一种基于对比学习的文本摘要辅助生成方法
本发明属于深度学习,具体涉及一种文本摘要辅助生成方法。
背景技术:
1、文本摘要生成是一个相对来说比较主观的任务,因为每个源文本在事实上会有很多个优秀的参考摘要。但实际上现有的文本摘要数据集大多为单参考摘要数据集,并且这些参考摘要也并非是完全正确的,部分参考摘要同样面临完整性、流畅性等问题。这其中的主要原因在于数据集中的参考摘要也是人工撰写的,而人的思维是发散性的,对于同一篇文章不同撰写人的看法是不一样的,因此对于文本中重点信息的关注程度也不尽相同。此外,基于深度学习的文本摘要生成模型在训练过程中大多采用教师强迫训练机制和最大似然估计损失,使得模型倾向于生成低多样性的摘要,而训练与测试过程存在的曝光偏差问题和缺乏多参考摘要数据集问题更是加重了这一现象。
2、文献“liu y,liu p.simcls:a simple framework for contrastive learningof abstractive summarization[c]//proceedings of the 59th annual meeting ofthe association for computational linguistics and the 11th internationaljoint conference on natural language processing.2021:1065-1072.”公开了一种基于深度学习的文本摘要生成方法。该方法构建了一个本文摘要生成框架simcls,将文本生成问题表述为一个无参考文献的评价问题,有效改善了目前占主导地位的序列到序列学习框架所带来的学习目标和评价指标之间的差距。但是,该方法存在以下问题:该方法使用集束搜索算法进行解码生成,返回多条候选摘要时与源文本匹配程度最高的候选摘要却隐藏在高概率候选摘要之后,而与源文本语义匹配程度最高的候选摘要往往也并非是匹配指标最高的候选摘要。
技术实现思路
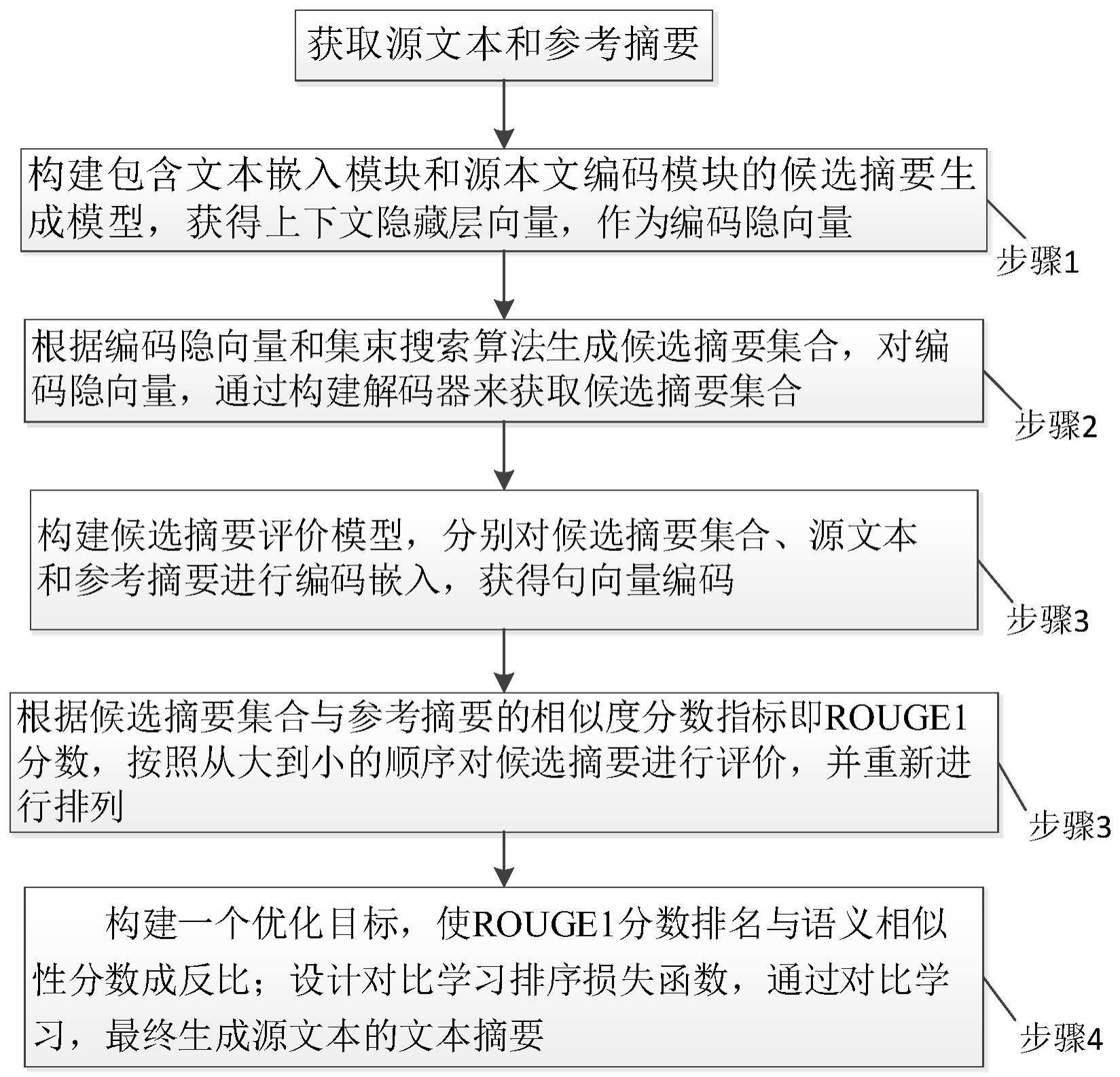
1、为了克服现有技术的不足,本发明提供了一种基于对比学习的文本摘要辅助生成方法,首先构建了能够从源文本中获得候选摘要集合的候选摘要生成模型,包含文本嵌入模块和源文本编码模块;文本嵌入模块将源文本分别进行词表分词、词嵌入和位置编码嵌入来获得源文本的嵌入向量;源文本编码模块则负责对源文本进行语义建模和特征提取,得到编码隐向量。然后,根据编码隐向量,基于自注意力结构,通过设置集束搜索算法的不同采样参数来生成多条候选摘要。接着,构建了候选摘要评价模型,采用候选摘要生成模型的编码器网络,分别对候选摘要集合、源文本和参考摘要进行编码嵌入,获得句向量编码。进一步,根据候选摘要集合与参考摘要的相似度分数指标,按照从大到小的顺序对候选摘要进行评价,并重新进行排列。最后,基于对比学习思想设计了一种新型排序损失函数,基于该损失函数对每一条候选摘要根据源文本进行语义相似度的有效评价,最终给出源文本最为合理的文本摘要。由于本发明中的候选摘要评价模型,以生成模型的编码器结构为基础,所设计的对比学习排序损失函数能够对每一条候选摘要根据源文本进行语义相似度的有效评价,有效缓解了高概率候选摘要与源本文的语义匹配度低的问题;同时候选摘要生成模型能有效扩展到当前主流的基于序列到序列生成结构的生成模型中,能够实现高效的文本摘要辅助生成。
2、本发明解决其技术问题所采用的技术方案包括如下步骤:
3、步骤1:构建候选摘要生成模型;
4、所构建的候选摘要生成模型由两部分组成,分别是文本嵌入模块和源文本编码模块;其中,文本嵌入模块将源文本分别进行词表分词、词嵌入和位置编码嵌入来获得源文本的嵌入向量;源文本编码模块则负责对源文本进行语义建模和特征提取;
5、步骤2:基于所构建的候选摘要生成模型,根据编码隐向量和集束搜索算法生成候选摘要集合;
6、对编码隐向量通过构建解码器来获取候选摘要集合;解码器包括带掩码的自注意力网络、交叉注意力网络和前馈神经网络;带掩码的自注意力网络用于将之前时间步的文本信息解码输出,并进行前向编码;交叉注意力网络根据编码隐向量的计算,让模型从源文本中解码生成输出;最后将输出送入前馈神经网络进行特征变换与抽取,从而生成候选摘要集合;
7、步骤3:构建候选摘要评价模型;
8、候选摘要评价模型采用候选摘要生成模型的编码器网络,分别对候选摘要集合、源文本和参考摘要进行编码嵌入,获得句向量编码;接着,根据候选摘要集合与参考摘要的相似度分数指标即rouge-1分数,按照从大到小的顺序对候选摘要进行评价,并重新进行排列;
9、步骤4:基于对比学习实现对文本摘要的辅助生成;
10、构建一个优化目标,该优化目标使rouge-1分数排名与语义相似性分数成反比;
11、设计对比学习排序损失函数,通过对比学习,最终生成源文本的文本摘要。
12、进一步地,所述步骤1具体为:
13、文本嵌入模块包含两个部分,分别为词嵌入层和位置编码嵌入层;词嵌入层用于将输入文本根据上下文动态嵌入,得到具有上下文特征的动态词向量,其中词向量的维度大小为d;位置编码嵌入层为带可学习参数的编码嵌入,输入文本的当前位置,经过位置编码层得到位置编码向量,位置编码向量的维度大小同样为d;对于源文本嵌入,嵌入获得的动态词向量xs用如下公式描述:
14、xs=pe(d)+we(d) (1)
15、其中,we为词嵌入,pe为位置编码嵌入,d为源文本;词嵌入层由模型在预训练过程中得到,通过在预训练语料上进行的预训练能使模型根据上下文完成对输入的动态嵌入;
16、源文本编码模块由n层子编码器组成,每层子编码器都包含两个子层:第一级子层是基于自注意力机制的神经网络,第二级子层是基于全连接的前馈神经网络,共同构成了一个完整的子编码系统;在每一子层内部,通过残差连接来提高信息流通性,并且通过层归一化处理确保前向和反向传播的稳定性;为了使每个子层之间和每个子编码器之间实现残差连接,模型每一子层与子编码器的输出均为维度大小为d的向量;源文本编码模块对输入文本进行特征提取,经过多个子编码器的语义编码,得到上下文隐藏层向量。
17、优选地,所述步骤2具体为:
18、将候选摘要生成模型获得的上下文隐藏层向量作为编码隐向量,根据编码隐向量和集束搜索算法生成候选摘要集合,对编码隐向量通过构建解码器来获取候选摘要集合;
19、解码器包含n个重复堆叠的子解码器;每个子解码器共包含四个子层,分别为带掩码的自注意力网络、两个相同的交叉注意力网络和一个前馈神经网络;为了在每个子层内实现残差连接,所有子层的输出均为维度大小为d的向量;
20、带掩码的自注意力网络用于将之前时间步的文本信息解码输出,并进行前向编码;假设当前时间步为t,首先利用教师强迫训练机制将之前时间步(t-1)的生成结果作为当前时间步的输入,经过嵌入层得到动态词向量yt-1;该模块中当前时间步的文本只能关注到之前时间步的文本信息。具体用如下公式描述:
21、yt-1=ln(yt-1+maskedselfattention(yt-1)) (2)
22、其中,maskedselfattention为带掩码的自注意力网络,ln为层归一化操作;
23、交叉注意力网络根据编码隐向量的计算,让模型从源文本中解码生成输出;最后将输出送入前馈神经网络进行特征变换与抽取,从而生成候选摘要集合c。
24、优选地,所述步骤3具体为:
25、候选摘要评价模型采用候选摘要生成模型的编码器网络,分别对候选摘要集合c、源文本d和参考摘要r进行编码嵌入,获得句向量编码和具体用如下公式描述:
26、
27、其中l为候选摘要总数,为候选摘要的最大序列长度,d为隐藏层大小;
28、在获得候选摘要集合句向量编码后根据候选摘要集合c与参考摘要r的rouge-1分数指标对按照从大到小的顺序重新进行排列,具体用如下公式描述:
29、
30、其中,由此获得顺序排列的候选摘要句向量源文本句向量和参考摘要句向量
31、优选地,所述步骤4具体为:
32、在进行对比学习训练时首先获得了顺序排列的候选摘要句向量源文本句向量和参考摘要句向量它们的维度均为序列长度×隐藏层大小;
33、经过first-last平均池化句向量操作,将候选摘要句向量由变换至每一个候选摘要句向量由变换至源文本句向量由变换至参考摘要句向量由变换至
34、所设计的对比学习排序损失函数,用如下公式描述:
35、
36、其中,i与j分别为候选摘要集合索引;γ1、γ2和γ3分别为不同前后位置候选摘要的参数,其中γ1=20e(l-i)×0.1,γ2=20e(j-i)×0.1,γ3=20e(i-j)×0.1,l为候选摘要总数;
37、式(5)中损失函数共分为三部分,第一部分计算的是候选摘要与源文本和候选摘要与参考摘要的余弦相似度,优化目标为即希望参考摘要相比候选摘要与源文本在语义上更为相似,参数γ1是为了对排名靠后的候选摘要实施更大的惩罚;第二部分和第三部分计算的是候选摘要与源文本和候选摘要与源文本的余弦相似度,优化目标为即希望候选摘要相比候选摘要与源文本在语义上更为相似,参数γ2和γ3同样是为了对排名靠后的候选摘要实施更大的惩罚;
38、基于该损失函数能够对每一条候选摘要根据源文本进行语义相似度的有效评价,并最终给出源文本最为合理的文本摘要。
39、本发明的有益效果如下:
40、本发明构建了包含候选摘要生成模型和候选摘要评价模型两部分的文本摘要生成框架。生成模型包含文本嵌入模块和源文本编码模块,基于自注意力结构,通过设置集束搜索算法的不同采样参数来生成多条候选摘要。评价模型以生成模型的编码器结构为基础,并基于对比学习思想设计了一种新型排序损失函数,基于该损失函数能够对每一条候选摘要根据源文本进行语义相似度的有效评价。在公开的中文摘要数据集lcsts上,本发明生成文本摘要的rouge-1分数相比于文献方法提高了2.16,在语义相似度指标bert-score上提高了2.12。此外,本发明中的候选摘要生成模型基于序列到序列的生成结构,能有效扩展到当前主流的基于序列到序列生成结构的生成模型中,在其基础上获得更加优秀的生成摘要。
- 还没有人留言评论。精彩留言会获得点赞!