光场图像处理方法及装置与流程
本公开涉及图像处理,具体涉及一种光场图像处理方法及装置。
背景技术:
1、光场(light field)可以记录更高维度的光线数据,从而获得比传统二维成像及以双目立体视觉为代表的传统三维成像更高精度的三维信息,光场视频可以准确感知动态环境,使得用户感受到身临其境的观看体验。
2、随着机器学习(machine learning)技术的发展,利用基于深度神经网络的多视图立体匹配模型(mvs net,multi-view stereo net)对输入的多视点图像进行三维立体重建,具有较好的精度和效率。
3、但是对于实时光场视频场景,由于人物位置不固定,导致传统方案中对于mvs net的多视点输入图像的裁切难以保证人物效果,导致网络输出效果不佳。
技术实现思路
1、为提高光场视频场景中针对多视点图像的裁切效果,进而提高光场视频的处理效果和效率,本公开实施方式提供了一种光场图像处理方法、装置、电子设备、视频通信系统以及存储介质。
2、第一方面,本公开实施方式提供了一种光场图像处理方法,包括:
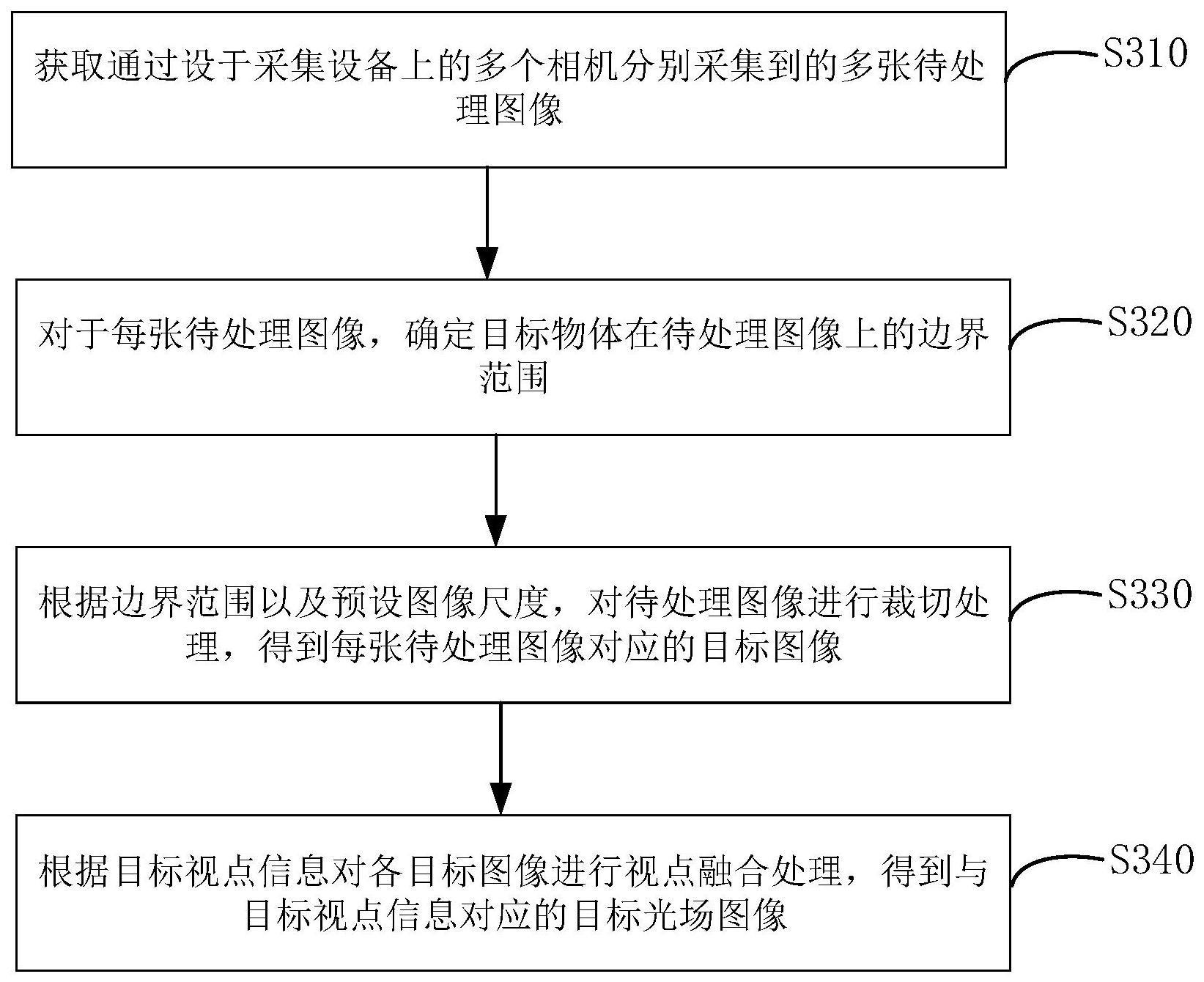
3、获取通过设于采集设备上的多个相机分别采集到的多张待处理图像;所述多张待处理图像为包括目标物体的不同视角的采集图像;
4、对于每张待处理图像,确定所述目标物体在所述待处理图像上的边界范围;
5、根据所述边界范围以及预设图像尺度,对所述待处理图像进行裁切处理,得到每张待处理图像对应的目标图像;
6、根据目标视点信息对各目标图像进行视点融合处理,得到与所述目标视点信息对应的目标光场图像;所述目标视点信息表示显示设备端的观察者眼睛的位置信息。
7、在一些实施方式中,所述对于每张待处理图像,确定所述目标物体在所述待处理图像上的边界范围,包括:
8、对于每张待处理图像,对所述待处理图像进行二值化处理,得到所述目标物体的二值图;
9、基于所述二值图上的像素值,依次逐行和逐列对所述目标物体进行边界搜索,得到所述目标物体在所述二值图上的水平边界和垂直边界;
10、基于所述水平边界和所述垂直边界,确定所述边界范围。
11、在一些实施方式中,所述基于所述二值图上的像素值,依次逐行和逐列对所述目标物体进行边界搜索,得到所述目标物体在所述二值图上的水平边界和垂直边界,包括以下中至少之一:
12、基于所述二值图上的像素值,从左至右依次逐列检测该列像素的黑色像素数量,响应于第一列像素及其之后的连续预设数量列像素的黑色像素数量均大于第一预设阈值,将所述第一列像素对应的坐标信息确定为所述水平边界的左边界;
13、从右至左依次逐列检测该列像素的黑色像素数量,响应于第二列像素及其之后的连续预设数量列像素的黑色像素数量均大于第二预设阈值,将所述第二列像素对应的坐标信息确定为所述水平边界的右边界;
14、从上至下依次逐行检测该行像素的黑色像素数量,响应于第一行像素及其之后的连续预设数量行像素的黑色像素数量均大于第三预设阈值,将所述第一行像素对应的坐标信息确定为所述垂直边界的上边界;
15、从下至上依次逐行检测该行像素的黑色像素数量,响应于第二行像素及其之后的连续预设数量行像素的黑色像素数量均大于第四预设阈值,将所述第二行像素对应的坐标信息确定为所述垂直边界的下边界。
16、在一些实施方式中,所述对于每张待处理图像,对所述待处理图像进行二值化处理,得到所述目标物体的二值图,包括:
17、对每张待处理图像进行抠图处理,得到每张待处理图像对应的包括所述目标物体的前景图像;
18、对每张前景图像进行二值化处理,得到所述目标物体的二值图。
19、在一些实施方式中,在所述基于所述二值图上的像素值,依次逐行和逐列对所述目标物体进行边界搜索,得到所述目标物体在所述二值图上的水平边界和垂直边界之前,所述方法还包括:
20、基于所述二值图上的像素值,以预设尺度的滑动窗口在所述二值图上按预设步长进行搜索;
21、在每个滑动窗口中,基于该滑动窗口包括的像素的像素值之和,对所述滑动窗口包括的像素进行去噪处理。
22、在一些实施方式中,所述根据所述边界范围以及预设图像尺度,对所述待处理图像进行裁切处理,得到每张待处理图像对应的目标图像,包括:
23、根据所述边界范围确定所述目标物体的中心点坐标;
24、将所述目标物体的中心点坐标确定为所述目标图像的中心点坐标,以所述预设图像尺度对所述待处理图像进行裁切处理,得到所述目标图像。
25、在一些实施方式中,根据目标视点信息对各目标图像进行视点融合处理,得到与所述目标视点信息对应的目标光场图像,包括:
26、将所述多张待处理图像中的至少两张待处理图像输入预先训练的深度网络模型,得到所述深度网络模型输出的所述目标物体的深度图;
27、基于所述目标视点信息对所述深度图进行视点融合处理,得到与所述目标视点信息对应的视点下的目标视点深度图;
28、将所述目标图像、所述目标视点深度图以及所述目标视点信息输入预先训练的视点融合模型,得到所述视点融合模型输出的所述目标光场图像。
29、在一些实施方式中,应用于所述采集设备;在所述根据目标视点信息对各目标图像进行视点融合处理,得到与所述目标视点信息对应的目标光场图像之后,所述方法还包括:
30、将所述目标光场图像发送至所述显示设备,以使所述显示设备渲染显示所述目标光场图像。
31、第二方面,本公开提供了一种光场图像处理装置,包括:
32、图像获取模块,被配置为获取通过设于采集设备上的多个相机分别采集到的多张待处理图像;所述多张待处理图像为包括目标物体的不同视角的采集图像;
33、边界搜索模块,被配置为对于每张待处理图像,确定所述目标物体在所述待处理图像上的边界范围;
34、裁切处理模块,被配置为根据所述边界范围以及预设图像尺度,对所述待处理图像进行裁切处理,得到每张待处理图像对应的目标图像;
35、视点融合模块,被配置为根据目标视点信息对各目标图像进行视点融合处理,得到与所述目标视点信息对应的目标光场图像;所述目标视点信息表示显示设备端的观察者眼睛的位置信息。
36、在一些实施方式中,所述边界搜索模块被配置为:
37、对于每张待处理图像,对所述待处理图像进行二值化处理,得到所述目标物体的二值图;
38、基于所述二值图上的像素值,依次逐行和逐列对所述目标物体进行边界搜索,得到所述目标物体在所述二值图上的水平边界和垂直边界;
39、基于所述水平边界和所述垂直边界,确定所述边界范围。
40、在一些实施方式中,所述边界搜索模块被配置为:
41、基于所述二值图上的像素值,从左至右依次逐列检测该列像素的黑色像素数量,响应于第一列像素及其之后的连续预设数量列像素的黑色像素数量均大于第一预设阈值,将所述第一列像素对应的坐标信息确定为所述水平边界的左边界;
42、从右至左依次逐列检测该列像素的黑色像素数量,响应于第二列像素及其之后的连续预设数量列像素的黑色像素数量均大于第二预设阈值,将所述第二列像素对应的坐标信息确定为所述水平边界的右边界;
43、从上至下依次逐行检测该行像素的黑色像素数量,响应于第一行像素及其之后的连续预设数量行像素的黑色像素数量均大于第三预设阈值,将所述第一行像素对应的坐标信息确定为所述垂直边界的上边界;
44、从下至上依次逐行检测该行像素的黑色像素数量,响应于第二行像素及其之后的连续预设数量行像素的黑色像素数量均大于第四预设阈值,将所述第二行像素对应的坐标信息确定为所述垂直边界的下边界。
45、在一些实施方式中,所述边界搜索模块被配置为:
46、对每张待处理图像进行抠图处理,得到每张待处理图像对应的包括所述目标物体的前景图像;
47、对每张前景图像进行二值化处理,得到所述目标物体的二值图。
48、在一些实施方式中,所述边界搜索模块被配置为:
49、基于所述二值图上的像素值,以预设尺度的滑动窗口在所述二值图上按预设步长进行搜索;
50、在每个滑动窗口中,基于该滑动窗口包括的像素的像素值之和,对所述滑动窗口包括的像素进行去噪处理。
51、在一些实施方式中,所述裁切处理模块被配置为:
52、根据所述边界范围确定所述目标物体的中心点坐标;
53、将所述目标物体的中心点坐标确定为所述目标图像的中心点坐标,以所述预设图像尺度对所述待处理图像进行裁切处理,得到所述目标图像。
54、在一些实施方式中,所述视点融合模块被配置为:
55、将所述多张待处理图像中的至少两张待处理图像输入预先训练的深度网络模型,得到所述深度网络模型输出的所述目标物体的深度图;
56、基于所述目标视点信息对所述深度图进行视点融合处理,得到与所述目标视点信息对应的视点下的目标视点深度图;
57、将所述目标图像、所述目标视点深度图以及所述目标视点信息输入预先训练的视点融合模型,得到所述视点融合模型输出的所述目标光场图像。
58、在一些实施方式中,本公开所述的装置应用于所述采集设备,其还包括发送模块,所述发送模块被配置为:
59、将所述目标光场图像发送至所述显示设备,以使所述显示设备渲染显示所述目标光场图像。
60、第三方面,本公开实施方式提供了一种电子设备,包括:
61、处理器;和
62、存储器,存储有计算机指令,所述计算机指令用于使所述处理器执行根据第一方面任意实施方式所述的方法。
63、第四方面,本公开实施方式提供了一种视频通信系统,包括:
64、显示设备,包括图像采集装置和第一控制器;
65、采集设备,包括多个相机和第二控制器,所述第一控制器和所述第二控制器至少其中之一用于执行根据第一方面任意实施方式所述的方法。
66、第五方面,本公开实施方式提供了一种存储介质,存储有计算机指令,所述计算机指令用于使计算机执行根据第一方面任意实施方式所述的方法。
67、本公开实施方式的光场图像处理方法,包括获取通过设于采集设备上的多个相机分别采集到的多张待处理图像,对于每张待处理图像,确定目标物体在待处理图像上的边界范围,根据边界范围以及预设图像尺度,对待处理图像进行裁切处理得到每张待处理图像对应的目标图像,根据目标视点信息对各目标图像进行视点融合处理得到目标光场图像。本公开实施方式中,基于目标物体的边界范围对待处理图像进行裁切处理,可以降低将目标物体置于图像边缘、甚至被裁切掉的风险,提高裁切后图像的质量,为后续的视点融合处理提供较好的数据基础,进而提高光场视频通信的质量和效率。
- 还没有人留言评论。精彩留言会获得点赞!