面向持续学习的自适应平衡批归一化方法及系统
本发明涉及机器学习,具体涉及一种面向持续学习的自适应平衡批归一化方法及系统。
背景技术:
1、持续学习是机器学习领域中最重要的子领域之一,其旨在从一连串相继到达的任务中获取、积累并利用知识,其中对旧任务的训练样本的访问是受限的,因此模型获得的知识往往与最近的任务更加相关。这种近因偏差,也被称为灾难性遗忘,通常归因于深度神经网络中基于梯度的优化方法的性质。现有的持续学习方法大都是通过矫正网络的可学习参数的梯度来解决灾难性遗忘。然而,归一化层作为深度神经网络的一个重要组成部分采用了特殊的更新规则,这些规则只是部分基于梯度的,它们在持续学习中的近因偏差仍有待解决。归一化层通常包括仿射变换参数和统计参数,其目标是通过归一化内部表征从而加速收敛并稳定训练。由于这两种参数分别利用了当前观察到的训练样本的梯度和统计量(均值和方差)来更新,所以归一化层需要专门的策略来克服持续学习中的近因偏差。最近的一些技术在单任务上对统计量的贡献上进行了平衡,但有效性和通用性有限。例如,最常用的批归一化(bn)技术使用指数移动平均(exponential moving average,ema)来计算统计每个输入数据批次的群体统计,并用于测试阶段的归一化;这种方式一定程度上保留了历史信息,但由于bn对旧任务的统计权重可证地随着任务的增加而指数衰减,所以不可避免地会带来近因偏差。
2、近年有学者提出面向持续学习的归一化技术改进,通过引入组归一化(gn)技术来降低任务间统计差异,但仍然无法克服近因偏差以及数据分布切换带来的训练不稳定的问题。
3、批归一化(bn)是深度神经网络架构中最常用的归一化方法。在训练阶段,对于一个包含批次维度、通道维度、特征维度的内部表征(即神经元激活),bn计算批次维度、特征维度的统计量(均值,方差),然后对内部表征做归一化,从而提高梯度优化的稳定性。为了使测试阶段输入样本的归一化与同一批次的其他样本独立,bn需要累计训练阶段每一批次内部表征的统计量,计算它们的ema,用于测试阶段的样本归一化。这一过程在一定程度上保留了历史信息,使得bn在持续学习中优于许多其他替代方案。但由于bn对旧任务的统计权重可证地随着任务的增加而指数衰减,使其无法平衡任务的统计权重,从而不可避免地带来近因偏差。
4、累计移动平均的批归一化变种,该变种基于bn将原本ema统计更新方式替换为累计移动平均(cumulative moving average,cma),即强制性地令每一批次的统计具有相同的权重,此时任务的统计权重可以得到平衡。然而,过去的统计相对于当前模型往往是过时的,这种非自适应的平衡方法往往会影响网络训练的稳定性,最终对性能产生负面的影响。
5、组归一化(gn)是另外一种用于单任务学习的归一化方法,它是层归一化(layernormalization,ln)与实例归一化(instance normalization,in)的推广版本。相比于bn对批次维度归一化,gn的归一化不包含批次维度。它将通道维度划分成g个组,接着对每个组内的通道维度和特征维度归一化,最终合并每个组得到输出表征。当g等于1时,gn退化为ln;当g与通道维相等时,gn退化为in。gn(ln,in)相较于bn的优势在于训练与测试的行为一致,因此只包含仿射变换参数,不需要引入由ema或cma更新的统计参数。然而这也使得这类方法更容易受到梯度优化性质的影响,造成更加严重的灾难性遗忘现象,因此它们在持续学习中往往劣于bn。
6、持续归一化(cn)是专门为(在线)持续学习设计的一种归一化方式。它先对内部表征进行组归一化(gn)消除任务上的差异,接着进行批归一化(bn)得到最终的输出表征。这种方式部分地缓解了任务统计权重间的不平衡,但是由于最终仍然使用了bn,因此仍然继承了bn的一系列缺点。
7、综上,归一化技术是目前深度神经网络架构的最重要的基础构件之一。它对随机梯度优化的平稳性、收敛速率,模型对超参数选择的鲁棒性、对测试样本的泛化性均有着至关重要的作用。然而,目前大多数常用的归一化技术是针对单任务的独立同分布数据而设计,对于持续学习这样的具有多任务的非独立同分布数据没有良好的性能保证。进一步地,现有的面向持续学习的归一化技术有效性和通用性较为有限,大多都只适用于在线持续学习或者离线持续学习之间的某一个场景,普适的技术尚且缺失。
技术实现思路
1、本发明的目的在于提供一种使持续学习模型能够在保持优化稳定性的同时对任务的统计权重进行有效的平衡,加入了自适应参数调和ema的动量,使其在训练每个任务时有足够的适应性来平衡bn统计,从而更好地服务于测试阶段的面向持续学习的自适应平衡批归一化方法及系统,以解决上述背景技术中存在的至少一项技术问题。
2、为了实现上述目的,本发明采取了如下技术方案:
3、一方面,本发明提供一种面向持续学习的自适应平衡批归一化方法,包括:
4、从当前任务的数据集和内存缓冲区中抽取一个批次的样本,其中当前任务数据集中的数据是新样本,内存缓冲区中的样本是旧的任务的样本;
5、对新样本更新内存缓冲区,以便后续任务的使用;
6、将当前批次数据送入神经网络:对于神经网络除分类层外的每一网络层,都接着一个自适应平衡批归一化层,用于归一化网络层输出的内部表征。
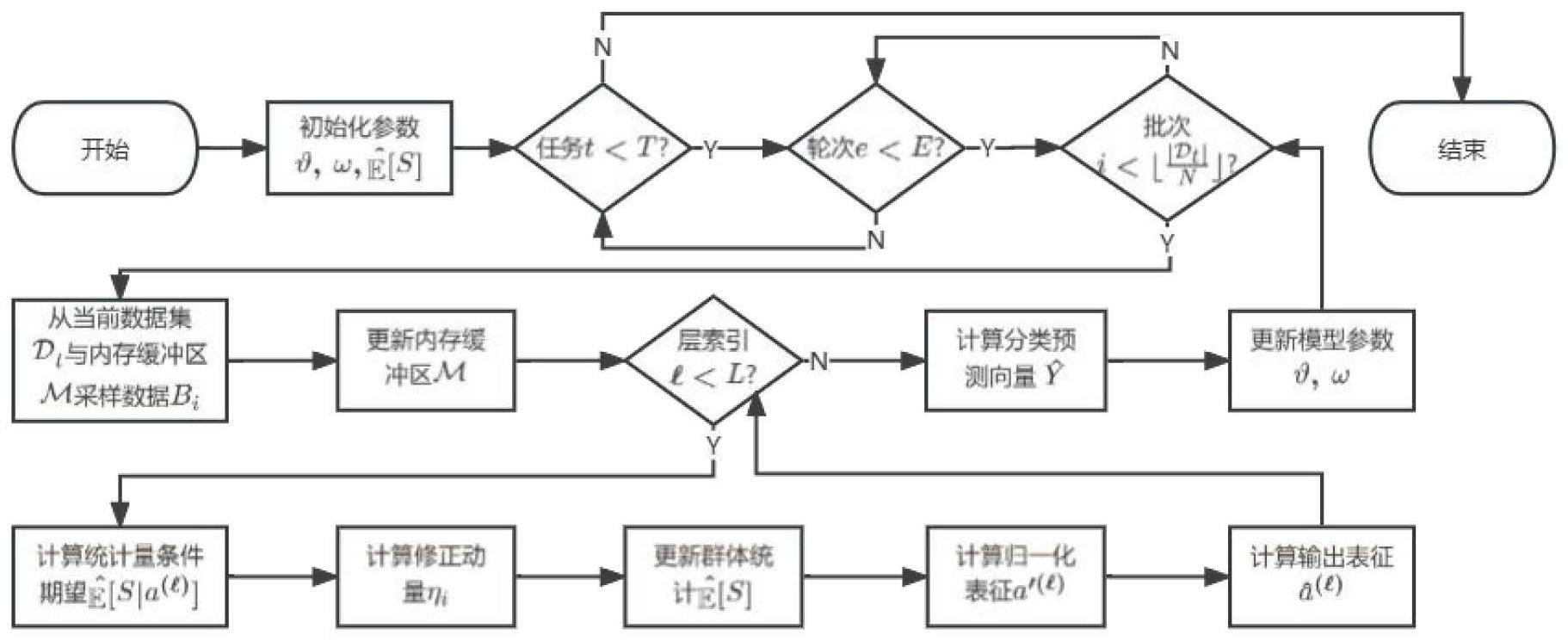
7、进一步的,自适应平衡批归一化层的算法包括:计算统计量的条件期望;计算群体统计的修正动量;更新群体统计;利用条件期望计算归一化表征;利用仿射变换参数输出表征。
8、进一步的,计算统计量的条件期望其中φt是可学习参数,是批次中属于任务t的样本的统计量,n表示批次大小,nt表示从测试集中采样的nt个训练样本。
9、进一步的,计算群体统计的修正动量是原始ema的动量,κ∈[0,1]是一个额外的用于控制归一化统计平衡的参数.
10、进一步的,更新群体统计
11、进一步的,利用条件期望计算归一化表征利用仿射变换参数输出表征ε是一个小常数以避免分母为零,γ和β是仿射变换参数。
12、第二方面,本发明提供一种面向持续学习的自适应平衡批归一化系统,包括:
13、抽取模块,用于从当前任务的数据集和内存缓冲区中抽取一个批次的样本,其中当前任务数据集中的数据是新样本,内存缓冲区中的样本是旧的任务的样本;
14、更新模块,用于对新样本更新内存缓冲区,以便后续任务的使用;
15、自适应平衡批归一化模块,用于将当前批次数据送入神经网络:对于神经网络除分类层外的每一网络层,都接着一个自适应平衡批归一化层,用于归一化网络层输出的内部表征。
16、第三方面,本发明提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如上所述的面向持续学习的自适应平衡批归一化方法。
17、第四方面,本发明提供一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现如上所述的面向持续学习的自适应平衡批归一化方法。
18、第五方面,本发明提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如上所述的面向持续学习的自适应平衡批归一化方法的指令。
19、本发明有益效果:利用基于贝叶斯的策略确定一种适当的方式来适应归一化表征中的任务贡献,能够稳定训练;加入了一个自适应参数来调和ema的动量,使其在训练每个任务时有足够的适应性来平衡任务统计权重,克服近因偏差带来的问题,为持续学习的研究领域提供了新的思路与借鉴。
20、本发明附加方面的优点,将在下述的描述部分中更加明显的给出,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!