一种医疗保健大数据分析方法与流程
本发明涉及医疗大数据分析,具体是指一种医疗保健大数据分析方法。
背景技术:
1、医疗保健大数据分析是指利用大数据技术和分析方法,对医疗保健领域的大规模数据进行收集、存储、处理和分析的过程,这种分析可以从多个数据源中获得有关患者、医院、医生、药物和疾病等方面的信息,并从中提取有价值的见解和知识,医疗保健大数据分析的主要目的是帮助医疗保健机构和决策者做出更明智的决策,并提供更好的医疗保健服务。
2、但是在已有的医疗保健大数据分析过程中,存在着数据的来源多样且数据结构各异,不易统一分析和处理,降低了大数据分析的效率,提高了特征抽取的难度,缺少一种能够将多源异构数据融合的方法的技术问题;在已有的医疗保健大数据分析过程中,不可避免地会产生数据丢失和缺漏现象,存在着医疗保健大数据分析的难度加大,缺少一种针对多源异构数据的数据插补方法的技术问题;在已有的大数据分析方法中,存在着缺少一种能够对多源异构数据进行分析、处理和预测的方法,限制了医疗保健大数据分析应用领域的技术问题。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了一种医疗保健大数据分析方法,针对在已有的医疗保健大数据分析过程中,存在着数据的来源多样且数据结构各异,不易统一分析和处理,降低了大数据分析的效率,提高了特征抽取的难度,缺少一种能够将多源异构数据融合的方法的技术问题,本方案创造性地采用混合模糊支持向量网络结合聚类分析的数据融合方法,实现多源异构数据融合,有效地分类抽取各种类型数据的特征并完成数据融合,提高了大数据分析的效率并降低了后续数据处理和分析过程中特征抽取的难度;针对在已有的医疗保健大数据分析过程中,不可避免地会产生数据丢失和缺漏现象,存在着医疗保健大数据分析的难度加大,缺少一种针对多源异构数据的数据插补方法的技术问题,本方案采用基于潜在因素模型的数据插补方法,补足了丢失和缺漏的数据,提高了医疗保健大数据分析的准确度;针对在已有的大数据分析方法中,存在着缺少一种能够对多源异构数据进行分析、处理和预测的方法,限制了医疗保健大数据分析应用领域的技术问题,本方案创造性地采用基于卷积神经网络的单峰疾病风险预测算法,分析和处理融合的多源异构数据并进行疾病风险预测,优化了医疗保健大数据分析的效率和适用性。
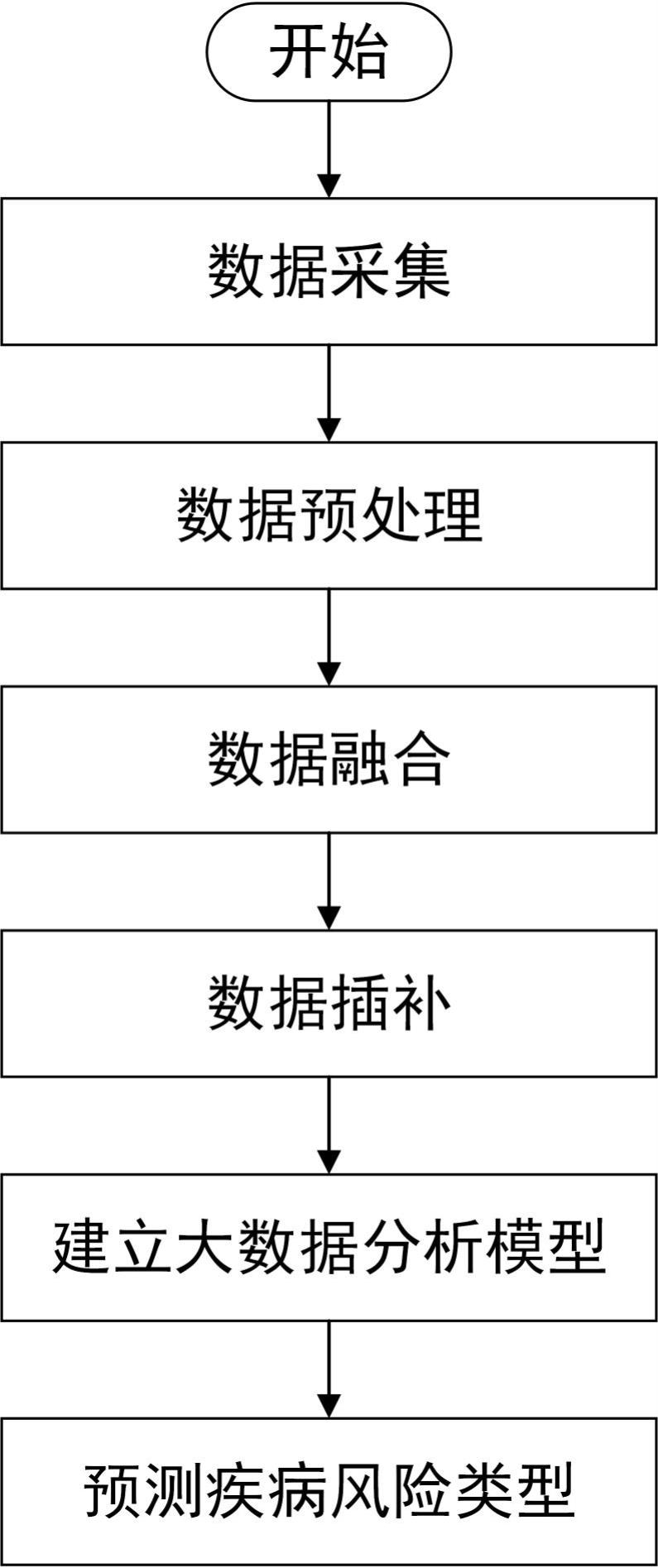
2、本发明采取的技术方案如下:本发明提供的一种医疗保健大数据分析方法,该方法包括以下步骤:
3、步骤s1:数据采集;
4、步骤s2:数据预处理;
5、步骤s3:数据融合;
6、步骤s4:数据插补;
7、步骤s5:建立大数据分析模型;
8、步骤s6:预测疾病风险类型。
9、进一步地,在步骤s1中,所述数据具体指医疗保健住院科室数据,所述医疗保健住院科室数据包括结构化数据和非结构化文本数据,所述结构化数据包括患者的年龄、性别、生活习惯等患者基本信息和实验室数据,所述非结构化文本数据包括患者的病情叙述、医生的问诊记录和诊断结果。
10、进一步地,在步骤s2中,所述数据预处理包括数据清洗、去重和筛除错误或无用的信息,经过所述数据预处理,得到多源异构数据。
11、进一步地,在步骤s3中,所述数据融合具体指多源异构数据融合,包括以下步骤:
12、步骤s31:构建基于混合模糊支持向量机的多源异构数据融合模型,包括以下步骤:
13、步骤s311:通过卷积提取多源异构数据的特征,计算公式为:
14、;
15、式中,outputl是卷积层输出,l是卷积层数,tanh(·)是激活函数,conl是卷积层操作,(i,j)是多源异构数据所对应的矩阵的位置坐标;
16、步骤s312:采用模糊c均值算法对所提取的特征进行聚类,包括以下步骤:
17、步骤s3121:选择从多个多源异构数据中提取的特征作为η组输入向量xdn,将所述输入向量xdn划分为c聚类类群,并计算模糊划分矩阵rij,计算公式为:
18、;
19、式中,rij是模糊划分矩阵,c是输入向量xdn被划分为的聚类类群的数量,k是累加变量,μi是特征坐标,cj是聚类类群中间值,j是聚类中心索引,ck是第k个聚类类群的值,γ是模糊程度系数;
20、步骤s3122:训练混合模糊支持向量机模型,采用最小化目标函数构建所述混合模糊支持向量机模型,计算公式为:
21、;
22、式中,trmin是最小化目标函数,η是输入向量xdn的组数,c是输入向量xdn被划分为的聚类类群的数量,i是数据输入样本索引,j是聚类中心索引,是经模糊程度系数控制的模糊划分矩阵,μi是特征坐标,cj是聚类类群中间值,||·||是欧几里得范数;
23、步骤s3123:构造复合核函数ckf,计算公式为:
24、;
25、式中,ckf(·)是复合核函数,φj是第j个样本的特征向量,φk是第k个样本的特征向量,是第j个样本的特征向量的转置向量,c是输入向量xdn被划分为的聚类类群的数量,θj(·)是核函数;
26、步骤s32:采用基于聚类分析的稀疏自编码器数据融合方法,融合多源异构数据,得到数据原始矩阵mo,所述基于聚类分析的稀疏自编码器数据融合方法,包括以下步骤:
27、步骤s321:采用子带自适应编码器创建稀疏自编码器并重建数据;
28、步骤s322:通过神经网络设置初始参数,调用均方损失函数,并使用亚当优化器优化数据,防止过拟合现象;
29、步骤s323:输入子带自适应编码器,确定样本数据的质心,通过计算确定数据核心和类别,经过多次迭代得到数据原始矩阵mo。
30、进一步地,在步骤s4中,所述数据插补,包括以下步骤:
31、步骤s41:采用潜在因素模型进行数据插补,具体为通过对数据原始矩阵mo进行矩阵分解,得到潜在因素系数矩阵r和潜在因素系数转置矩阵st,并使用所述潜在因素系数矩阵r和所述潜在因素系数转置矩阵st,近似计算数据插补矩阵m,计算公式为:
32、;
33、式中,m是患者总数,n是每个患者的特征属性的数量,m(m×n)是大小为m×n的数据插补矩阵,k是潜在因素的数量,rm×k是大小为m×k的潜在因素系数矩阵,是大小为n×k的潜在因素系数转置矩阵;
34、步骤s42:推导数据插补问题的公式表达,计算公式为:
35、;
36、式中,f(r,s)是数据插补函数,r是用户因素向量,s是特征属性因素向量,u是用户因素向量r所对应的矩阵中的索引,v是特征属性因素向量s所对应的矩阵中的索引,muv是数据原始矩阵mo在(u,v)位置上的元素值,ru是用户因素向量r所对应的矩阵中的第u行,是用户因素向量r所对应的矩阵中的第u行的转置,sv是特征属性因素向量s所对应的矩阵中的第v行,λ1和λ2是正则化参数,||·||是欧几里得范数;
37、步骤s43:采用随机梯度下降算法,进行数据插补。
38、进一步地,在步骤s5中,所述建立大数据分析模型,包括以下步骤:
39、步骤s51:数据表示,具体为使用rd维词向量表示所述非结构化文本数据,其中d=50,并使用词向量集text表示单词量为n的非结构化文本数据,所述词向量集text的计算公式为:
40、;
41、式中,α1是第1个单词的词向量,αn是第n个单词的词向量,所述词向量集text满足,其中是维度为d×n的词向量;
42、步骤s52:采用基于卷积神经网络的单峰疾病风险预测算法,构建疾病风险分析模型,所述基于卷积神经网络的单峰疾病风险预测算法,包括以下步骤:
43、步骤s521:计算卷积层输出张量并设置卷积层,计算公式为:
44、;
45、式中,是卷积层的输出张量的第i行和第j列,且位于第一个通道位置处的值,i和j是位置参数,f(·)是激活函数,ωcl是卷积层权重矩阵,βj是输入卷积层的词向量集text的子张量,bcl是卷积层偏置量;
46、步骤s522:通过卷积层,计算得到特征图矩阵输出hcl,计算公式为:
47、;
48、式中,hcl是特征图矩阵输出,是大小为100×n的卷积层输出张量,n是非结构化文本数据的单词量;
49、步骤s523:计算最大池化值并设置池化层,具体为将所述卷积层的输出作为池化层的输入,并进行最大池化操作,所述最大池化操作的计算公式为:
50、;
51、式中,是对卷积层的所述特征图矩阵输出hcl进行最大池化操作,得到池化层的输出张量hpl,是卷积层的输出张量的第i行和第j列,i和j是位置参数,n是非结构化文本数据的单词量;
52、步骤s524:通过计算将池化层连接至一个全连接神经网络,设置全连接层,所述将池化层连接至一个全连接神经网络的计算公式为:
53、;
54、式中,hfcl是全连接层的值,ωfcl是全连接层权重矩阵,bfcl是卷积层偏置量;
55、步骤s525:将全连接层连接至分类器,具体为将全连接层连接至softmax分类器;
56、步骤s53:通过设置卷积层、池化层、全连接层和分类器,得到疾病风险分析模型。
57、进一步地,在步骤s6中,所述预测疾病风险类型,具体为通过疾病风险分析模型,预测并将患者的疾病风险情况分为疾病高危人群和疾病非高危人员两类。
58、采用上述方案本发明取得的有益效果如下:
59、(1)针对在已有的医疗保健大数据分析过程中,存在着数据的来源多样且数据结构各异,不易统一分析和处理,降低了大数据分析的效率,提高了特征抽取的难度,缺少一种能够将多源异构数据融合的方法的技术问题,本方案创造性地采用混合模糊支持向量网络结合聚类分析的数据融合方法,实现多源异构数据融合,有效地分类抽取各种类型数据的特征并完成数据融合,提高了大数据分析的效率并降低了后续数据处理和分析过程中特征抽取的难度;
60、(2)针对在已有的医疗保健大数据分析过程中,不可避免地会产生数据丢失和缺漏现象,存在着医疗保健大数据分析的难度加大,缺少一种针对多源异构数据的数据插补方法的技术问题,本方案采用基于潜在因素模型的数据插补方法,补足了丢失和缺漏的数据,提高了医疗保健大数据分析的准确度;
61、(3)针对在已有的大数据分析方法中,存在着缺少一种能够对多源异构数据进行分析、处理和预测的方法,限制了医疗保健大数据分析应用领域的技术问题,本方案创造性地采用基于卷积神经网络的单峰疾病风险预测算法,分析和处理融合的多源异构数据并进行疾病风险预测,优化了医疗保健大数据分析的效率和适用性。
- 还没有人留言评论。精彩留言会获得点赞!