一种文本情感分析方法、装置、电子设备及存储介质与流程
本发明涉及自然语言处理,尤其涉及一种文本情感分析方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、随着互联网技术的发展,以及人工智能技术的日益成熟,越来越多的公司倾向于收集用户反馈的服务信息,比如,用户对客服的服务质量或满意度的文本信息等,以改善客户体验或产品设计等。然后,面临的一个主要挑战就是如何从大量的服务信息中提取出有用的信息,而情感分析就是解决该问题的关键手段,情感分析可以从服务信息中识别出有用的价值信息,特别是基于属性级的细粒度情感分析受到了广泛关注。
2、相关技术中,可以通过自动语音识别技术(asr,automatic speech recognition)对服务系统(比如10000号客服系统等)中的服务信息经过转换后得到海量对话的文本数据,但是,由于文本数据语法结构的复杂性,以及属性表达的多样性,导致文本情感分析不准确。
3、因此,如何精准的从这些海量的文本数据中分析用户对客服的服务质量或者用户对企业现有产品的满意度,是目前亟待解决的问题。
技术实现思路
1、本发明提供一种文本情感分析方法、装置、电子设备及计算机可读存储介质,以至少解决相关技术中由于文本数据语法结构的复杂性,以及属性表达的多样性,导致文本情感分析的准确性降低的技术问题。本发明的技术方案如下:
2、根据本发明实施例的第一方面,提供一种文本情感分析方法,包括:
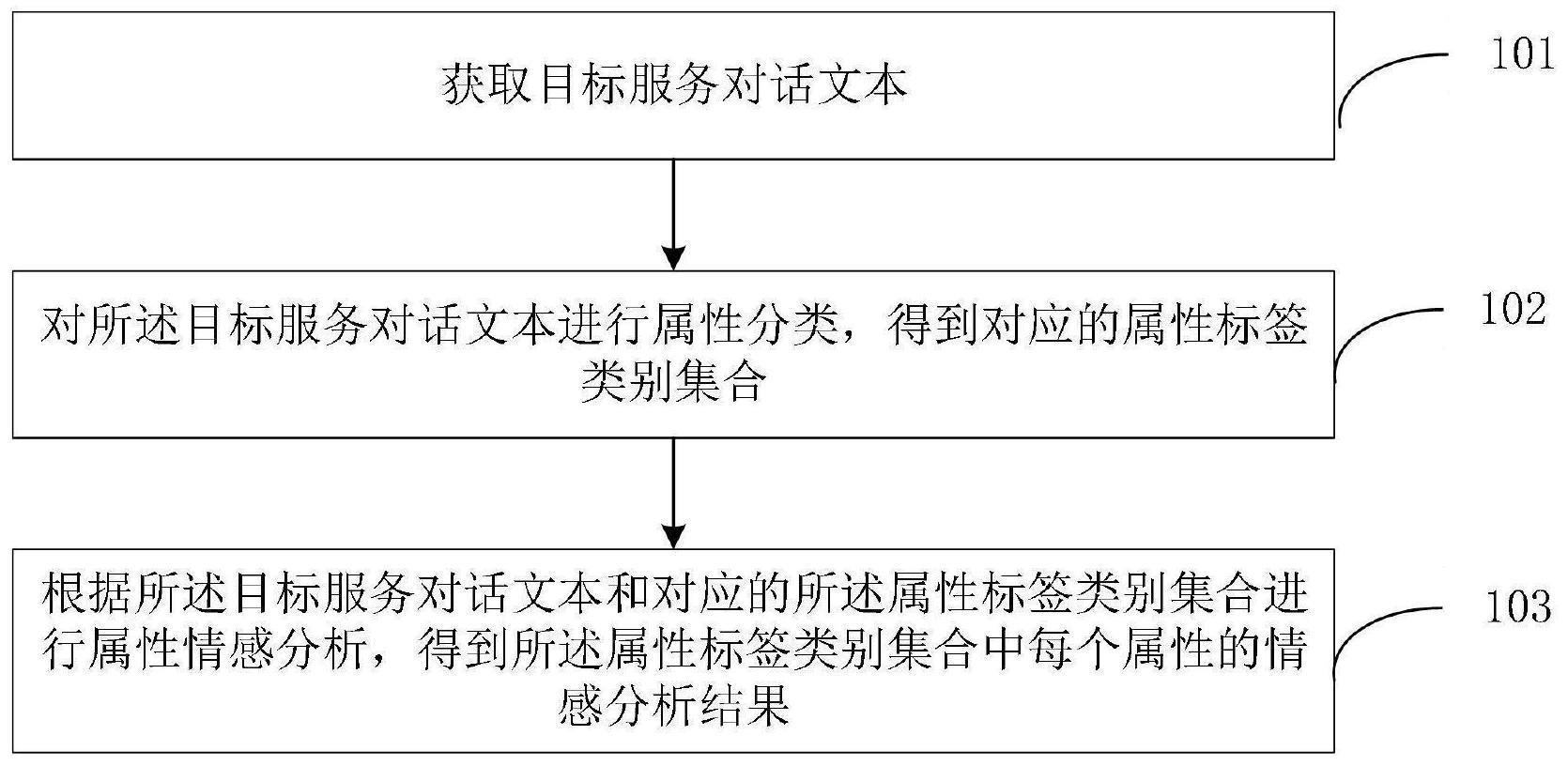
3、获取目标服务对话文本;
4、对所述目标服务对话文本进行属性分类,得到对应的属性标签类别集合;
5、根据所述目标服务对话文本和对应的所述属性标签类别集合进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果。
6、可选的,所述对所述目标服务对话文本进行属性分类,得到对应的属性标签类别集合,包括:
7、对所述目标服务对话文本进行分词,得到有序集合;
8、调用属性识别模型对所述有序集合进行属性分类,得到所述目标服务对话文本的属性标签类别集合。
9、可选的,在对所述目标服务对话文本进行属性分类之前,所述方法还包括:预先训练所述属性识别模型:
10、获取第一训练集,所述第一训练集包括多条历史服务对话文本,以及每条历史服务对话文本对应的属性标签类别集合;
11、分别提取所述每条历史服务对话文本中的语言文本特征和卷积文本特征;
12、对所述语言文本特征和卷积文本特征进行特征融合,得到融合后的特征向量;
13、将所述每条历史服务对话文本中的所述特征向量通过全连接层后利用多标签分类模型进行训练,在训练过程中,将所述每条历史服务对话文本的训练结果与对应的所述属性标签类别集合进行比较,根据比较结果的差距计算损失值,基于所述损失值,通过反向传播机制更新所述多标签分类模型的参数,经过多次迭代,直至所述多标签分类模型收敛,得到训练好的多标签分类模型,并将所述训练好的多标签分类模型作为所述属性识别模型。
14、可选的,所述分别提取所述每条历史服务对话文本中的语言文本特征和卷积文本特征,包括:
15、将每条所述历史服务对话文本分别输入到预训练语言模型bert和卷积神经网络cnn模型进行特征提取,得到提取的语言文本特征和卷积文本特征。
16、可选的,根据所述目标服务对话文本和对应的所述属性标签类别集合进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果,包括:
17、在所述属性标签类别集合为非空时,将所述属性标签类别集合与所述目标服务对话文本进行拼接,得到属性标签类别列表;
18、对所述属性标签类别列表进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果。
19、可选的,将所述属性标签类别集合与所述目标服务对话文本进行拼接,得到属性标签类别列表,包括:
20、对所述属性标签类别集合进行分词,得到有序的词语集合;
21、将所述有序的词语集合中的每个词语分别与所述有序集合依次进行拼接,得到属性标签类别列表。
22、可选的,所述对所述属性标签类别列表进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果,包括:
23、调用属性情感分析模型对所述属性标签类别列表中的每个属性标签依次进行属性情感分析,得到所述属性标签类别列表中每个属性对应的情感类别以及对应的概率值。
24、可选的,所述方法还包括:预先训练所述属性情感分析模型,包括:
25、获取第二训练集,所述第二训练集包括多条历史服务对话文本,以及每条历史服务对话文本对应的属性标签;
26、将每条所述历史服务对话文本和对应的属性标签输入到预训练语言模型bert进行训练,得到词嵌入向量;
27、将所述词嵌入向量输入到全连接层及遗漏层,得到向量分数对;
28、采用归一化指数函数对所述向量分数进行处理,得到每个属性标签的概率值:
29、选取最大的概率值作为属性标签的情感类别;
30、将每个属性标签的概率值,以及对应的情感类别作为所述属性情感分析模型的训练结果。
31、可选的,所述方法还包括:
32、获取所述属性标签类别列表的长度;
33、判断当前长度是否达到所述属性标签类别列表的长度;
34、在没有达到所述属性标签类别列表的长度时,执行所述调用属性情感分析模型对所述属性标签类别列表中的每个属性标签依次进行属性情感分析,得到所述属性标签类别列表中每个属性对应的情感类别以及对应的概率值的步骤;或者,
35、在达到所述属性标签类别列表的长度时,输出所述目标服务对话文本中所有属性对应的情感类别以及对应的概率值。
36、根据本发明实施例的第二方面,提供一种文本情感分析装置,包括:
37、第一获取模块,用于获取目标服务对话文本;
38、属性分类模块,用于对所述目标服务对话文本进行属性分类,得到对应的属性标签类别集合;
39、情感分析模块,用于根据所述目标服务对话文本和对应的所述属性标签类别集合进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果。
40、可选的,所述属性分类模块包括:
41、第一分词模块,用于对所述目标服务对话文本进行分词,得到有序集合;
42、第一调用模块,用于调用属性识别模型对所述有序集合进行属性分类,得到所述目标服务对话文本的属性标签类别集合。
43、可选的,所述装置还包括:
44、第二获取模块,用于获取第一训练集,所述第一训练集包括多条历史服务对话文本,以及每条历史服务对话文本对应的属性标签类别集合;
45、提取模块,用于分别提取所述每条历史服务对话文本中的语言文本特征和卷积文本特征;
46、融合模块,用于对所述语言文本特征和卷积文本特征进行特征融合,得到融合后的特征向量;
47、第一训练模块,用于将所述每条历史服务对话文本中的所述特征向量通过全连接层后利用多标签分类模型进行训练,在训练过程中,将所述每条历史服务对话文本的训练结果与对应的所述属性标签类别集合进行比较,根据比较结果的差距计算损失值,基于所述损失值,通过反向传播机制更新所述多标签分类模型的参数,经过多次迭代,直至所述多标签分类模型收敛,得到训练好的多标签分类模型,并将所述训练好的多标签分类模型作为所述属性识别模型。
48、可选的,所述提取模块,具体用于将每条所述历史服务对话文本分别输入到预训练语言模型和卷积神经网络模型进行特征提取,得到提取的语言文本特征和卷积文本特征。
49、可选的,所述情感分析模块包括:
50、拼接模块,用于在所述属性标签类别集合为非空时,将所述属性标签类别集合与所述目标服务对话文本进行拼接,得到属性标签类别列表;
51、属性情感分析模块,用于对所述属性标签类别列表进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果。
52、可选的,所述拼接模块包括:
53、第二分词模块,用于在所述属性标签类别集合为非空时,对所述属性标签类别集合进行分词,得到有序的词语集合;
54、词语拼接模块,用于将所述有序的词语集合中的每个词语分别与所述有序集合依次进行拼接,得到属性标签类别列表。
55、可选的,所述属性情感分析模块,具体用于调用属性情感分析模型对所述属性标签类别列表中的每个属性标签依次进行属性情感分析,得到所述属性标签类别列表中每个属性对应的情感类别以及对应的概率值。
56、可选的,所述装置还包括:预先训练所述属性情感分析模型,包括:
57、第三获取模块,用于获取第二训练集,所述第二训练集包括多条历史服务对话文本,以及每条历史服务对话文本对应的属性标签;
58、第二训练模块,用于将每条所述历史服务对话文本和对应的属性标签输入到预训练语言模型bert进行训练,得到词嵌入向量;
59、层级处理模块,用于将所述词嵌入向量输入到全连接层及遗漏层,得到向量分数对;
60、归一化处理模块,用于采用归一化指数函数对所述向量分数进行处理,得到每个属性标签的概率值:
61、选取模块,用于选取最大的概率值作为属性标签的情感类别:
62、确定模块,用于将每个属性标签的概率值,以及对应的情感类别作为所述属性情感分析模型的训练结果。
63、可选的,所述装置还包括:
64、第二获取模块,用于获取所述属性标签类别列表的长度;
65、第一判断模块,用于判断当前长度是否达到所述属性标签类别列表的长度;
66、所述属性情感分析模块,还用于在所述第一判断模块判定没有达到所述属性标签类别列表的长度时,执行所述调用属性情感分析模型对所述属性标签类别列表中的每个属性标签依次进行属性情感分析,得到所述属性标签类别列表中每个属性对应的情感类别以及对应的概率值的步骤;或者,
67、输出模块,用于在所述第一判断模块判定达到所述属性标签类别列表的长度时,输出所述目标服务对话文本的所有属性对应的情感类别以及对应的概率值。
68、根据本发明实施例的第三方面,提供一种电子设备,包括:
69、处理器;
70、用于存储所述处理器可执行指令的存储器;
71、其中,所述处理器被配置为执行所述指令,以实现如上所述的文本情感分析方法。
72、根据本发明实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如上所述的文本情感分析方法。
73、根据本发明实施例的第五方面,提供一种计算机程序产品,包括计算机程序或指令,所述计算机程序或指令被电子设备的处理器执行时实现如上所述的文本情感分析方法。
74、本发明的实施例提供的技术方案至少带来以下有益效果:
75、本发明实施例中,对获取的目标服务对话文本进行属性分类,得到对应的属性标签类别集合;根据所述目标服务对话文本和对应的所述属性标签类别集合进行属性情感分析,得到所述属性标签类别集合中每个属性的情感分析结果。也就是说,本发明实施例对目标服务对话文本按照属性进行分类,基于分类得到的属性标签类别集合,结合该对话文本进行属性情感分析,能够有针对性的对相关的多标签属性特征进行情感分析,提高了文本情感分析的准确性;有助于优化产品,提高客服的服务质量。
76、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!