一种并发的内存数据库分裂的方法
本发明涉及数据库,尤其涉及一种并发的内存数据库分裂的方法。
背景技术:
1、随着物联网、云计算、大数据等新兴信息技术的飞速发展,数据量呈指数增长趋势,到2020年数据总量已突破40zb。在如此海量的数据中快速准确的检索出所查询的数据始终是数据库领域研究的焦点。创建高性能的数据库索引就是其中一种重要技术,自适应索引技术的出现,尤其是数据库分裂技术,克服了传统索引技术存在的不足,其索引的构建不需要提前、不需要决策、不需要为全部的数据构建,而是依赖于动态变化的工作负载,按需以自适应的、连续的、增量的、部分的方式维护索引物理设计的变化。
2、数据库分裂技术是最早引入的自适应索引技术,该技术的主要概念是在查询执行的过程中自适应的、增量的创建和维护索引,将每个传入请求视为优化索引结构的建议。分裂过程非常类似于快速排序,其中每个查询在一个分区上执行,并根据查询谓词对元组进行重组。通过这种方式,索引创建过程分布在多个后续查询上,每个查询都能从前面的查询中受益。
3、s.idreos等人在cidr 2007上发布的论文“database cracking”上首次提出了标准数据库分裂算法,标准数据库分裂算法中实现分裂索引的数据结构为avl-tree,其存在以下性能瓶颈:分裂索引avl-tree虽然驻留在内存中,在查询时驱动数据库分裂,但avl-tree并不是针对内存进行优化的索引,其对于范围查询而言缓存效率低;在数据库分裂算法的每次查询中均需要细化更新索引,avl-tree大量的平衡操作带来较大的开销;在数据集增大或查询工作负载变化时,该方法的查询效率并不高,这会对数据库分裂的整体性能产生较大的影响。
4、goetz graefe等人在pvldb2012上发布的论文“concurrency control foradaptive indexing”上首次对标准数据库分裂的并发算法psc(parallel standardcracking)做了详细介绍,其主要通过对标准数据库分裂算法中使用的分裂列和avl索引加解闩锁来实现并发控制。psc通过对数据库分裂相关的数据结构加解锁或者并发分块来实现数据库分裂的并发算法,但这种实现方式带来了较大的锁的竞争和加解锁开销,成为了数据库分裂并发算法的主要瓶颈。
5、此外,数据库分裂算法应该赶上内存索引技术的发展,随着越来越优的内存数据库索引的出现,如art索引等,与这些索引相比,数据库分裂算法的查询效率仍有待提高。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种并发的内存数据库分裂的方法,一种缓存效率和查询效率更好的内存数据库索引去驱动数据库分裂,将内存数据库索引与数据库分裂技术相结合,以对数据库分裂算法进行优化,同时,基于优化算法提出更优的数据库分裂的并发策略。
2、为解决上述技术问题,本发明所采取的技术方案是:
3、一种并发的内存数据库分裂的方法,针对art索引进行改进,得到一种支持数据库分裂技术的新的增量自适应基数树索引结构,即iart索引;并在iart索引的基础上提出基于增量自适应基数树的分裂算法,即iartc算法,iartc算法使用iart索引作为分裂索引来驱动数据库分裂;同时基于iartc算法得到一种新的数据库分裂并发算法,即piartc算法,piartc算法通过乐观锁耦合的并发策略来对iart索引上的节点进行加解锁控制,以实现并发的分裂和索引的更新,使其在并发执行过程中保持小的锁定粒度;
4、所述iart索引在art索引基础上根据不同的内部节点类型分别添加parent、minkey、maxkey以及多级支持,使得能够通过查询iart索引获得分裂的枢轴分区的上下界,并将其作为算法中的分裂索引去驱动数据库分裂;
5、所述iartc算法包括索引枢轴分区、重组分裂列、更新索引、查询结果四个步骤,其中索引枢轴分区和更新索引是在art索引的基础上对原标准数据库分裂算法做出改进。
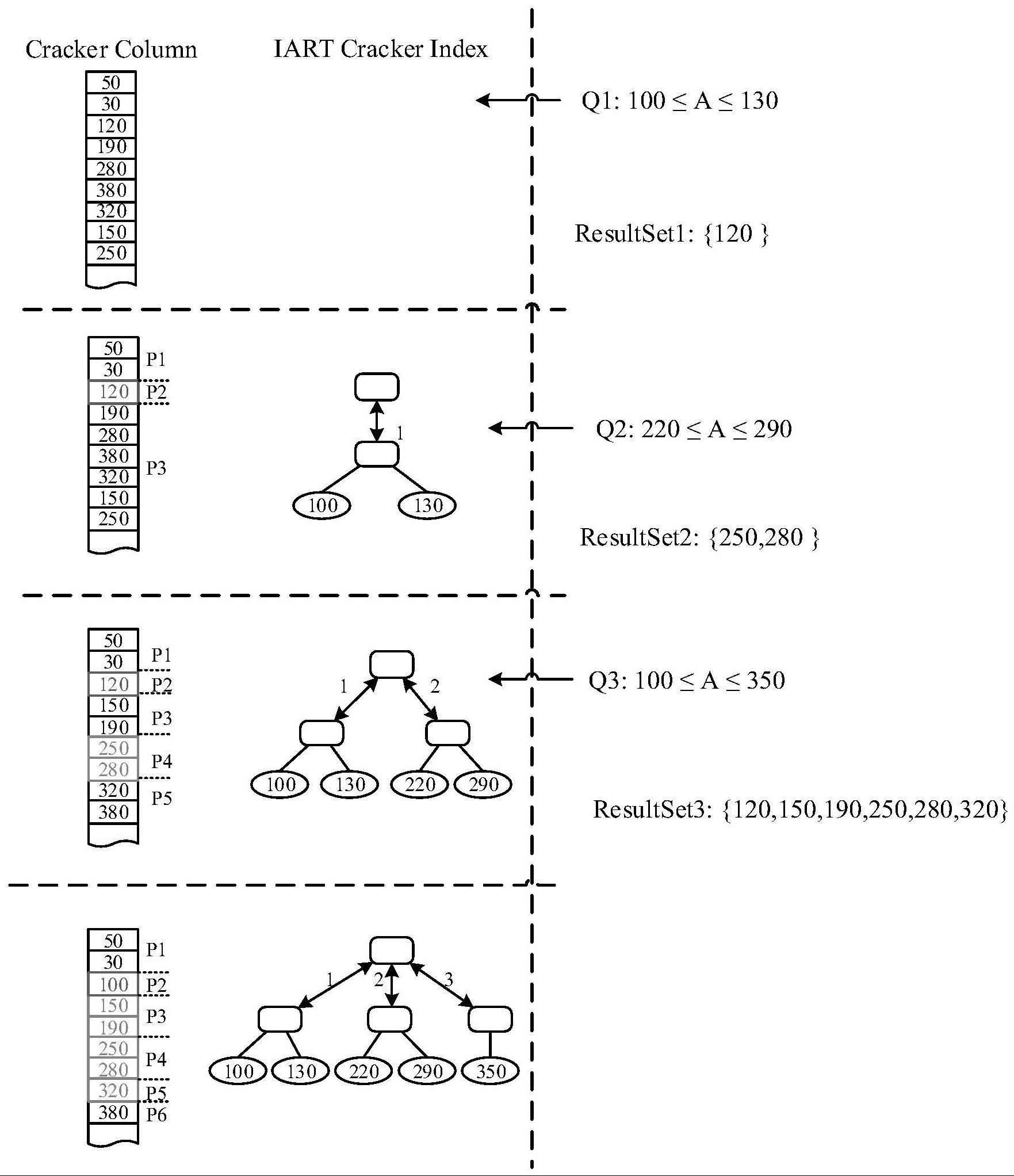
6、进一步地,所述iart索引内部node4类型节点的数据结构如下:
7、首先为iart索引的node4类型内部节点增添一个parent指针,代表指向其父亲节点的指针;如果当前查找的键不存在,需要到其父亲节点或者祖先节点中继续查找键的上下界,这在iart其他类型的内部节点中也是必须的;然后为node4类型节点添加多级支持;
8、进一步地,所述iart索引内部node16类型节点的数据结构如下:
9、为node16类型节点添加指向父亲节点的指针和多级支持。
10、进一步地,所述iart索引内部node48类型节点的数据结构如下:
11、为node48类型节点添加指向父亲节点的指针,同时添加两个附加的key,即maxkey和minkey;其中maxkey表示当前node48内部所存储key的最大值,minkey表示当前node48内部所存储key的最小值。
12、进一步地,所述iart索引内部node256类型节点的数据结构如下:
13、为node256节点添加指向父亲节点的指针parent、node256内部存储key的最大值maxkey以及node256内部存储key的最小值minkey。
14、进一步地,所述iartc算法中的索引枢轴分区的具体实现如下:
15、分为查询成功和查询失败两种情况:
16、如果范围查询的值在iart索引上已经存在,则直接返回当前值在分裂列上的位置,并且无需其他分裂操作;
17、如果范围查询的值不在iart索引上,则需要给出当前值所要查找的枢轴分区的上界和下界,其分为以下三个方面:
18、(a)当使用范围查询的边界值在iart索引上搜索,遍历至叶子节点匹配失败时,如果当前查询的值小于当前叶子节点的值,则当前查询值的枢轴分区的上界为该叶子节点的值,其下界为该节点左侧所有叶子节点中的最大值。如果当前查询的值大于当前叶子节点的值,当前查询值的枢轴分区下界为该叶子节点的值,上界为该节点右侧所有叶子节点中的最小值。
19、(b)当使用范围查询的边界值在iart索引上搜索,遍历发生和内部节点前缀不匹配的情况,需要根据前缀与当前值的大小做不同处理;
20、如果当前查询的值小于当前内部节点前缀的值,则当前查询值的枢轴分区的上界为当前内部节点的最小值,其下界为该节点左侧所有叶子节点中的最大值。
21、如果当前查询的值大于当前内部节点前缀的值,则当前查询值的枢轴分区的下界为当前内部节点的最大值,其上界为该节点右侧所有叶子节点中的最小值。
22、(c)当使用范围查询的值在iart索引上搜索的时候,查询找到的值为空值的情况,则需要根据父亲节点的类型去做不同的处理,具体如下:
23、如果父亲节点为node4类型节点,首先根据当前查询的值和父亲节点里的值进行对比;当前查询的值小于父亲节点保存的最小值时,则当前所查询值的枢轴分区的下界为当前层叶子节点的最小值,上界为该节点左侧所有叶子节点中的最大值;当前查询的值大于父亲节点保存的最大值时,则当前所查询值的枢轴分区的下界为当前层叶子节点的最大值,上界为该节点右侧所有叶子节点中的最小值;如果正好介于父亲节点最大值与最小值中间,则当前所查询值的枢轴分区的下界为该节点左侧所有叶子节点中的最大值,上界为该节点右侧所有叶子节点中的最小值;
24、如果父亲节点为node16类型节点,查找方法与node4类型内部节点相同;
25、如果父亲节点为node48类型的内部节点,由于node48类型节点结构的特殊性,首先需要得到node48类型节点保存的最大值和最小值;之后根据当前查询的值和查找到的最大值、最小值进行比较;如果当前查询的值大于node48类型节点的最大值,则当前查询值的枢轴分区的下界为当前层所有叶子节点中的最大值,上界为该节点右侧所有叶子节点中的最小值;如果当前查询值小于node48类型节点的最大值,则当前查询值的枢轴分区的下界为当前层所有节点中的最小值,上界为该节点左侧所有叶子节点中的最大值;与node4类型节点不同的是,当前查询的值位于最大值和最小值中间时,仍然需要遍历去查找枢轴分区的上界和下界所在的位置;
26、如果父亲节点为node256类型的内部节点,枢轴分区的查找与node48类型节点相同。
27、进一步地,所述iartc算法的执行过程为:针对范围查询[low,high],首先检测是否为第一次查询,即当iart索引为空的时候,需要对iartc算法中最重要的两大数据结构进行初始化,完成iart索引的创建以及分裂列的复制;分别根据范围查询的下界low和上界high在iart索引上搜索对应的枢轴分区,每个枢轴分区由一个数值对进行标识;根据查询的结果在分裂列上执行不同的分裂算法;当索引查询后的上下界的分区属于同一个枢轴分区时,执行三分裂算法;当索引查询和的上下界分别属于两个不同的枢轴分区时,分别执行两个二分裂算法;然后重组分裂列中的元素并返回枢轴分区的位置;之后更新iart索引,将查询的上下界以及对应的枢轴分区的位置插入到iart索引中;最后在分裂列上进行扫描,将范围查询的结果返回。
28、进一步地,所述piartc算法首先执行并发查询iart索引来获得要分裂的枢轴分区;同单线程的iartc算法一样,分为三个方面:在iart索引上查找匹配前缀失败的情况、遍历查找为null的情况、遍历查找为叶子节点的情况;之后在每个部分均执行相同的操作,即在iart索引上并发的搜索对应的枢轴分区后执行枢轴分区的并发分裂,之后自适应并发地构建iart索引,以加速并发查询的执行。
29、进一步地,piartc算法并发执行范围查询的基本流程如下所述:
30、首先,当范围查询的某一枢轴执行并发搜索时,使用乐观锁耦合并发策略olc获得根节点上的读锁;在执行iart索引并发搜索枢轴分区的过程中仍需要根据前缀与枢轴的大小做不同处理,同时在查找当前节点的最小叶子节点、查找当前节点的最大叶子节点、查找该节点左侧所有叶子节点中的最大值以及查找该节点右侧所有叶子节点中的最小值中也要使用乐观锁耦合并发策略遍历来保证获得正确的未加锁的枢轴分区;之后执行枢轴分区的分裂以及iart索引的更新;
31、当发生前缀不匹配时,不仅会影响到当前节点,还会对父亲节点的指针进行修改。因此,需要将当前节点和父亲节点上的读锁同时更新为写锁,并在iart索引完成更新后对相应的节点进行解锁;
32、当枢轴和当前iart索引内部节点的前缀匹配成功时,需要获得iart索引的下层节点,同时避免读到无效的指针导致程序崩溃;
33、根据父亲节点的类型使用乐观锁耦合并发策略查找相应的枢轴分区;如果是第一次查询,当前仅有一个线程对整个分裂列执行分裂操作;由于当前iart索引中无叶子节点存在,因此只需要将根节点的锁更新为写锁,以防止其他线程对该分区加锁执行分裂;
34、之后,完成iart索引的更新并解锁,当不是第一次查询时,需要根据是否要对iart索引的节点扩展而对相应节点进行加锁以完成iart索引的更新;当父亲节点安全时,即不会对父亲节点修改,则释放父亲节点的锁,继续遍历下一层节点;
35、如果当前查询的枢轴和当前查询到的叶子节点匹配,则无需执行任何操作返回空值即可,否则仍然需要根据当前查询的枢轴和当前叶子节点的大小关系去查找正确的枢轴分区。
36、执行分裂列的分裂以及使用乐观锁耦合并发策略保证当前iart索引节点的竖向分裂,以完成索引的更新。
37、采用上述技术方案所产生的有益效果在于:本发明提供的并发的内存数据库分裂的方法,首先针对art内部节点优化提出了一种新的iart索引结构,使其可以作为数据库分裂算法的分裂索引。在此基础上,提出了一种新的数据库分裂算法,即iatrc算法,其主要通过iart索引作为分裂索引去驱动数据库分裂,并在分裂过程中根据索引枢轴分区的不同去选择不同的分裂算法。在多核并行的环境下,基于iartc算法提出了一种新的数据库分裂并发算法,即piartc算法,该算法通过乐观锁耦合的并发策略来对iart索引上的节点进行加解锁控制,以实现并发的分裂和索引的更新,使其在并发执行过程中保持较小的锁定粒度,这大大减少了线程之间冲突的概率。
38、与现有算法相比,在面对动态环境以及大规模数据集查询的情况下,本发明提出的两种自适应索引在单核和多核系统中均表现出良好的查询性能,且仍保持原始数据库分裂算法轻量级的特性。相比于标准数据库分裂算法,随机工作负载模式下单线程中iartc算法查询响应性能提升了30.8%,缓存未命中减少了37.1%,多线程下piartc算法的查询相应性能提升了44%,8个线程的加速比达到2.86。两种算法的鲁棒性也获得了提升。
- 还没有人留言评论。精彩留言会获得点赞!