一种视线估计方法和系统
本发明涉及图像识别,特别是涉及一种视线估计方法和系统。
背景技术:
1、视线是人类注意力和兴趣的表现,其中蕴含着内心状态和行为意图等信息,同时,人的视线具有直接性、自然性和双向性等其他信息所无法具备的特点,因此人们对视线估计的研究有着深厚的兴趣。在面部识别的基础上,我们可以进一步利用视线估计技术,计算出用户在屏幕上所关注的区域。视线估计技术的应用领域十分广阔,例如:智能家电、广告研究、智能计算机和虚拟游戏等领域。现有的视线估计方法大致可分为基于模型的方法和基于表观的方法,其中基于模型的方法对硬件和实验环境要求较高,这导致其无法适用于复杂多变的现实应用场景,模型的识别率和泛化能力不高。
2、现有技术公开了一种视线估计方法和装置,该方法包括获取目标图像,目标图像呈现有待测用户的面部图像,对目标图像进行面部特征检测,得到待测用户的面部特征信息,将目标图像和所述面部特征信息输入至机器学习模型中进行视线估计,得到机器学习模型输出的视线估计结果,现有技术仅采用脸部特征进行视线识别,而忽略了具有个性化信息的眼部特征,导致视线估计的准确率低;并且用于训练模型的人物图像单一,导致在识别新人物的时候,视线估计的准确率低,模型的泛化能力不高。
技术实现思路
1、本发明的目的是提供一种基于脸部特征和眼部个性化特征的视线估计方法和系统。
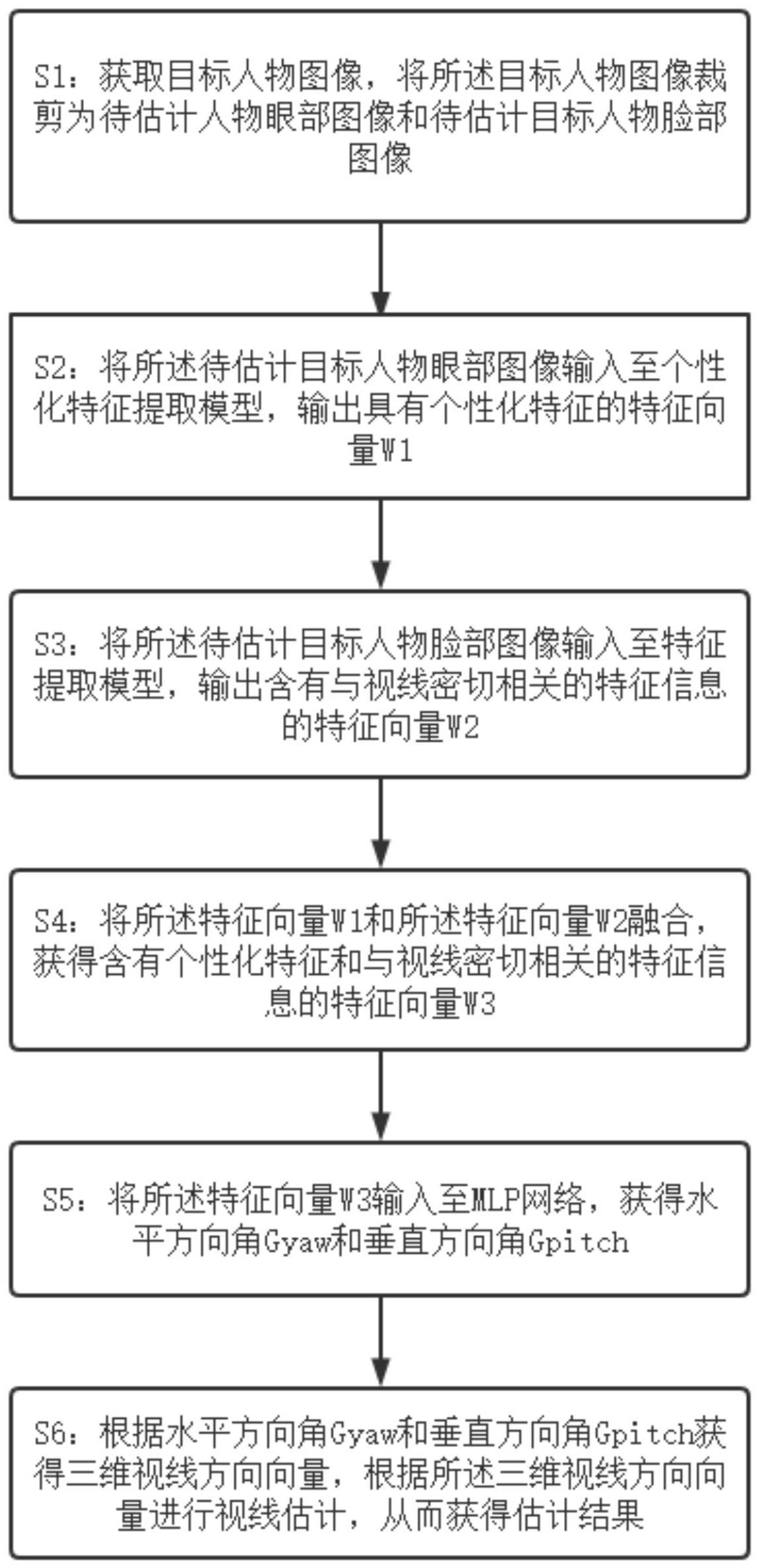
2、为了实现上述目的,本发明提供了一种视线估计方法,该方法包括以下步骤:
3、s1:获取目标人物图像,将所述目标人物图像裁剪为待估计目标人物眼部图像和待估计目标人物脸部图像;
4、s2:将所述待估计目标人物眼部图像输入至个性化特征提取模型,输出具有个性化特征的特征向量;
5、s3:将所述待估计目标人物脸部图像输入至特征提取模型,输出含有与视线密切相关的特征信息的特征向量;
6、s4:将所述特征向量和所述特征向量融合,获得含有个性化特征和与视线密切相关的特征信息的特征向量;
7、s5:将所述特征向量输入至mlp网络,获得水平方向角和垂直方向角;
8、s6:根据水平方向角和垂直方向角获得三维的视线方向向量,所述三维的视线方向向量通过下式确定:
9、
10、
11、
12、其中(,,)构成了所述三维的视线方向向量,根据所述三维的视线方向向量进行视线估计,从而获得估计结果。
13、进一步地,步骤s2中所述个性化特征提取模型通过如下方式确定:
14、s2.1: 构建个性化特征提取模型;
15、s2.2: 获取训练数据集a,所述训练数据集a包含大量不同人物不同头部姿态的高分辨率眼部图像,将所述训练数据集a按人物名字进行分组;
16、s2.3: 从所述训练数据集a中随机抽取一个人物的眼部主图像img1,再根据所述眼部主图像img1的人物名字,在其所在的分组中抽取一张与所述眼部主图像img1头部姿态相同但注视方向不同的眼部辅助图像img2,再在其他人物眼部分组图像中抽取一张与所述眼部主图像img1头部姿态不同但注视方向相同的眼部辅助图像img3;
17、s2.4: 将所述眼部主图像img1、眼部辅助图像img2和眼部辅助头像3分别裁剪为对应的左右眼部图像,再将所述对应的左右眼部图像通过非对称网络进行个性化特征提取,获得对应的12维的特征向量v1、v2和v3;
18、s2.5: 使用损失函数处理所述特征向量v1、v2和v3,以校正视线偏差,所述损失函数通过如下方式确定:
19、
20、
21、
22、其中为眼部主图像的个性化特征向量,为与主图相同人不同注视角度的个性化特征向量,为与主图不同人相同注视角度的个性化特征向量,代表同个人个性化信息优化的损失函数,不同人个性化信息优化的损失函数,为总个性化信息优化的损失函数;
23、s2.6: 重复步骤s2.1至s2.6,每次训练使用上一个损失函数优化下一个,获得最终的个性化特征提取模型。
24、进一步地,步骤s2.2中所述的训练数据集a通过如下方式获取:
25、获取eth-xgaze和gaze360训练数据集,所述eth-xgaze训练数据集包含110位人物的100万张不同头部姿态的高分辨率图像,所述gaze360训练数据集包含238位人物在不同环境下的大量运动图像;
26、对eth-xgaze和gaze360训练数据集图像的眼部进行裁剪,获得训练数据集a。
27、进一步地,步骤s2.4中所述的非对称网络包括:base-cnn、fc1和fc2,
28、所述base-cnn由6个卷积层依次连接构成,第一个卷积层的输入为左眼图像
29、或右眼图像,最后一个卷积层的输出连接fc1;
30、所述fc1为全连接层,输出为500,所述fc1的输入连接base-cnn中最后一个卷积层的输出,所述fc1的输出连接fc2的输入;
31、所述fc2为全连接层,输出为12,所述fc2的输入连接所述fc1的输出,所述fc2的输出即为一个12维的特征向量。
32、步骤s3中所述特征提取模型通过如下方式确定:
33、s3.1: 构建特征提取模型;
34、s3.2: 获取训练数据集b,所述训练数据集b包含大量不同人物不同头部姿态的高分辨率脸部图像,将所述训练数据集b按人物名字进行分组;
35、s3.3: 从训练数据集b中抽取一张与所述眼部主图像1同名字的第一脸部图像,将所述的第一脸部图像输入至特征提取网络backbone,获得一个对应的特征向量v4;
36、s3.4: 将所述的特征向量v4输入至sa-module逆向恢复第二脸部图像;
37、s3.5: 使用总损失函数优化v4,所述总损失函数通过如下方式确定:
38、
39、
40、
41、其中为生成的视线偏向角,为标签数据的视线偏向角,为所述第一脸部图像,为逆向生成的第二脸部图像,为视线回归的损失函数,为对抗逆向生成图的损失函数,为总个性化特征优化的损失函数,将这3个损失函数按不同权重加权得到特征提取模型的总损失函数,其中为权重超参数;
42、s3.6: 重复步骤s3.1至s3.5,每次使用上一个总损失函数优化下一个特征向量v4,最终获得特征提取模型。
43、步骤3.2中所述的训练数据集b通过如下方式获取:
44、获取eth-xgaze和gaze360训练数据集,所述eth-xgaze训练数据集包含110位人物的100万张不同头部姿态的高分辨率图像,所述gaze360训练数据集包含238位人物在不同环境下的大量运动图像;
45、对eth-xgaze和gaze360训练数据集图像的脸部进行裁剪,获得训练数据集b。
46、进一步地,步骤s3.3中所述特征提取网络backbone由resnet50构成。
47、进一步地,步骤s3.5中所述权重超参数,其中取值范围为1.7~2.3,取0.7~1.3,取1.3~1.8。
48、进一步地,所述权重超参数取2.0,权重超参数取1.0,权重超参数取1.5。
49、为了实现上述目的,本发明还提供了一种视线估计系统,包括:
50、获取模块:用于获取目标人物眼部图像和脸部图像;
51、个性化特征提取模块:用于将所述待估计目标人物眼部图像输入至个性化特征提取模型,输出具有个性化特征的特征向量;
52、特征提取模块:用于将所述待估计目标人物脸部图像输入至特征提取模型,输出含有与视线密切相关的特征信息的特征向量;
53、融合模块:用于将所述特征向量和所述特征向量融合,获得含有个性化特征和与视线密切相关的特征信息的特征向量;
54、识别模块:用于将所述特征向量输入至mlp网络,获得水平方向角和垂直方向角,根据水平方向角和垂直方向角获得三维的视线方向向量,所述三维的视线方向向量通过下式确定:
55、
56、
57、
58、其中(,,)构成了所述三维的视线方向向量,根据所述三维的视线方向向量进行视线估计,从而获得估计结果。
59、与现有技术相比,其有益效果在于:
60、本发明使用个性化特征提取模型对目标人物左右眼图像进行个性化特征提取,获得相应的特征向量w1,还使用特征提取模型对目标人物脸部图像进行特征提取,获得相应的特征向量w2,剔除了与视线无关的脸部特征而保留了与视线相关的特征,最后将特征向量w1和w2进行拼接融合,将融合后的特征向量w3输入mlp网络最终得到水平方向角gyaw和垂直方向角gpitch,可根据水平方向角和垂直方向角得到三维的视线方向向量,再根据三维视线方向向量进行视线估计,提高了视线估计模型的估计准确率;本发明还采用跨域训练模型的方法,由于不同数据集收集的环境和人物等信息差异较大,因此,本发明使用大数据集eth-xgaze和gaze360训练个性化特征提取模型和特征提取模型,提高模型在不同环境下的泛化能力,进一步提高了视线估计模型的估计准确率。
- 还没有人留言评论。精彩留言会获得点赞!