一种基于半监督学习的数字化信息归并分类算法
本发明属于数据挖掘领域,具体涉及一种基于半监督学习的数字化信息归并分类算法。
背景技术:
1、数字化信息归并分类是当前数据挖掘领域中一个极具挑战的课题,也是许多学者和专家所关心的课题。数字化信息归并分类是指从大量样本数据中提取得到有用信息,由于数字化信息具有实时性、高维度、动态性、顺序性以及无限性等特点,且信息中含有一些随时间和环境变化的概念和知识,即概念漂移,在一定程度上增加了归并分类难度,因此,研究有效的数字化信息归并分类方法具有一定的现实意义。
2、一个合理的数字化信息归并分类算法应该在有限时间和空间内精准完成归并分类任务,且有效避免概念漂移问题和过滤数据中的噪声。对此,孙志于等人利用数据场理论,提出一种分布式自适应数据分类方法。首先,在数据场理论中引入监督信息,扩展其应用领域,使其适用于分类问题;然后,将自适应数据域值空间转换为势场空间,完成对数据无标签的分类;将历史监督信息与无标签分类结果进行相似度对比,将具有较大相似度的类别进行融合;最后,将分布式数据分配到合适的类别中,以此完成数据分类。陆克中等人将加权机制与遗忘机制联立,建立基本分类器,并与加权在线顺序极限学习机集成算法相结合,实现对非平衡、复杂数据流的分类。除此之外,还有学者提出了基于人工神经网络的分类算法,通过多层神经元对数据进行处理和学习,得出分类结果。
3、上述方法要求具有非常大的数据量支撑算法运算,对承载硬件要求较高,为此,本发明提供一种基于半监督学习的数字化信息归并分类算法(sdclass)。
技术实现思路
1、本发明要解决的技术问题是提供一种基于半监督学习的数字化信息归并分类算法,较其他算法相比,有着更加理想的数据归并分类效果。
2、为解决上述技术问题,本发明的实施例提供一种基于半监督学习的数字化信息归并分类算法,包括如下步骤:
3、s1、数字化信息预处理:对原始数字化信息进行概念漂移检测和噪声数据过滤处理,降低后续的归并分类难度;
4、s2、基于半监督学习的基础分类器构建:利用k均值聚类算法对数据块进行训练,并在半监督学习算法的约束下使得目标函数值最小,得到最优聚类中心;
5、s3、基于sdclass算法的归并分类器实现:利用sdclass算法构建归并分类器,通过对数据块的类标签进行估计,并计算估计值与簇中心之间的距离,将数据块划分到距离最近的类别中,完成数字化信息的归并分类。
6、其中,步骤s1的具体步骤为:
7、s1.1、假设数字化信息中存在一个随机变量e,其最大值为r,利用hoeffdingbounds不等式对数字化信息进行漂移检测,定义r=log2m,其中,m表示划分类别数量,先对当前变量e与上一变量e-1之间的分类错误率进行比较,得到二者差值e';设定一个阈值p,将e'与p进行对比,当e'>p时,说明数字化信息发生了概念漂移现象,直接对其进行抑制即可,降低归并分类难度;
8、s1.2、利用朴素贝叶斯分类器精准检测数字化信息中的噪声,过滤噪声数据,步骤为:
9、给出一个未标记的数据实例x={x1,x2,…,xn},利用贝叶斯定理计算x属于ci簇类的概率:
10、
11、式中,p(x)是一个常数项,p(x|ci)p(ci)表示最大化先验概率;
12、假设x的所有特征均是独立存在的,则有:
13、
14、利用上述方法对所有数据实例进行计算,再经过k+1个分类器投票后,如果一半以上分类器都出现了分类错误的情况,就认定该数据为噪声数据,直接将其过滤。
15、其中,步骤s2的具体步骤为:
16、s2.1、k均值聚类算法训练
17、完成对数字化信息的预处理后,利用半监督学习对k均值聚类算法训练,找出簇中被标记的实例数据,再对已标记的数据块进行训练,得到基础分类器,基于基础分类器完成对数字化信息的初分类;
18、定义1:假设存在一个同质簇ck,且满足下列两个条件中任意一个:
19、(1)簇中的所有实例都已经被标记;
20、(2)有着相同类标签label的标记实例数量大于阈值p;
21、定义2:label被视为ck的簇标签
22、当数据块中同时包含已标记实例和未标记实例时,归并分类的目的就是使实例与簇中心的距离最短,且确保所有簇都是同质的;对目标函数进行定义,使有着相同类标签的实例归类到同一个簇中;目标函数os-k的表达式为:
23、
24、式中,y是一个t×k的隶属矩阵;c={c1,c2,…,ck}表示簇中心,k=1,2,…,k表示一个整数;hk表示ck的同质度量函数,s表示数据块,vk表示ck的关联权值;
25、定义为簇ck中类标签为label_c的实例数据的先验概率,表达式如式(4)所示:
26、
27、式中,|lk(c)|表示簇ck中类标签为label_c的实例数据数量,|lk|表示簇ck中已经被标记的实例数据数量;
28、推理得到hk的表达式为:
29、
30、当簇ck中的类别分散程度越大,hk的值就越大;当hk<1-p2时,ck符合同质簇含义;hk受|lk(c)|和|lk|影响,|lk(c)|和|lk|受y影响,确定了y值后,即得到了hk值;
31、在基础分类器中添加属性权值,将簇中心ck与实例xi之间的欧式距离dis(xi,ck)转换为附带属性权值的欧式距离dis-w(xi,ck),表达式如式(6)所示:
32、
33、式中,wq(q=1,2,…,q)表示第q个属性的权值,w表示权值;xiq、ckq分别表示附带了属性权值的实例xi和簇中心ck;
34、基于此,得到半监督学习和属性权值综合作用下的k均值聚类算法目标函数osw-kmeans(y,c,w),表达式为:
35、
36、s2.2、k均值聚类目标函数求解
37、k均值聚类目标函数求解的目的是使osw-k(y,c,w)值最小,将其划分为3个子问题进行求解,直至矩阵y中的所有数据块不再变化或者所有簇均满足同质簇要求;
38、子问题dcw:使得到求解y的估计值
39、子问题dyw:使得到求解c的估计值
40、子问题dyc:使得到求解w的估计值
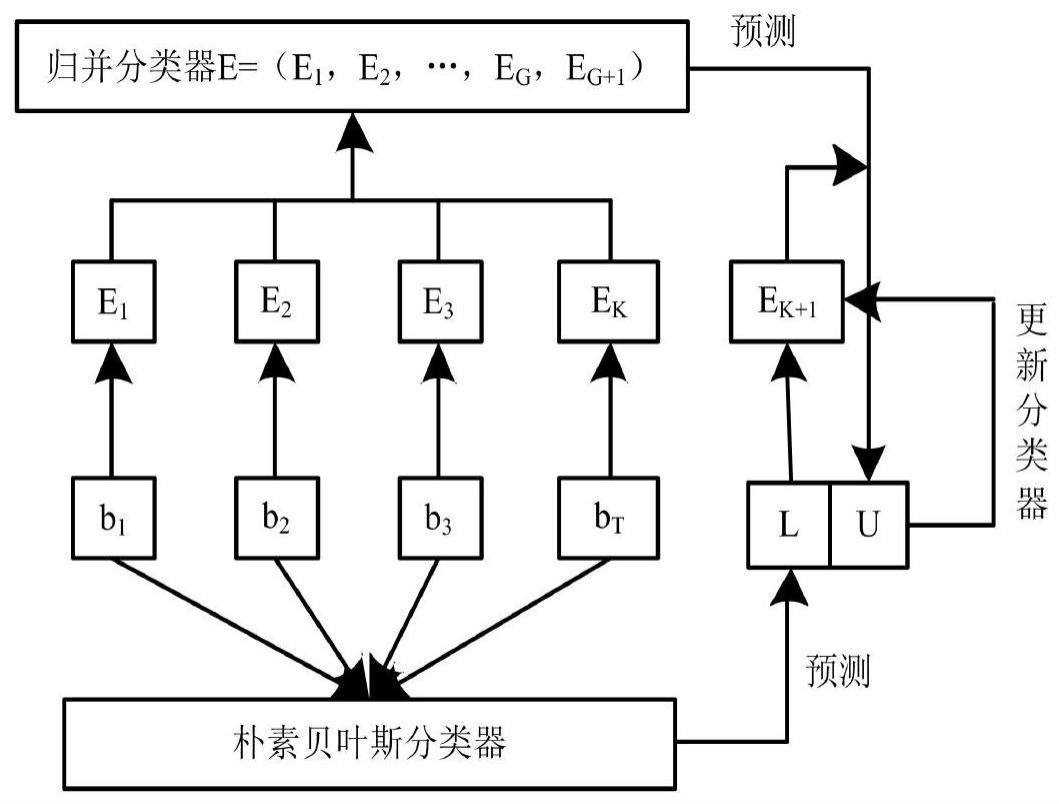
41、子问题dcw说明已知c和w,将数据实例划分到与之距离最近的簇中,得到最优聚类;由此可将的求解问题转换为数据实例最小化osw-kmeans(xi)的求解问题,表达式如式(8)所示:
42、
43、子问题dyw说明已经对k个簇的聚类中心完成了更新,表达式为:
44、
45、当得到了值和值后,即可推理得到子问题dyc的求解公式。
46、其中,步骤s3的具体步骤为:
47、通过基础分类器确定了数字化信息的初始聚类中心后,将数字化信息b分割成大小完全相等的数据块b={b1,b2,b3,…,bt},然后利用sdclass算法实现数字化信息归并分类;绘制sdclass算法训练和分类流程图,sdclass算法训练和分类流程图中,l、u分别表示数字化信息中被标记的数据以及未标记的数据;
48、s3.1、构建归并分类器
49、将g个基础分类器组合在一起,得到归并分类器e=(e1,e2,…,eg);数据块b每完成一次训练,与之对应的分类器就训练一次;从数据块中找出已标记的数据实例作为测试数据块,用来测试归并分类器的分类精准度以及计算取值;
50、假设测试数据块b的类标签实际值为y,e估计b的类标签为计算e对b的估计准确率函数f(b),表达式如(10)所示:
51、
52、根据公式(10)得到e在b上的平均平方错误率:
53、
54、计算测试数据块的分类平均平方错误率,公式为:
55、
56、式中,ri(c)表示数据块类标签为label_c的先验概率;
57、对e的权值进行计算:
58、w(e)=mse(b)-mse(e) (13);
59、从g个基础分类器中选出具有较高权值的分类器构成归并分类器;
60、(2)数字化信息归并分类实现
61、利用基础分类器和归并分类器分别对测试数据块b进行分类操作,得到b的类标签的估计值为在对估计值进行加权处理后,计算其与簇中心之间的距离,选择最近的簇作为相应数据块的归并分类结果,完成基于半监督学习的数字化信息归并分类。
62、本发明的上述技术方案的有益效果如下:
63、本发明提供一种基于半监督学习的数字化信息归并分类算法,检测原始数字化信息中的概念漂移数据,滤除噪声数据,降低对后续分类结果精度的影响;利用半监督学习训练k均值聚类算法,利用训练后算法训练数据块,构建基础分类器,通过对目标函数求解获得最优聚类中心;构建基于sdclass算法的归并分类器,计算每个数据块类标签的估计值,以及估计值与簇中心间距离,找出最近的簇,将对应的数据块划分到该簇中,实现数字化信息的归并分类。选取6种不同类型的数据集对所提方法展开实验测试,结果表明,所提方法针对不同类型的数据集均可实现高精准分类,且具有较高的分类效率。
- 还没有人留言评论。精彩留言会获得点赞!