基于机器阅读理解的关键科技实体抽取方法及系统
本技术涉及自然语言处理,具体是涉及基于机器阅读理解的关键科技实体抽取方法及系统。
背景技术:
1、在信息爆炸的互联网时代,学术论文数量与信息数据总量一起迎来了指数级的增长。根据斯坦福大学于2021年发布的ai index报告,ai领域在2020年便已经出版了超过25万篇论文。同时,截止于2021年,google scholar收录的数据量也已经超过了2.4亿,且该数量仍在持续增长中。面对如此海量的学术论文,科研工作者很难快速获取论文的主旨内容,因此科研工作者不得不花费大量时间与精力查阅论文。
2、学术论文作为在某一领域理论或应用中取得新进展的信息载体,必然存在着创新因素。从结果的角度看,学术论文是科研成果的凝聚,而摘要是学术论文的重要组成部分。学术论文的摘要是对论文内容不加注释和评论的简短陈述,旨在不涉及过多细节的前提下简明扼要地说明研究目的、研究方法和研究结论等内容。摘要作为学术论文的精炼描述,蕴含着学术论文中的关键信息,如研究的问题、使用的方法等,这些也是科研工作者在获取学术信息时最为关心的核心内容。通过对摘要中蕴含关键信息的抽取,可以提高科研工作者获取学术论文主要内容的效率,以节省科研工作者在论文检索和阅读等环节所花费的时间。研究者围绕着学术论文摘要信息抽取开展了大量的研究。
3、学术论文摘要中的关键信息可以以实体的形式进行归纳分类与抽取,抽取得到实体被统称为关键科技实体。学术论文摘要中有许多关键信息以实体的形式存在,如研究的问题、使用的方法与数据集、得到的指标结果等,这些实体都可被归类为关键科技实体。学术论文摘要中的实体抽取需要对大量长摘要文本进行数据标注,而长摘要文本会带来标注工作量过大,噪音数据过多等问题,因此有必要对学术论文摘要内容先进行一次摘要内容汇总,总结归纳出摘要中的重要信息,并在重要信息中进行关键科技实体抽取,以解决上述的问题。
技术实现思路
1、本技术的目的是为了克服上述背景技术的不足,提供一种基于机器阅读理解的关键科技实体抽取方法及系统。
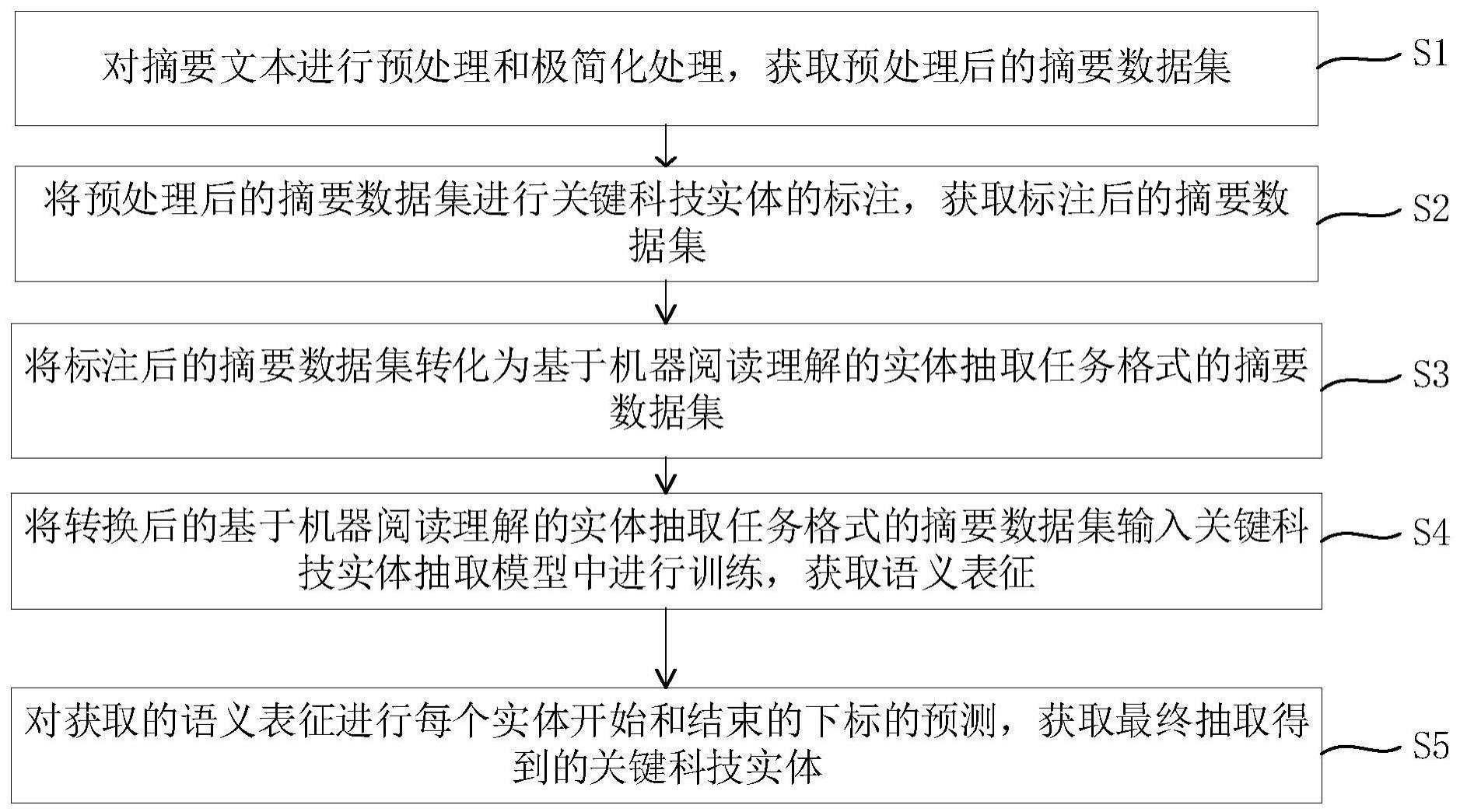
2、第一方面,提供基于机器阅读理解的关键科技实体抽取方法,包括以下步骤:
3、基于机器阅读理解的关键科技实体抽取方法
4、根据第一方面,在第一方面的第一种实现方式中,所述对摘要文本进行预处理和极简化处理,获取预处理后的摘要数据集步骤,具体包括以下步骤:
5、剔除摘要数据集中无研究价值的摘要数据,获取第一轮预处理后的摘要数据集;
6、将第一轮预处理后的摘要数据集使用tldr模型进行极简化处理,获取第一轮极简化后的摘要数据集;
7、将第一轮极简化后的摘要数据集中未能充分获取原始摘要文本中的重要信息部分的摘要数据删除,获取第二轮预处理后的摘要数据集;
8、将第二轮预处理后的摘要数据进行极简化处理,获取第二轮极简化后的摘要数据集作为预处理后的摘要数据。
9、根据第一方面,在第一方面的第二种实现方式中,所述将预处理后的摘要数据集进行关键科技实体的标注,获取标注后的摘要数据集步骤,具体包括以下步骤:
10、将预处理后的摘要数据集使用bart标注平台基于bioes标注体系对预处理后的摘要数据集进行标注,获取标注后的摘要数据集。
11、根据第一方面,在第一方面的第三种实现方式中,所述将标注后的摘要数据集转化为基于机器阅读理解的实体抽取任务格式的摘要数据集步骤,具体包括以下步骤:
12、将标注后的摘要数据集构建问题、答案和文本的三元组数据集;
13、基于规则匹配和摘录方法构建包含问题实体、方法实体和三元组数据集的词典,以此获取基于机器阅读理解的实体抽取任务格式的摘要数据集。
14、根据第一方面,在第一方面的第四种实现方式中,所述将转换后的基于机器阅读理解的实体抽取任务格式的摘要数据集输入关键科技实体抽取模型中进行训练,获取语义表征步骤,具体包括以下步骤:
15、构建基于bert和机器阅读理解(mrc)的关键科技实体抽取模型;
16、将转换后的基于机器阅读理解的实体抽取任务格式的摘要数据集输入基于bert和机器阅读理解(mrc)的关键科技实体抽取模型中,获取摘要数据集的语义表征。
17、根据第一方面的第四种实现方式,在第一方面的第五种实现方式中,所述将转换后的基于机器阅读理解的实体抽取任务格式的摘要数据集输入关键科技实体抽取模型中进行训练,获取语义表征步骤,具体包括以下步骤:
18、将问题和极简摘要文本链接,并在问题的首部和尾部分别加入[cls]标签和[sep]标签,获取新句子;
19、将新句子输入词嵌入层,将句子中每个单词以及标签通过bert进行预训练,获取词向量;
20、在得到的词向量结果基础上,添加一层注意力表示层,将词典和极简摘要文本进行匹配,赋予词典中专业词汇以权重,构.成新向量;
21、应用注意力机制于所述新向量,使用softmax函数计算特征矩阵k和v的相关性,获取权重值;
22、将所有的权重值进行加权求和,获取基于注意力机制的专业词汇特征向量;
23、将获取的专业词汇特征向量与词嵌入层进行融合,获取摘要数据集的语义表征。
24、根据第一方面,在第一方面的第六种实现方式中,所述对获取的语义表征进行每个实体开始和结束的下标的预测,获取最终抽取得到的关键科技实体步骤,具体包括以下步骤:
25、对获取的语义表征的每个实体对应的开始下标和结束下标使用二分器进行预测,获取开始上标和结束下标;
26、通过二分类模型获取开始上标和结束下标的匹配工况;
27、当匹配时,获取最终抽取得到的关键科技实体。
28、第二方面,本技术提供了一种基于机器阅读理解的关键科技实体抽取系统,包括预处理模块、标注模块、转换模块、训练模块和关键科技实体获取模块。预处理模块用于对摘要文本进行预处理和极简化处理,获取预处理后的摘要数据集;标注模块与所述预处理模块通信连接,用于将预处理后的摘要数据集进行关键科技实体的标注,获取标注后的摘要数据集;转换模块与所述标注模块通信连接,用于将标注后的摘要数据集转化为基于机器阅读理解的实体抽取任务格式的摘要数据集;训练模块与所述转换模块通信连接,用于将转换后的基于机器阅读理解的实体抽取任务格式的摘要数据集输入关键科技实体抽取模型中进行训练,获取语义表征;关键科技实体获取模块与所述训练模块通信连接,用于对获取的语义表征进行每个实体开始和结束的下标的预测,获取最终抽取得到的关键科技实体。
29、根据第二方面,在第二方面的第一种实现方式中,所述预处理模块,包括:
30、第一预处理单元,用于剔除摘要数据集中无研究价值的摘要数据,获取第一轮预处理后的摘要数据集;
31、第一极简处理单元,与所述第一预处理单元通信连接,用于将第一轮预处理后的摘要数据集使用tldr模型进行极简化处理,获取第一次极简化后的摘要数据集;
32、第二预处理单元,与所述移动极简处理单元通信连接,用于将第一次极简化后的摘要数据集中未能充分获取原始摘要文本中的重要信息部分的摘要数据删除,获取第二轮预处理后的摘要数据集;
33、第二极简处理单元,与所述第二预处理单元通信连接,用于将第二轮预处理后的摘要数据进行极简化处理,获取第二次极简化后的摘要数据集。
34、根据第二方面,在第二方面的第二种实现方式中,所述标注模块,具体包括:
35、标注单元,与所述预处理模块通信连接,用于将预处理后的摘要数据集使用bart标注平台基于bioes标注体系对预处理后的摘要数据集进行标注,获取标注后的摘要数据集。
36、本技术的有益效果为:
37、本技术将学术论文摘要进行了极简化处理,即对学术论文摘要中的重要信息进行了保留,同时减少了学术论文摘要中的噪音信息,并大幅降低了学术论文摘要标注的工作量,提高了数据集的构建效率;
38、本技术将基于机器阅读理解的实体抽取任务格式的摘要数据集输入关键科技实体抽取模型中进行训练,获取语义表征,对学术论文摘要中的语义进行了有效增强,提高了学术论文摘要中关键科技实体识别的准确度,有利于更好地从学术论文摘要中获取关键信息,提高科研工作者的工作效率。
- 还没有人留言评论。精彩留言会获得点赞!