用于成果转化的信息匹配方法及系统
本发明涉及数据分析,尤其涉及一种用于成果转化的信息匹配方法及系统。
背景技术:
1、随着技术的发展,成果数量的不断增加,成果转化需求匹配精准度的要求日益突出。当前的成果转化各类检索、筛选系统虽然可以查询买方用户关心的成果,但其返回是成果列表,剩余的筛选分析对比工作都是买方用户自己去完成,导致成果转化效率较低。并且,当前的成果转化检索、筛选技术都停留在关键字检索查找阶段,并没有从需求匹配精准度角度对成果筛选匹配功能进行改进,买方用户往往会消耗大量的时间进行后期的整理,这在成果较丰富的领域将会出现信息爆炸,无法实现快速转化。
技术实现思路
1、为解决上述现有技术中存在的部分或全部技术问题,本发明提供一种用于成果转化的信息匹配方法及系统。
2、本发明的技术方案如下:
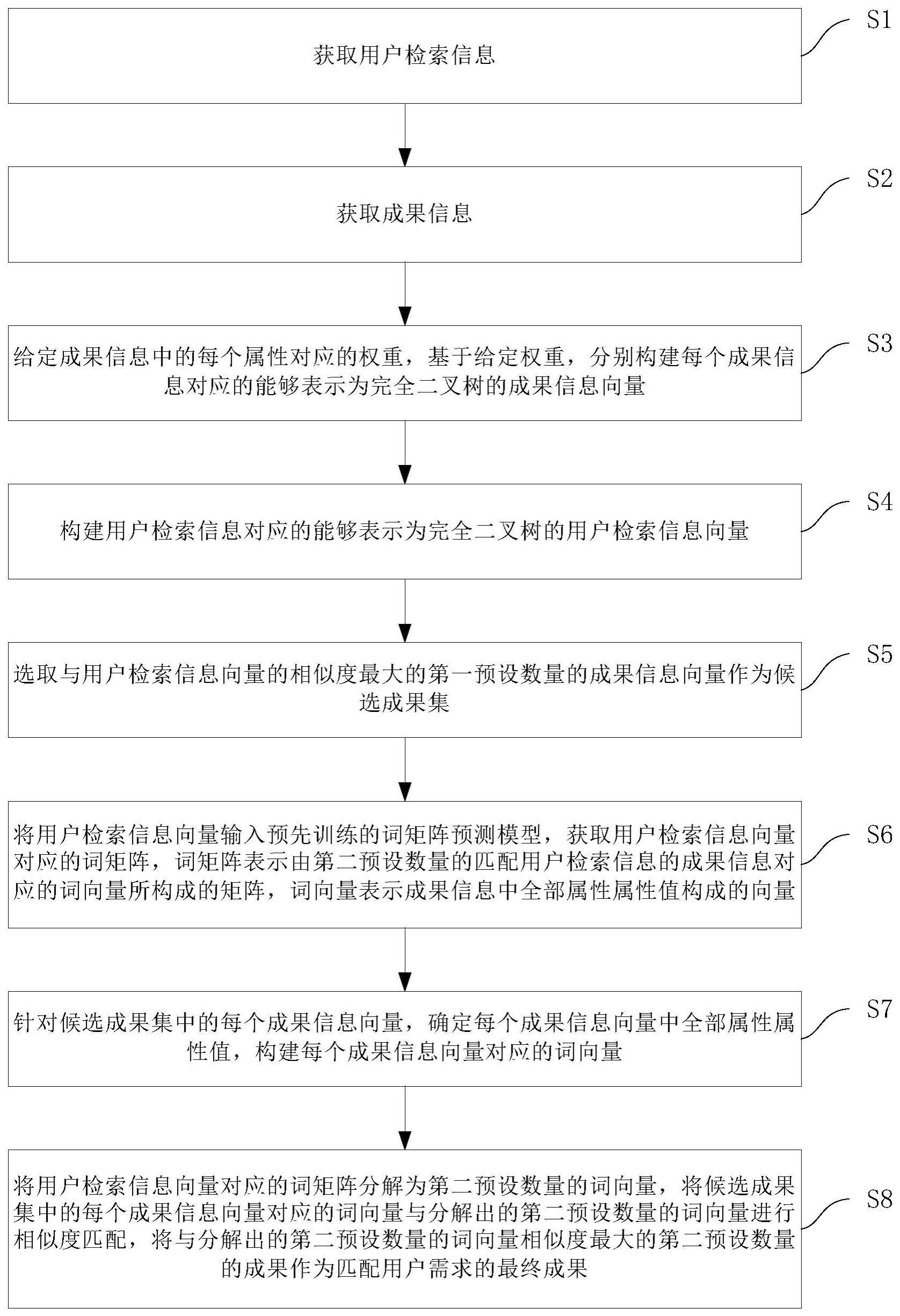
3、第一方面,提供了一种用于成果转化的信息匹配方法,所述方法包括:
4、获取用户检索信息,用户检索信息包括属性-属性值-权重的集合;
5、获取成果信息,成果信息包括成果标识和属性-属性值的集合;
6、给定成果信息中的每个属性对应的权重,基于给定权重,分别构建每个成果信息对应的能够表示为完全二叉树的成果信息向量;
7、构建用户检索信息对应的能够表示为完全二叉树的用户检索信息向量;
8、选取与用户检索信息向量的相似度最大的第一预设数量的成果信息向量作为候选成果集;
9、将用户检索信息向量输入预先训练的词矩阵预测模型,获取用户检索信息向量对应的词矩阵,词矩阵表示由第二预设数量的匹配用户检索信息的成果信息对应的词向量所构成的矩阵,词向量表示成果信息中全部属性-属性值构成的向量;
10、针对候选成果集中的每个成果信息向量,确定每个成果信息向量中全部属性-属性值,构建每个成果信息向量对应的词向量;
11、将用户检索信息向量对应的词矩阵分解为第二预设数量的词向量,将候选成果集中的每个成果信息向量对应的词向量与分解出的第二预设数量的词向量进行相似度匹配,将与分解出的第二预设数量的词向量相似度最大的第二预设数量的成果作为匹配用户需求的最终成果。
12、在一些可能的实现方式中,通过以下方式构建成果信息对应的能够表示为完全二叉树的成果信息向量:
13、步骤s301,针对成果信息中的每个属性-属性值,分别生成一个对应的包括属性-属性值-给定权重的分量,以所有分量构成一个初始成果信息向量;
14、步骤s302,设定l=m,m表示初始成果信息向量中的分量数;
15、步骤s303,确定初始成果信息向量中第个分量中的权重与第l-1个分量or[l-1]中的权重、第l个分量or[l]中的权重之间的大小关系,若第l-1个分量or[l-1]中的权重或/和第l个分量or[l]中的权重大于第个分量中的权重,则将权重最大的分量与第个分量进行位置交换,表示向下取整;
16、步骤s304,判断l是否等于0,若否,则令l=l-1,并返回步骤s303,若是,则将分量位置调整后的初始成果信息向量作为成果信息向量。
17、在一些可能的实现方式中,通过以下方式构建用户检索信息对应的能够表示为完全二叉树的用户检索信息向量:
18、步骤s401,针对用户检索信息中的每个属性-属性值-权重,分别生成一个对应的包括属性-属性值-权重的分量,以所有分量构成一个初始用户检索信息向量;
19、步骤s402,设定i=n,n表示初始用户检索信息向量中的分量数;
20、步骤s403,确定初始用户检索信息向量中第个分量中的权重与第i-1个分量ur[i-1]中的权重、第i个分量ur[i]中的权重之间的大小关系,若第i-1个分量ur[i-1]中的权重或/和第i个分量ur[i]中的权重大于第个分量中的权重,则将权重最大的分量与第个分量进行位置交换,表示向下取整;
21、步骤s404,判断i是否等于0,若否,则令i=i-1,并返回步骤s403,若是,则将分量位置调整后的初始用户检索信息向量作为用户检索信息向量。
22、在一些可能的实现方式中,利用以下方式确定候选成果集:
23、计算任意两个成果信息向量之间的相似度,将相似度作为对应两个成果信息向量的度量空间距离;
24、采用idistance索引将所有的成果信息向量进行度量空间的索引;
25、将用户检索信息向量转换为度量空间的一个点,检索idistance,选取与用户检索信息向量的度量空间距离最小的第一预设数量的成果信息向量作为候选成果集。
26、在一些可能的实现方式中,利用以下方式计算两个信息向量之间的相似度:
27、确定两个信息向量对应的完全二叉树结构;
28、确定两个信息向量中相同的属性;
29、针对每个相同属性,确定属性在一个信息向量对应的完全二叉树中的层次、以及在另一个信息向量对应的完全二叉树中的层次,并计算属性在两个完全二叉树中的层次差;
30、针对每个相同属性,确定属性在一个信息向量中对应的属性值、以及在另一个信息向量中对应的属性值,并对属性对应的两个属性值进行相似性计算,获取属性对应的文本相似度;
31、针对每个相同属性,计算属性对应的层次差与文本相似度的乘积;
32、对所有相同属性对应的乘积进行求和,将求和结果作为两个信息向量之间的相似度。
33、在一些可能的实现方式中,词矩阵预测模型通过如下方式训练:
34、获取训练样本集合,训练样本包括用户检索信息向量样本及其对应的词矩阵样本;
35、将用户检索信息向量样本作为输入,将与用户检索信息向量样本对应的词矩阵样本作为输出,训练词矩阵预测模型。
36、在一些可能的实现方式中,利用以下方式获取训练样本集合:
37、步骤s6011,确定一个包括属性-属性值-权重集的检索信息,以一个属性-属性值-权重作为一个向量分量,构建检索信息对应的向量作为用户检索信息向量样本;
38、步骤s6012,确定所有成果信息中属性-属性值满足检索信息中的属性-属性值的成果信息,并以确定的成果信息形成成果信息集合;
39、步骤s6013,从成果信息集合中挑选出与检索信息的相似度最大的第二预设数量的成果信息,确定挑选出的每个成果信息的全部属性-属性值,根据每个成果信息的全部属性-属性值分别构建一个对应的词向量,获取第二预设数量的词向量;
40、步骤s6014,利用第二预设数量的词向量构建词矩阵作为当前用户检索信息向量样本对应的词矩阵样本;
41、步骤s6015,重复步骤s6011-步骤s6014,直至得到第三预设数量的训练样本,获取训练样本集合,其中,不同的检索信息包括的属性-属性值-权重集不同。
42、在一些可能的
43、实现方式中,将用户检索信息向量样本作为输入,将与用户检索信息向量样本对应的词矩阵样本作为输出,训练词矩阵预测模型,包括:
44、步骤s6021,将多个用户检索信息向量样本依次输入词矩阵预测模型,得到词矩阵预测模型输出的预测词矩阵;
45、步骤s6022,根据用户检索信息向量样本对应的词矩阵样本和预测词矩阵,计算预设损失函数;
46、步骤s6023,判断是否达到预设训练停止条件,若是,则将当前的词矩阵预测模型作为完成训练的词矩阵预测模型,若否,则利用预设损失函数更新词矩阵预测模型的参数,并返回步骤s6021。
47、在一些可能的实现方式中,采用随机梯度下降法进行词矩阵预测模型的参数的训练更新。
48、第二方面,还提供了一种用于成果转化的信息匹配系统,所述系统包括:
49、用户检索信息获取模块,用于获取用户检索信息,用户检索信息包括属性-属性值-权重的集合;
50、成果信息获取模块,用于获取成果信息,成果信息包括成果标识和属性-属性值的集合;
51、成果信息向量构建模块,用于基于给定的成果信息中的每个属性对应的权重,分别构建每个成果信息对应的能够表示为完全二叉树的成果信息向量;
52、用户检索信息向量构建模块,用于构建用户检索信息对应的能够表示为完全二叉树的用户检索信息向量;
53、候选成果集确定模块,用于确定并选取与用户检索信息向量的相似度最大的第一预设数量的成果信息向量作为候选成果集;
54、词矩阵获取模块,用于利用预先训练的词矩阵预测模型对输入的用户检索信息向量进行处理,获取用户检索信息向量对应的词矩阵,词矩阵表示由第二预设数量的匹配用户检索信息的成果信息对应的词向量所构成的矩阵,词向量表示成果信息中全部属性-属性值构成的向量;
55、词向量获取模块,用于根据候选成果集中的每个成果信息向量中全部属性-属性值,构建每个成果信息向量对应的词向量;
56、成果输出模块,用于将用户检索信息向量对应的词矩阵分解为第二预设数量的词向量,将候选成果集中的每个成果信息向量对应的词向量与分解出的第二预设数量的词向量进行相似度匹配,将与分解出的第二预设数量的词向量相似度最大的第二预设数量的成果作为匹配用户需求的最终成果输出。
57、本发明技术方案的主要优点如下:
58、本发明的用于成果转化的信息匹配方法及系统通过将成果信息和用户检索信息转换为能够表示为完全二叉树形式的向量,能够利用完全二叉树父子节点之间的关系为后续的相似度计算和信息检索提供便利,以高效地实现用户需求精准匹配;同时,利用机器学习方法进行候选成果集的精选,能够进一步提高用户需求匹配的精确度,得到最匹配用户检索信息的成果,且检索效率和匹配效果高。
- 还没有人留言评论。精彩留言会获得点赞!