视频行为预测模型训练方法、预测方法、设备及存储介质与流程
本发明涉及人工智能,尤其涉及一种视频图像行为预测方法、系统、设备及存储介质。
背景技术:
1、图像特征现今常用于目标轨迹的建模和预测。在很多实例中,图像算法被用于有关人与人之或人与物品之间的运动行为和轨迹的追踪推理。另外一种图像特征学习的应用是多目标追踪,用于匹配不同帧中检测到的物体并加上标注。
2、有关图像的时间序列预测常用于对于多变量时间序列数据中变量关系进行建模,例如交通状况的预测,动作和手势确认。现在的一些解决跨时间的真实图像结构的预测的方法是基于图像和网络数据使用高斯进程回归、神经网络模型等,这些方法在训练过程中要求图像的所有节点都准确注册标记并且没有混乱,当图像数据不完整或者标记混乱时导致模型不能准确进行图像行为预测。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种视频行为预测模型训练方法、系统、设备及存储介质,旨在在视频图像数据不完整或者标记混乱时能够训练准确的视频行为预测模型。
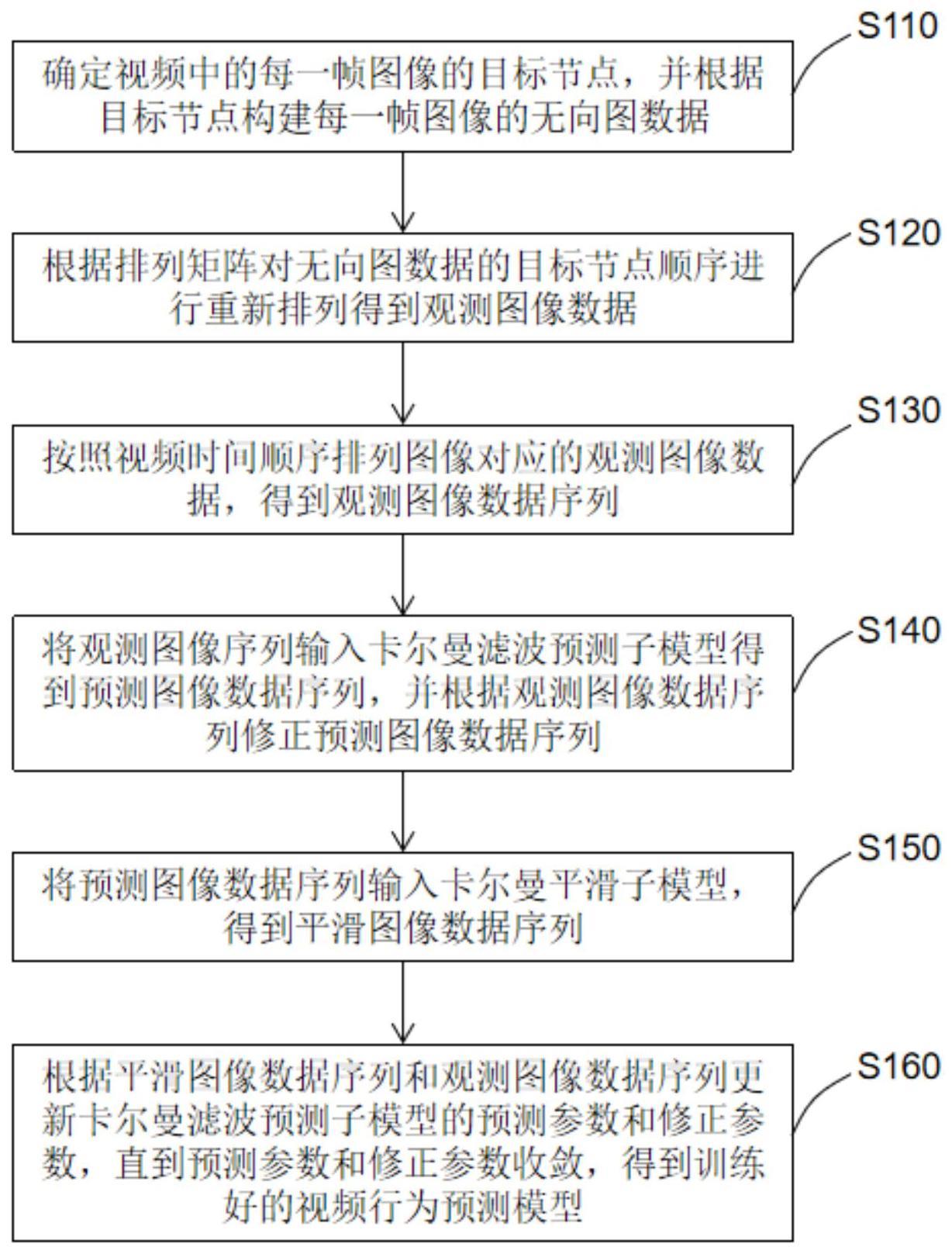
2、一方面,本发明实施例提供了一种视频行为预测模型训练方法,包括以下步骤:
3、确定视频中的每一帧图像的标记节点,并根据标记节点构建每一帧图像的无向图数据;
4、根据排列矩阵对所述无向图数据的标记节点顺序进行重新排列得到观测图像数据;
5、按照视频时间顺序排列图像对应的观测图像数据,得到观测图像数据序列;
6、将所述观测图像数据序列输入卡尔曼滤波预测子模型得到预测图像数据序列,并根据所述观测图像数据序列修正所述预测图像数据序列;
7、将所述预测图像数据序列输入卡尔曼平滑子模型,得到平滑图像数据序列;
8、根据所述平滑图像数据序列和所述观测图像数据序列更新所述卡尔曼滤波预测子模型的预测参数和修正参数,直到所述预测参数和修正参数收敛,得到训练好的视频行为预测模型。
9、根据本发明一些实施例,所述确定视频中的每一帧图像的标记节点,并根据标记节点构建每一帧图像的无向图数据包括以下步骤:
10、采用边界框标注每一帧图像中的物体以作为标记节点,并对边界框进行注释;
11、采用线性插值方法填补视频中所有帧的边界框;
12、根据图像中的所有边界框构建每一帧图像的无向图数据,其中,所述无向图数据包括边矩阵和属性矩阵,所述边矩阵由表示标记节点间关系的邻接矩阵映射得到,所述属性矩阵用于表征标记节点的坐标位置。
13、根据本发明一些实施例,所述根据排列矩阵对所述无向图数据的标记节点顺序进行重新排列得到观测图像数据包括以下步骤:
14、获取排列矩阵集合,其中,所述排列矩阵集合包括所有无向图数据对应的n×n排列矩阵p,n为无向图数据中标记节点的数量,排列矩阵为置换矩阵;
15、根据每一个无向图数据对应排列矩阵对所述无向图数据的边矩阵和属性矩阵进行映射以对标记节点顺序重新排列,得到观测图像数据。
16、根据本发明一些实施例,所述将观测图像数据序列输入卡尔曼滤波预测子模型得到预测图像数据序列,并根据所述观测图像数据序列修正所述预测图像数据序列包括以下步骤:
17、将所述观测图像数据序列中的观测图像数据依次输入卡尔曼滤波预测子模型的动力系统进行预测得到预测图像数据,根据多个预测图像数据得到预测图像数据序列;
18、将所述预测图像数据对应的时刻的观测图像数据修正所述预测图像数据,根据多个修正后的预测图像数据,得到预测图像数据序列。
19、根据本发明一些实施例,所述动力系统表示为:
20、
21、其中,w表示边矩阵,v表示属性矩阵,(e)、(n)分别代表关于边和关于节点的模型,b和c均表示动力系统的参数,ut为随机的标准正态分布的系统噪声。
22、根据本发明一些实施例,所述排列矩阵在所述无向图数据的映射表示为:
23、(p,x)=(p,(w,v))=(p*w,pv);
24、其中,x表示无向图数据,w表示边矩阵,v表示属性矩阵,p表示排列矩阵。
25、根据本发明一些实施例,所述视频行为预测模型训练方法还包括以下步骤:
26、当比较视频中标记节点数量分别为n1、n2的前后两张图象,则为两张图像的无向图数据引入空节点,以使两张图像的无向图数据标记节点总数均为n1+n2;
27、将其中一张图像的无向图数据的真实标记节点和另一张图像的无向图数据的空节点进行配对得到配对结果,配对结果表征诞生新的标记节点或者删除老的标记节点。
28、另一方面,本发明实施例还提供一种视频行为预测方法,包括以下步骤:
29、获取待预测的视频数据;
30、对所述视频数据进行预处理得到无向图数据序列;
31、将所述无向图数据序列输入如前面实施例所述的视频行为预测模型,得到视频行为预测结果。
32、另一方面,本发明实施例还提供一种电子设备,包括:
33、至少一个处理器;
34、至少一个存储器,用于存储至少一个程序;
35、当所述至少一个程序被所述至少一个处理器执行,使得至少一个所述处理器实现如前面实施例所述的视频行为预测模型训练方法或者视频行为预测方法。
36、另一方面,本发明实施例还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如前面实施例所述的视频行为预测模型训练方法或者视频行为预测方法。
37、本发明上述的技术方案至少具有如下优点或有益效果之一:首先确定视频中的每一帧图像的标记节点,并根据标记节点构建每一帧图像的无向图数据,然后根据排列矩阵对无向图数据的标记节点顺序进行重新排列得到观测图像数据,以减少图像中标记节点标记混乱的情况。按照视频时间顺序排列图像对应的观测图像数据,得到观测图像数据序列,然后将观测图像数据序列输入卡尔曼滤波预测子模型得到预测图像数据序列,并根据观测图像数据序列修正预测图像数据序列,再将预测图像数据序列输入卡尔曼平滑子模型,得到平滑图像数据序列,根据平滑图像数据序列和观测图像数据序列更新卡尔曼滤波预测子模型的预测参数和修正参数,直到预测参数和修正参数收敛,得到训练好的视频行为预测模型。本发明在视频图像数据不完整或者标记混乱情况下爱仍然能够训练准确的视频行为预测模型,从而实现视频行为的准确预测。
技术特征:
1.一种视频行为预测模型训练方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的视频行为预测模型训练方法,其特征在于,所述确定视频中的每一帧图像的标记节点,并根据标记节点构建每一帧图像的无向图数据包括以下步骤:
3.根据权利要求2所述的视频行为预测模型训练方法,其特征在于,所述根据排列矩阵对所述无向图数据的标记节点顺序进行重新排列得到观测图像数据包括以下步骤:
4.根据权利要求3所述的视频行为预测模型训练方法,其特征在于,所述将观测图像数据序列输入卡尔曼滤波预测子模型得到预测图像数据序列,并根据所述观测图像数据序列修正所述预测图像数据序列包括以下步骤:
5.根据权利要求4所述的视频行为预测模型训练方法,其特征在于,所述动力系统表示为:
6.根据权利要求3所述的视频行为预测模型训练方法,其特征在于,所述排列矩阵在所述无向图数据的映射表示为:
7.根据权利要求1所述的视频行为预测模型训练方法,其特征在于,所述视频行为预测模型训练方法还包括以下步骤:
8.一种视频行为预测方法,其特征在于,包括以下步骤:
9.一种电子设备,其特征在于,包括:
10.一种计算机可读存储介质,其中存储有处理器可执行的程序,其特征在于,所述处理器可执行的程序被由所述处理器执行时用于实现如权利要求1至7任一项所述的视频行为预测模型训练方法或者如权利要求8所述的视频行为预测方法。
技术总结
本发明公开一种视频图像行为预测方法、系统、设备及存储介质,涉及人工智能技术领域。训练方法包括根据每一帧图像的标记节点构建每一帧图像的无向图数据;根据排列矩阵对无向图数据的标记节点顺序进行排列得到观测图像数据;将基于视频时间顺序的观测图像数据序列输入卡尔曼滤波预测子模型得到预测图像数据序列,并根据观测图像数据序列修正所述预测图像数据序列;将预测图像数据序列输入卡尔曼平滑子模型,得到平滑图像数据序列;根据平滑图像数据序列和观测图像数据序列更新预测子模型的预测参数和修正参数,直到预测参数和修正参数收敛,得到视频行为预测模型。本发明在视频图像数据不完整或者标记混乱时能够训练准确的视频行为预测模型。
技术研发人员:尤学强,唐林涛,唐惠琼,郑建超,张小刚,汪鱼洋,王刚,蒋飞,何寒冰
受保护的技术使用者:珠海中科慧智科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!