模型训练方法与流程
本技术涉及深度学习,尤其涉及一种模型训练方法。
背景技术:
1、在进行人脸图像信号处理时,可以使用基于深度学习的图像去噪方法进行图像降噪,即将待处理人脸图像输入至图像降噪网络模型中进行降噪处理。
2、但是,相关技术中,图像降噪模型容易将人脸图像中不同目标物之间的边界细节特征当成噪点去除,如图像降噪模型对低照度场景下的人脸图像进行降噪处理时,容易将人脸五官边界细节当成噪点去除,从而影响最终的图像信号处理质量。
技术实现思路
1、本技术的主要目的在于提供一种模型训练方法,旨在解决图像降噪模型降噪不准确的技术问题。
2、为实现上述目的,本技术提供一种模型训练方法,方法包括:
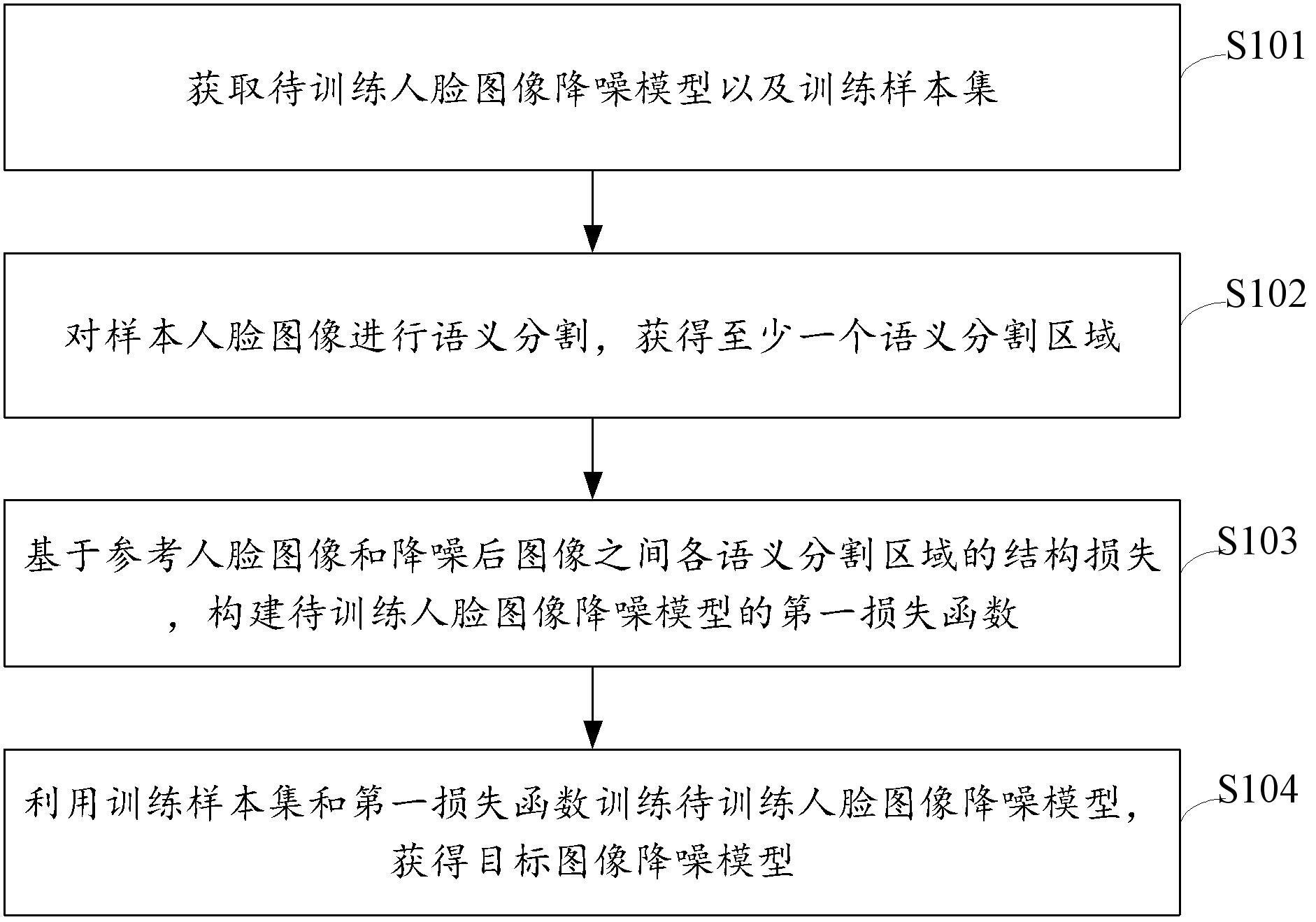
3、获取待训练人脸图像降噪模型以及训练样本集,训练样本集包括多组图像对,每组图像对包括样本人脸图像和参考人脸图像;待训练人脸图像降噪模型用于对样本人脸图像进行降噪处理,获得降噪后图像;
4、对样本人脸图像进行语义分割,获得至少一个语义分割区域;
5、基于参考人脸图像和降噪后图像之间各语义分割区域的结构损失,构建待训练人脸图像降噪模型的第一损失函数;
6、利用训练样本集和第一损失函数训练待训练人脸图像降噪模型,获得目标图像降噪模型。
7、在本技术可能的一实施例中,基于参考人脸图像和降噪后图像之间各语义分割区域的结构损失,构建待训练人脸图像降噪模型的第一损失函数,包括:
8、基于参考人脸图像和降噪后图像之间各语义分割区域的结构损失,以及各语义分割区域的区域权重,构建待训练人脸图像降噪模型的第一损失函数。
9、在本技术可能的一实施例中,基于参考人脸图像和降噪后图像之间各语义分割区域的结构损失,构建待训练人脸图像降噪模型的第一损失函数,包括:
10、确定待训练人脸图像降噪模型的第一参考损失函数分量;
11、基于参考人脸图像和降噪后图像之间各语义分割区域的结构损失,构建结构损失函数分量;
12、基于第一参考损失函数分量,第一参考损失函数分量的第一权重、结构损失函数分量以及结构损失函数分量的第二权重,构建第一损失函数。
13、在本技术可能的一实施例中,获取待训练人脸图像降噪模型以及训练样本集,包括:
14、获取待训练图像降噪插值网络模型以及训练样本集;图像降噪插值网络模型包括依次连接的待训练人脸图像降噪模型和图像插值模型,样本人脸图像为raw原始人脸图像,参考人脸图像为彩色人脸图像,且图像插值模型用于对降噪后图像进行光谱上采样插值重建,获得重建彩色人脸图像;
15、利用训练样本集和第一损失函数训练待训练人脸图像降噪模型,获得目标图像降噪模型,包括:
16、基于重建彩色人脸图像和参考人脸图像,构建图像插值模型的第二损失函数;
17、利用训练样本集、第一损失函数和第二损失函数,训练待训练图像降噪插值网络模型,获得目标图像降噪插值网络模型。
18、在本技术可能的一实施例中,基于重建彩色人脸图像和参考人脸图像,构建图像插值模型的第二损失函数,包括:
19、确定图像插值模型的第二参考损失函数分量;
20、基于重建彩色人脸图像和参考人脸图像之间的高低频损失函数分量、高低频损失函数分量对应的第三权重、第二参考损失函数分量以及第二参考损失函数分量的第四权重,构建第二损失函数。
21、在本技术可能的一实施例中,利用训练样本集、第一损失函数和第二损失函数,训练待训练图像降噪插值网络模型,获得目标图像降噪插值网络模型,包括:
22、基于第一损失函数、第一损失函数的第五权重、第二损失函数以及第二损失函数的第六权重,构建联合损失函数;
23、利用训练样本集和联合损失函数,训练待训练图像降噪插值网络模型,获得目标图像降噪插值网络模型。
24、在本技术可能的一实施例中,待训练图像降噪插值网络模型包括通道分离模块、输出层以及通道分离模块和输出层之间并排的多个通道;
25、每个通道包括依次连接的待训练人脸图像降噪模型和图像插值模型,且图像插值模型用于对输入的降噪后图像进行插值和上采样,输出上采样图像,上采样图像的尺寸和样本人脸图像的尺寸相同;
26、通道分离模块用于接收样本人脸图像,基于多个预设尺寸对样本人脸图像分别进行下采样,获得多个通道输入图像,将通道输入图像输入至对应的通道;其中,多个预设尺寸彼此不同,且多个预设尺寸与多个通道一一对应;
27、输出层用于接收各个通道输出的上采样图像,将多个上采样图像融合得到重建彩色人脸图像。
28、在本技术可能的一实施例中,利用训练样本集和联合损失函数,训练待训练图像降噪插值网络模型,获得目标图像降噪插值网络模型,包括:
29、基于训练步数和各个通道的序号,构建各个通道的训练步数相关度;其中,通道的序号与预设尺寸成负相关,当训练步数小于预设收敛步数时,训练步数相关度和序号呈正相关,当训练步数大于预设收敛步数时,训练步数相关度和序号呈负相关;
30、将训练步数相关度作为对应的通道的通道权重;
31、基于各个通道的联合损失函数和各个通道的通道权重,构建网络总体损失函数;
32、利用训练样本集和网络总体损失函数,训练待训练图像降噪插值网络模型,获得目标图像降噪插值网络模型。
33、在本技术可能的一实施例中,基于训练步数和各个通道的序号,构建各个通道的训练步数相关度,包括:
34、基于训练步数、各个通道的序号和公式一,构建各个通道的训练步数相关度;
35、公式一为:
36、;
37、其中,,满足:,为第个通道的通道权重,为训练步数,为预设收敛步数,为大于或者等于1的常数。
38、在本技术可能的一实施例中,利用训练样本集和网络总体损失函数,训练待训练图像降噪插值网络模型,获得目标图像降噪插值网络模型,包括:
39、将网络总体损失函数中的第五权重赋值为1,第六权重赋值为0,获得第一状态网络总体损失函数;
40、利用训练样本集训练待训练图像降噪插值网络模型,并使用第一状态网络总体损失函数更新待训练图像降噪插值网络模型的模型参数,直至第一状态网络总体损失函数收敛,获得第一阶段训练模型;
41、将第五权重赋值为0,第六权重赋值为1,获得第二状态网络总体损失函数;
42、利用训练样本集训练第一阶段训练模型,并使用第二状态网络总体损失函数更新第一阶段训练模型的模型参数,直至第二状态网络总体损失函数收敛,获得第二阶段训练模型;
43、确定网络总体损失函数中的第五权重的第一初始赋值和第六权重赋值的第二初始赋值,获得第三状态网络总体损失函数;其中,第一初始赋值和第二初始赋值均大于1,且两者的和等于1;
44、利用训练样本集训练第二阶段训练模型,并使用第三状态网络总体损失函数更新第五权重和第六权重,直至第二阶段训练模型收敛得到目标图像降噪插值网络模型。
45、在本技术可能的一实施例中,确定网络总体损失函数中的第五权重的第一初始赋值和第六权重赋值的第二初始赋值,获得第三状态网络总体损失函数之前,方法还包括:
46、确定当前的第二阶段训练模型;
47、根据损失函数交替训练规则,从第一状态网络总体损失函数和第二状态网络总体损失函数中确定出当前训练损失函数;
48、利用训练样本集训练当前的第二阶段训练模型,并使用当前训练损失函数更新当前的第二阶段训练模型的模型参数,直至当前训练损失函数收敛;
49、返回执行确定当前的第二阶段训练模型,直至第一状态网络总体损失函数和第二状态网络总体损失函数均收敛,获得收敛后的第二阶段训练模型;
50、利用训练样本集训练第二阶段训练模型,并使用第三状态网络总体损失函数更新第五权重和第六权重,直至第二阶段训练模型收敛得到目标图像降噪插值网络模型,包括:
51、利用训练样本集训练收敛后的第二阶段训练模型,并使用第三状态网络总体损失函数更新第五权重和第六权重,直至第二阶段训练模型收敛得到目标图像降噪插值网络模型。
52、本技术实施例提出的一种模型训练方法,方法包括:获取待训练人脸图像降噪模型以及训练样本集,训练样本集包括多组图像对,每组图像对包括样本人脸图像和参考人脸图像;待训练人脸图像降噪模型用于对样本人脸图像进行降噪处理,获得降噪后图像;对样本人脸图像进行语义分割,获得至少一个语义分割区域;基于参考人脸图像和降噪后图像之间各语义分割区域的结构损失,构建待训练人脸图像降噪模型的第一损失函数;利用训练样本集和第一损失函数训练待训练人脸图像降噪模型,获得目标图像降噪模型。
53、不难看出,本技术实施例在训练人脸图像降噪模型时,构建的损失函数包含了参考人脸图像和降噪后图像之间各语义分割区域的结构损失,从而在对待训练人脸图像降噪模型进行训练时,对模型的输出结果中各语义分割区域的结构损失程度进行衡量,进而可使得训练得到的人脸图像降噪模型可以更好的在降噪处理过程中保留五官等细节特征,以提高后续的图像处理效果。
- 还没有人留言评论。精彩留言会获得点赞!