促进神经网络加速计算的方法、装置及设备与流程
本发明涉及一种神经网络,尤其涉及一种基于fpga的促进神经网络加速计算的方法、装置、设备及介质。
背景技术:
1、随着神经网络模型的快速发展,选择高效的加速硬件平台以适应复杂的计算应用至关重要,如果加速硬件平台无法支持神经网络的计算,则会造成神经网络无法实现相应功能、卡顿等问题。现场可编程门阵列(fpga)因其低功耗和可重构特性而逐渐成为平衡功耗和性能的加速硬件平台。在2015年,现有技术开始引入roofline模型,以便分析不同模型参数下的fpga神经网络加速器,为fpga神经网络加速器的设计提供指导与优化。roofline模型能够描述计算任务在硬件平台的限制下能达到的理论计算性能。其中,roofline模型包括计算限制区和访存限制区,计算限制区指的是在处理器所有可用计算资源的限制下,能够达到的最高性能水平;访存限制区是指在给定计算任务的访存比值下,处理器核心能够支持的最大吞吐量。
2、在神经网络的计算过程中,矩阵运算是一个关键环节,并且矩阵运算拆解到元素级别则是海量次的乘加运算mac。因此,对于神经网络硬件加速器来说,mac的运算速度是至关重要的。然而,roofline模型虽然能够指导加速器的设计,但在算法计算强度较小时,硬件平台无法发挥其性能上限,整体性能受限于计算时的带宽表现,大量的计算核心会在部分时间处于空闲状态。这也是加速器设计面临的挑战之一,因为不同应用和不同层间的计算特性不统一,会导致性能损失。
3、综上,需要在现有技术的基础上,解决神经网络加速器设计中不同层次计算特征不匹配的问题。
技术实现思路
1、为了克服现有技术的不足,本发明的目的之一在于提供一种促进神经网络加速计算的方法,其通过访存比实现对神经网络各层的分组,进而为各组合理分配处理引擎。
2、本发明的目的之一采用以下技术方案实现:
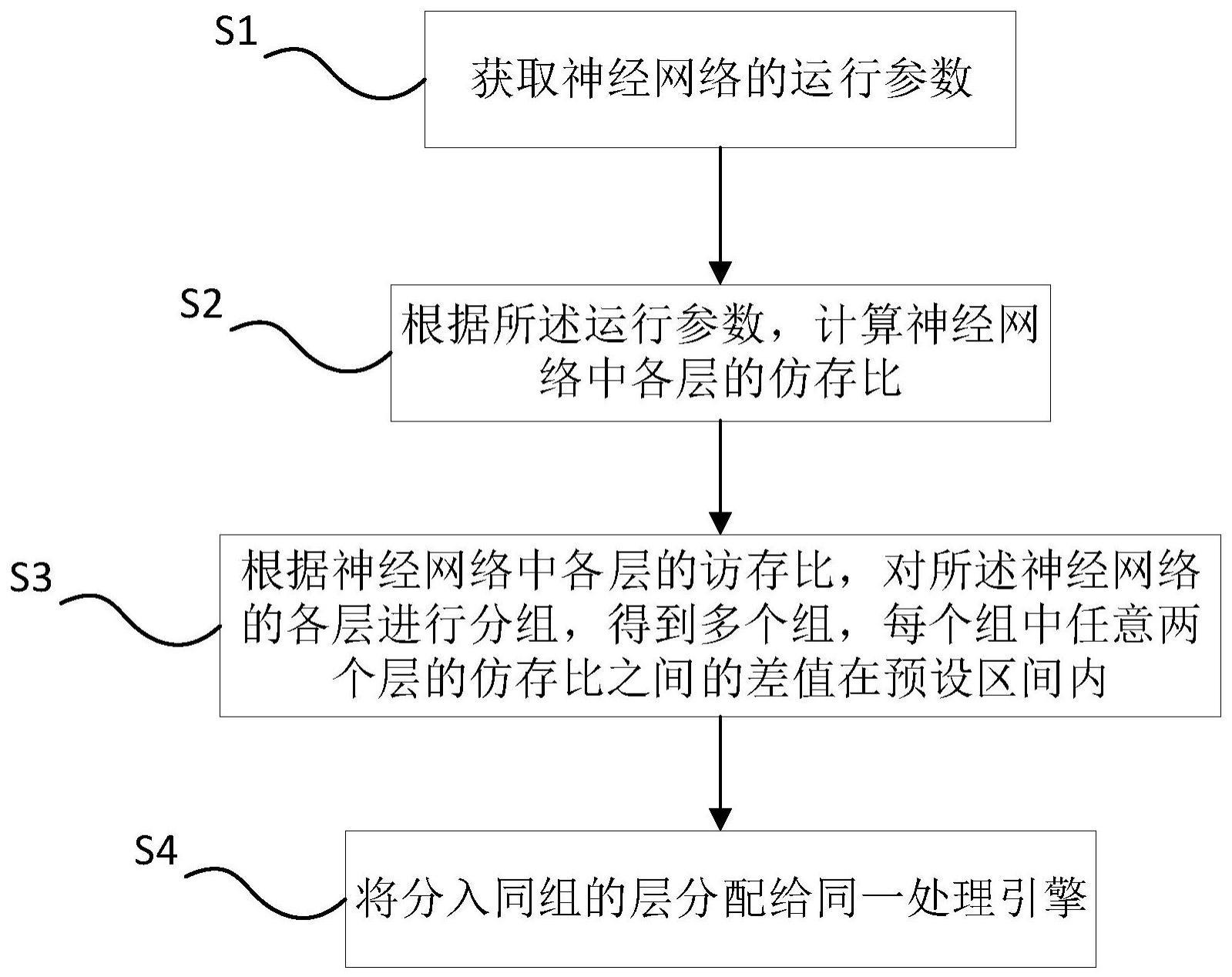
3、一种促进神经网络加速计算的方法,包括以下步骤:
4、获取神经网络的运行参数;
5、根据所述运行参数,计算神经网络中各层的仿存比;
6、根据神经网络中各层的访存比,对所述神经网络的各层进行分组,得到多个组,每个组中任意两个层的仿存比之间的差值在预设区间内;
7、将分入同组的层分配给同一处理引擎。
8、进一步地,所述运行参数包括:神经网络中各层的计算量、访问量。
9、进一步地,将分入同组的层分配给同一处理引擎,还包括:
10、计算每个处理引擎处理时的理论吞吐量;
11、根据所述各处理引擎的理论吞吐量,将同组中层的任务映射至计算量小于理论吞吐量的处理引擎。
12、进一步地,所述理论吞吐量的计算满足:
13、
14、其中,theoretical prefpe表示理论吞吐量,computational roof表示系统计算硬件峰值性能,ctc ratio*bw表示访存带宽支持最大性能;将同组层的任务映射至计算访存比小于处理引擎的上限的处理引擎。
15、进一步地,还包括根据通过计算处理引擎的均衡度计算并结合设计空间探索法提高所述进行处理引擎的计算性能重新生成,其中,所述均衡度equilibrium的计算满足公式为:
16、
17、其中,k表示处理引擎的个数,ci*timecosti表示第i个处理引擎完成某第i其中一层计算子序列所花费的时间开销,表示是处理引擎处理计算子序列花费时间开销的平均值。
18、进一步地,根据均衡度计算并结合设计空间探索法进行处理引擎的重新生成,包括以下步骤:
19、计算处理引擎历史均衡度及当前均衡度;
20、当所述当前均衡度小于等于所述历史均衡度时,进行迭代:
21、寻找当前配置中最大计算延迟开销的处理引擎,称为第一处理引擎;
22、为所述第一处理引擎增加计算资源并重新生成,得到第二处理引擎;
23、检查所述第二处理引擎,若合法,则继续进行迭代,直至述当前均衡度大于所述历史均衡度,若不合法,还原所述第二处理引擎至所述第一处理引擎,降低其他处理引擎的并行度并继续进行迭代。
24、进一步地,所述处理引擎处理神经网络层的计算子序列时,运行调度包括:
25、步骤一:将输入数据分成n个数据源,n与所述处理引擎数量相同;所述数据源为多个神经网络任务,每个所述的神经网络任务由多个神经网络层组成;
26、步骤二:将第一个数据源通过片外访问加载到第一个处理引擎,处理完成后,将所述第一个数据源的计算结果返回片外存储;
27、步骤三:将第二个数据源及处理后的第一个数据源通过片外访问分别加载到第一个处理引擎及第二个处理引擎,处理完成后将计算结果返回片外存储;
28、对n个数据源重复执行步骤二至步骤三,直至n个数据源处理完成。
29、本发明的目的之二在于提供一种神经网络计算加速装置,其通过访存比对神经网络计算量进行分组,进而为处理引擎匹配计算量合适的神经网络层。
30、本发明的目的之二采用以下技术方案实现:
31、一种神经网络计算加速装置,其包括:
32、数据获取模块,用于获取神经网络运行参数;
33、计算模块,用于根据所述运行参数,计算神经网络各层仿存比;
34、分配模块,用于根据访存比计算结果对所述神经网络进行分组,将访存比差值在预设区间内的层分入同组;并将分入同组的层分配给同一处理引擎。
35、本发明的目的之三在于提供执行发明目的之一的电子设备,其包括处理器、存储介质以及计算机程序,所述计算机程序存储于存储介质中,所述计算机程序被处理器执行时实现上述的促进神经网络加速计算的方法。
36、相比现有技术,本发明的有益效果在于:
37、本发明采用层间互联划分,通过神经网络运行参数计算访存比实现神经网络模型计算特性的量化分析,根据访存比进行神经网络中各层的分组,并将同组分别分配给同一处理引擎,实现了神经网络中各层与处理引擎计算特征的匹配,保持了计算单元的灵活性。
技术特征:
1.一种促进神经网络加速计算的方法,其特征在于,包括以下步骤:
2.如权利要求1所述的促进神经网络加速计算的方法,其特征在于,所述运行参数包括:神经网络中各层的计算量、访问量。
3.如权利要求1所述的促进神经网络加速计算的方法,其特征在于,将分入同组的层分配给同一处理引擎,还包括:
4.如权利要求3所述的促进神经网络加速计算的方法,其特征在于,所述理论吞吐量的计算满足:
5.如权利要求1所述的促进神经网络加速计算的方法,其特征在于,还包括根据均衡度计算并结合设计空间探索法进行处理引擎的重新生成。
6.如权利要求5所述的促进神经网络加速计算的方法,其特征在于,根据均衡度计算并结合设计空间探索法进行处理引擎的重新生成,包括以下步骤:
7.如权利要求6所述的促进神经网络加速计算的方法,其特征在于,其中,所述当前均衡度equilibrium的计算公式为:
8.如权利要求1所述的促进神经网络加速计算的方法,其特征在于,所述处理引擎处理神经网络层的计算子序列时,运行调度包括:
9.一种促进神经网络加速计算的装置,其特征在于,其包括:
10.一种电子设备,其包括处理器、存储介质以及计算机程序,所述计算机程序存储于存储介质中,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7任一项所述的促进神经网络加速计算的方法。
技术总结
本发明公开了一种促进神经网络加速计算的方法,涉及神经网络技术领域,用于解决现有神经网络计算分配时特征不匹配的问题,该方法包括以下步骤:获取神经网络运行参数;根据所述运行参数,计算神经网络各层仿存比;根据访存比计算结果对所述神经网络进行分组,将访存比差值在预设区间内的层分入同组;将分入同组的层分配给同一处理引擎。本发明还公开了一种神经网络计算加速装置及电子设备。本发明通过访存比对神经网络层进行分组,并匹配合适的处理引擎,使得神经网络计算分配时特征匹配,性能优。
技术研发人员:梅冰笑,韩睿,张永,蒋鹏,王文浩,李晨,李斐然,王超,宫磊,周学海,李曦
受保护的技术使用者:国网浙江省电力有限公司电力科学研究院
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!