量稀疏激活值,搭配高位激活值与权重卷积的高位运算预测技术与前向传播中断延时隐藏技术,在进一步提升系统性能的基础上,减少由于非敏感激活值搜索与剪枝造成的前向传播中断造成的延时。
26、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!