一种闪电实时三维定位方法
本发明涉及实时闪电定位,尤其涉及一种闪电实时三维定位方法。
背景技术:
1、闪电是严重的主要自然灾害之一,可引起森林和油库火灾、造成供电及通讯信息系统故障或损坏,对航天航空、矿山及一些重要而敏感的高技术装备等具有重大威胁。八十年代以后,闪电引起的危害显著增加,特别是与高新技术关系密切的领域,如航空航天、国防、通讯、电力、计算机、电子工业等由于广泛应用对闪电电磁干扰极为敏感的大规模及超大规模集成电路致使遭雷击的几率大大增加。
2、闪电实时三维定位业务的开展能对雷电活动进行及时预警,从而减小闪电对人身财产的危害。闪电定位算法的优劣直接影响着闪电定位结果的精度和定位效率,因此发展新的闪电定位算法和技术是当前非常迫切的任务。
3、目前闪电实时三维技术面临三个问题:
4、首先,闪电三维定位计算精度受到观测站环境噪声影响,而大多数环境噪声频域较宽,难以采用常规的频域滤波器将其滤除,严重影响脉冲匹配,从而影响定位精度,所以亟需提升闪电原始信号质量。论文《alow frequency 3d lightning mapping network innorth china》(《atmospheric research》(2021))中将各个观测站中规律性的环境噪声脉冲进行拟合,采用滑动互相关识别的方式,将与所拟合的噪声脉冲匹配度较高的闪电信号脉冲进行归零处理,这种方法一定程度上可以减少噪声脉冲的干扰,但需要人工对噪声脉冲进行鉴定,并且滑动匹配也加大了滤波处理的计算量,滤波效率较低。同时,如果相关系数设置不当,容易造成无效滤波或过度滤波的情况。论文《anew method ofthree-dimensional location for low-frequency electric field detectionarray》(《journal ofgeophysical research》(2018))则采用emd对闪电原始信号进行处理,在一定程度上克服了环境噪声的影响,但是emd在imf分解的时候可能会存在模态混叠的现象,而且分解imf需要迭代多少步也没有明确的标准。
5、其次,许多科研团队中常常采用levenberg-marquardt(lm)算法对初始三维闪电定位初始计算结果进行拟合优化《北京闪电综合探测网(blnet):网络构成与初步定位结果》(《大气科学》(2015)),但lm属于一种“信赖域”算法,对初始结果的精度具有较高的依赖性。当闪电辐射源定位初始解精度较低时,lm算法的拟合效率将大为降低。若采用网格搜索的定位算法《一种改进的网格搜索闪电定位算法》(《计算机工程与应用》(2016))很容易得到高精度结果,但是计算量非常大,计算时间长。
6、最后,对于闪电实时定位技术,数据采集需与后端数据处理速度的匹配尤为重要,当出现强雷暴天气,数据采集频繁,非常容易导致采集卡数据堵塞,造成闪电定位系统不稳定的情况。所以面对大规模数据实时处理需要引入可靠的计算引擎确保实闪电定位系统数据采集的稳定性、数据的可靠性、数据分析处理的低延迟性。
7、如何解决上述问题,是本发明面临的课题。
技术实现思路
1、本发明的目的在于提供一种闪电实时三维定位方法。
2、为了实现上述发明目的,本发明采用技术方案具体为:
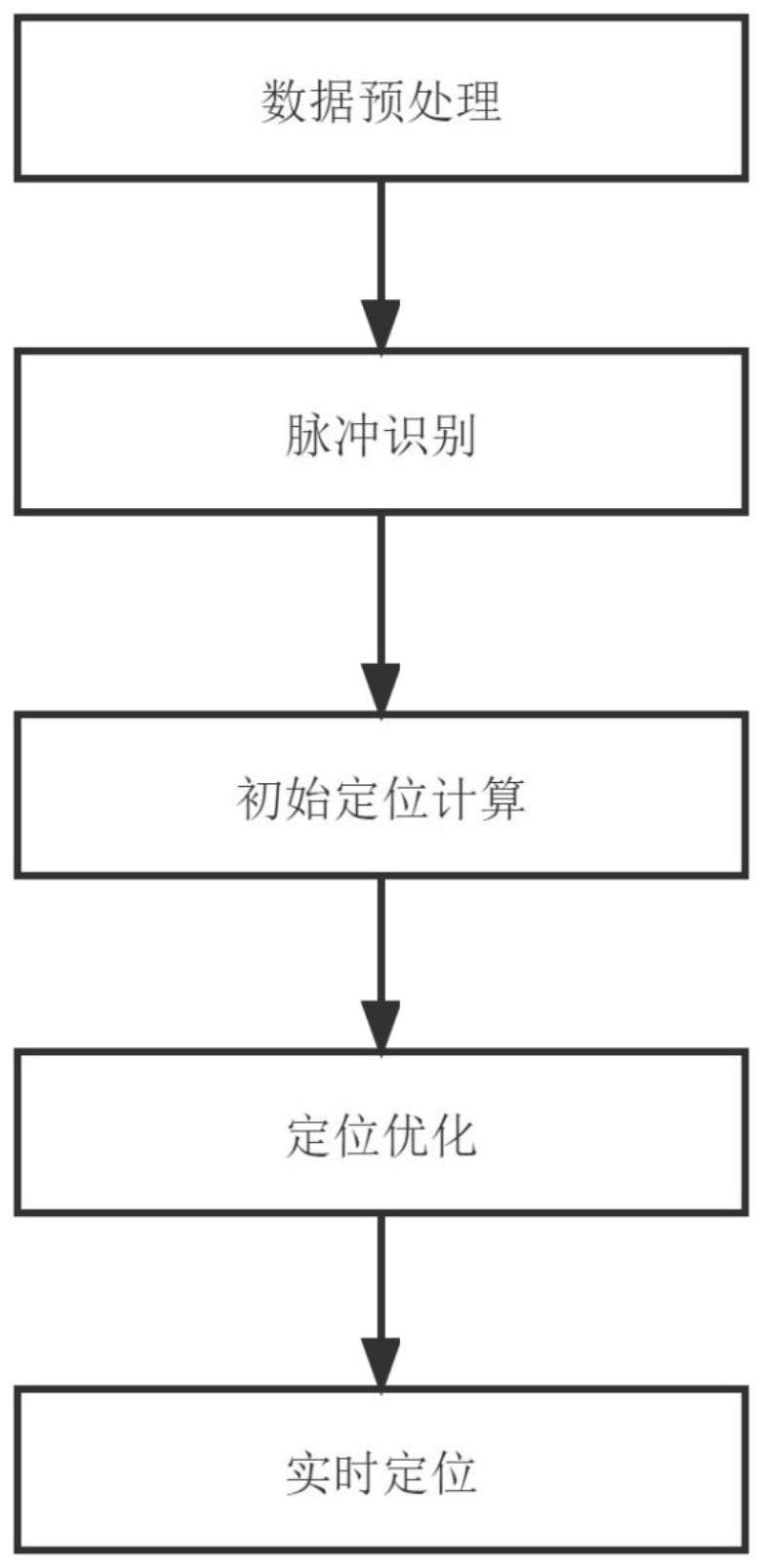
3、一种闪电实时三维定位方法,方法包括以下步骤:
4、s1:数据预处理,对收集到的电场信号进行预处理;包括去噪与归一化操作,以减小噪声对识别的影响。
5、s2:脉冲识别,用支持向量机进行二分类,将信号分为脉冲信号和非脉冲信号;
6、在进行定位计算之前,需要先通过脉冲匹配来确定每个测站检测到的脉冲信号是相同的辐射源发出的;这是一个关键的前处理步骤,确保在计算闪电源位置时使用了正确的数据。
7、采用机器学习方法对脉冲进行识别。机器学习方法采用支持向量机模型、决策树模型、神经网络模型。
8、s3:初始定位计算,利用三角测量的方法,基于多站时间差测量(time differenceof arrival,tdoa)原理测量信号到达多个接收站之间的时间差,并使用chan氏定位算法计算闪电源的初始位置;
9、s4:优化算法求解,采用差分进化算法对步骤s3中得到的初始定位结果进行优化,获取准确的闪电源位置;
10、s5:实时定位,利用apache spark分布式计算框架对数据进行实时处理和分析,同时采用边缘计算技术降低传输延迟,提高实时的闪电定位性能。
11、步骤s2包括:
12、s21:特征提取:对步骤s1中预处理后的电场信号进行特征提取,选择时域、频域或时频域特征(包括峰值、均值、能量、频谱特征),进行特征选择方法(包括逐步回归和主成分分析(principal component analysis,pca))处理,得出最终特征作为支持向量机的输入,用于训练分类器;
13、s22:数据标注:通过实际观测数据,对电场信号进行标注;将信号分为闪电脉冲信号:正类,和非闪电脉冲信号:负类;
14、s23:训练支持向量机分类器:使用步骤s22中标注好的电场信号训练支持向量机分类器,得出一个最优的超平面,将正类信号和负类信号分开,支持向量机的目标函数可以表述为:
15、minimize:
16、subject to:yi·(wtxi+b)≥1-ξi,i=1,...,n
17、ξi≥0
18、其中,w是权重向量,b是偏置项,xi是输入特征向量,yi是对应的标签+1或-1,ξi是松弛变量,c是惩罚参数;t为转置矩阵,n为总样本量;
19、机器学习中,标签即为预期的模型输出,是对样本类别的标识方法。在二分类任务中,即本发明的“正类信号和负类信号”分类问题中,设两类样本的标签分别为+1、-1。
20、s24:使用核函数:为了解决非线性问题,引入核函数将原始特征空间映射到高维空间(比原始特征空间维度更高的维度)。使用的核函数包括线性核、多项式核、径向基函数核(radial basis function,rbf)。
21、rbf核函数的形式为:
22、k(xi,xj)=exp(-γ||xi-xj||2)
23、其中,γ是rbf核函数的参数;xi和xj是输入样本,||xi-xj||表示欧氏距离(即样本之间的距离)。
24、使用rbf核函数相比线性核和多项式核的好处主要如下:
25、(1)非线性建模能力:rbf核函数能够处理非线性关系。相比线性核和多项式核,rbf核函数具有更强的非线性建模能力,可以更好地捕捉数据中的复杂模式和结构。
26、(2)参数调节:相比多项式核,rbf核函数只有一个参数γ需要调节。这使得模型的参数调节相对简单,并且更容易通过交叉验证等方法找到合适的参数值。
27、s25:预测脉冲信号:使用训练好的支持向量机分类器对新的电场信号进行分类;对于步骤s22中标注好的电场信x,预测结果可以通过如下公式计算:
28、f(x)=wt·φ(x)+b
29、其中,φ(x)是核函数将输入信号映射到高维空间后的特征向量;如果f(x)>0,那么信号x被分类为脉冲信号;如果f(x)<0,被分类为非脉冲信号;
30、s26:设置合适的时间窗口和阈值,匹配不同测站测得的相同辐射源脉冲:
31、s261:设置时间窗口:为了正确匹配不同测站测得的相同辐射源脉冲,设置一个合适的时间窗口;时间窗口应根据信号传播速度和测站之间的距离来确定,即辐射源到两个测站的时间差小于光速在这两个测站所传播的时间。
32、s262:寻峰阈值:计算电场信号脉冲的累积概率分布,并设置一个寻峰阈值;当累积概率达到99%时,将相应的幅值作为寻峰阈值;
33、s263:定位脉冲选取:在时间窗口内,寻找幅值最大的电场信号作为定位脉冲;对于间隔超过15μs的脉冲,根据幅值的分布情况,选择一个合适的百分比阈值的电场信号作为定位脉冲;
34、s264:互相关法脉冲匹配:使用互相关法进行脉冲匹配;设定时间窗口350μs,滑动步长50μs,计算时间窗口内各测站之间的电场信号的互相关函数;互相关函数表示为:
35、rxy(τ)=∑(x(t)·y(t+τ))
36、其中,x(t)和y(t)分别表示两个测站的电场信号,τ表示时间延迟。
37、s27:找到互相关函数的峰值所对应的时间延迟;互相关函数的峰值表示两个信号之间的最大相似性;通过找到峰值所对应的时间延迟,以此匹配不同测站测得的相同辐射源脉冲;阈值设定0.8,以确定两个信号是否来自同一个辐射源;如果互相关函数的峰值大于阈值,则认为这两个信号来自同一个辐射源;将所有测站的定位脉冲进行两两匹配,得到脉冲组合。
38、步骤s3具体包括:
39、s31、设定位系统有h个测站,分别用si(xi,yi,zi)表示,其中i=1,2,...,h;令s1为主站,其他为辅站;闪电辐射源的空间位置为p(x,y,z)。
40、s32、计算主站和辅站之间的时间差:
41、δti=ti-t1
42、其中,i=2,3,...,h;ti是闪电辐射源到达第i个测站的时间。
43、s33、根据时间差计算距离差:
44、δdi=c·δti
45、其中,i=2,3,...,h;c是光速;
46、s34、构建超时差方程组:
47、(x-xi)2+(y-yi)2+(z-zi)2-(x-x1)2-(y-y1)2-(z-z1)2=δdi2
48、其中i=2,3,...,h;
49、s35、简化方程组,消去平方项,得到线性方程组:
50、a·x=b
51、其中,
52、a=[2(x2-x1),2(y2-y1),2(z2-z1);
53、2(x3-x1),2(y3-y1),2(z3-z1);
54、....;
55、2(xn-x1),2(yn-y1),2(zn-z1)]
56、x=[x,y,z]t
57、b=[δd22+x12+y12+z12-x22-y22-z22;δd32+x12+y12+z12-x32-y32-z32;...;δdn2+x12+y12+z12-xn2-yn2-zn2]
58、s36、使用迭代最小二乘法(ils)求解线性方程组,得到闪电辐射源的初始位置估计:
59、p(x,y,z)=(at·a)-1·at·b
60、对chan氏定位算法进行创新以提高闪电源初始位置计算的准确性:
61、(1)引入加权最小二乘法(wls)
62、当测站之间的距离和信号传播条件存在较大差异时,可以使用加权最小二乘法(wls)来对不同测站的测量误差进行加权处理。这样可以根据测站的信号质量或距离来为每个方程分配权重,从而提高定位结果的准确性。
63、(2)采用高阶多项式拟合
64、在非线性情况下,可以考虑使用高阶多项式拟合方法替代线性方程组来求解闪电源位置。这种方法可以更好地处理非线性情况下的超时差方程组,从而提高定位结果的准确性。
65、步骤s4中采用差分进化算法de对初始定位结果进行优化,以获得更精确的闪电源位置
66、s42初始化:随机生成包含v个解向量的初始种群,每个解向量具有d个维度;设置算法参数,变异因子f、交叉率cr和最大迭代次数t;
67、s42变异操作:对于每个解向量xi,从种群中随机选择三个不同的解向量r1、r2和r3计算差分向量:vi=r1+f*(r2-r3),其中r1、r2和r3互不相同,且与xi大小方向均不同;
68、s43交叉操作:对于每个解向量xi,根据交叉率cr和差分向量vi生成试验向量ui;在d个维度中,对每个维度j执行以下操作:
69、生成随机数randj,取值范围为[0,1];
70、如果randj≤cr或j等于随机整数(随机整数的范围为[1,d]),则设置ui[j]=vi[j];
71、否则,设置ui[j]=xi[j];
72、选择操作:对于每个解向量xi,计算其适应度值f(xi)和试验向量ui的适应度值f(ui)。如果f(ui)≤f(xi),则用ui替换xi;否则保留解向量xi
73、收敛检查:检查是否达到最大迭代次数t;如果达到,则输出最优解;否则,返回步骤s42继续迭代。
74、步骤s5具体为:
75、spark应用程序在一个分布式集群上启动,其由driver program(驱动程序)组成。driver program(驱动程序)创建一个sparkcontext,它是应用程序和spark集群之间的主要连接。
76、s51、数据划分与任务分配:设收集到的闪电数据集为d,将d分成k个子集:d1,d2,...,dk;每个子集被分配给一个计算节点,以实现数据的分布式处理;设计算节点集合为
77、其中表示第i个计算节点;
78、所收集到的数据集d是由spark应用程序接收到从各测站收集到数据。在这些计算节点上,spark应用程序将操作(transformations和actions)应用于分布式数据,这些操作包括数据清洗、去噪、特征提取。spark将这些操作转化为有向无环图(dag),然后被dag调度器划分为一系列阶段(stages),每个阶段由一系列任务(tasks)组成。
79、任务调度器将这些任务分配到各个executor上运行。这些executor在工作节点(worker node)上运行,每个executor都有一定数量的核和内存。
80、数据在集群中的节点之间进行分区,并在需要时通过网络进行传输。
81、s52、实时数据处理与分析:每个计算节点将根据所分配的子数据集di进行实时数据处理与分析;为实现实时处理,分布式计算框架会根据系统资源动态调整处理速度;设处理速度为p,数据处理函数为f,那么在时间t内,第i个计算节点处理的数据量可以表示为:pi(t)=|f(di)|;
82、s53、边缘计算技术:降低后续数据处理的复杂度。通过在数据产生的源头(例如测站)部署边缘计算设备,降低传输延迟;设边缘计算设备集合为e,其中ei表示第i个边缘计算设备;边缘计算设备可在数据产生时进行初步处理(包括滤波与去噪操作),降低后续数据处理的复杂度;设边缘计算处理函数为g,那么边缘计算设备处理后的数据集表示为:d'=g(d);边缘计算处理函数是一种在边缘计算设备上执行的数据预处理操作,主要用于在数据源(例如测站)附近对数据进行初步处理,以减少后续数据处理的负担和降低网络传输延迟。具体的边缘计算处理函数可以包括以下操作:
83、s531数据清洗:包括对原始数据进行去噪与去除异常值操作,以提高数据质量;
84、s532数据压缩:通过有损或无损压缩算法减小数据的体积,以降低传输延迟和存储成本;
85、s533特征提取:从原始数据中提取有用的特征,以降低数据维度并减少计算复杂度;
86、executor执行任务后,将结果发送回driver program。driver program收到所有任务的结果后,会进行数据聚合以进行全局分析,并计算闪电源的实时定位结果。
87、s54:数据聚合与结果计算:计算节点处理后的数据需汇总以进行全局分析;设数据汇总函数为h,那么汇总后的数据表示为:dagg=h(p1(t),p2(t),...pk(t));h是对每个数据求平均值的操作,即:
88、
89、p1、p2....pk是在k个子集上得到的k个闪电的位置,
90、基于计算得到的dagg,计算闪电源的实时定位结果。设闪电定位函数为l,那么实时定位结果表示为:l(t)=l(dagg);
91、基于apache spark实现实时定位的流程如下:
92、spark应用程序(由driver program组成)在一个分布式集群上启动。
93、spark会创建一个sparkcontext对象,这是与集群的主要连接。
94、在创建sparkcontext之后,应用程序会将操作(transformations和actions)应用于分布式数据,通常是从hdfs或其他数据源加载的。
95、spark会将操作转化为一系列阶段(stages),每个阶段都由一系列任务(tasks)组成。这些任务由taskscheduler调度并在executor上运行。
96、这些executor在工作节点上运行,每个executor都有一定数量的核和内存。
97、数据在集群中的节点之间进行分区,并通过网络进行传输。
98、当所有任务完成时,应用程序结束。
99、与现有技术相比,本发明的有益效果为:
100、(1)增强的脉冲识别精度:利用支持向量机(svm)等机器学习方法对脉冲进行识别,具有更强的泛化能力,相比于传统方法可以提高脉冲识别的准确性。这有助于在定位过程中使用正确的数据,从而提高定位结果的准确性。
101、(2)优化的定位结果:通过差分进化算法(de)对初始定位结果进行优化,以获得更精确的闪电源位置。遗传算法(ga)和差分进化算法(de)的引入使得解决方案具有全局搜索能力,能够在解空间内寻找最优解,从而提高定位精度。这使得定位结果更加精确,有助于提高闪电监测和预警的准确性。
102、(3)高效的实时处理能力:采用分布式计算框架(如apache spark或flink)和边缘计算技术对数据进行实时处理和分析,降低传输延迟,提高实时的闪电定位性能。这种并行数据处理和近源预处理的方式能够快速处理大量数据,保证闪电监测系统在面对大量数据时仍然能够高效运行,从而提高系统效率。
- 还没有人留言评论。精彩留言会获得点赞!