一种时序数据的模糊表示及聚类方法
本发明涉及一种时序数据的表示和聚类,尤其涉及一种时序数据的模糊表示及聚类方法。
背景技术:
1、时序数据的表示和聚类面临着挑战,这是由于时序数据不同于常规数据,具有如下特点:
2、(1)数据量大,数据维度高,并且数据量随时间增长。
3、(2)关联性,时序数据是有序的,时序数据按照时间顺序排列,具有明显的时间性质。这种有序性使得时序数据具有很强的相关性和依赖性,后一时刻的数据往往会受到前一时刻数据的影响。
4、(3)时序数据具有周期性,如股票价格、天气等。这种周期性往往会影响数据的分布和变化规律。
5、(4)时序数据具有趋势性,某些时序数据可能会受到长期趋势的影响,比如人口增长、经济增长等。
6、(5)时序数据的采集往往会受到各种因素的影响,如测量误差、数据采集设备的干扰等,会导致时序数据含有噪声和缺失值。
7、如上特点给时序数据的表示带来了困难和挑战,其中高维、高数据量意味着高计算量,要求算法有高效的计算速度,关联、周期和趋势等复杂特征无法使用传统的统计量和降维算法提取,同时数据中掺杂的噪声和缺失值会影响算法对数据模式的识别,进一步导致数据表示质量的下降。目前,在时序数据表示领域存在一些研究,如基于集合的表示方法deepsets,时间卷积网络tcn(temporal convolutional network)等算法,但是这些方法只在某些固定的场景下发挥出较好的性能,没有同时解决时序数据表示中存在的高维高数量级、复杂特征和噪声问题。
8、时序数据的聚类同样会受到数据高维度高数量级、复杂特征和噪声的影响,当使用表达作为聚类的特征提取环节时,是将经过表达后的特征输入到聚类算法中,得到聚类结果。这时,虽然聚类算法不需要关注数据噪声问题,并且经过表示后的特征相较于原始数据更为清晰,但是聚类算法要想得到好的结果,依旧需要对周期性、趋势性等模式的识别能力。因此,传统聚类算法即使使用高质量的表达数据作为数据集,对聚类质量的提升也有限。
技术实现思路
1、针对上述问题,本发明提供一种时序数据的模糊表示及聚类方法,使用平滑处理方法对数据进行降噪,在不改变数据特征的前提下大幅减弱噪声的影响。针对噪声、高维度高数量级和复杂特征问题,从模糊逻辑中汲取思路,对时序数据进行模糊表示,模糊逻辑由于其模糊化的表示方式,可以处理数据的不确定性和不完备信息,即时序数据中的噪声,并且由于模糊逻辑思想来源于对现实的抽象,其计算方式简洁,计算量不会随着数据量级和维度的增加而过度增长,同时这种抽象的表示方式适用于处理非线性、非单调的数据关系,在复杂特征的提取上具有优势。
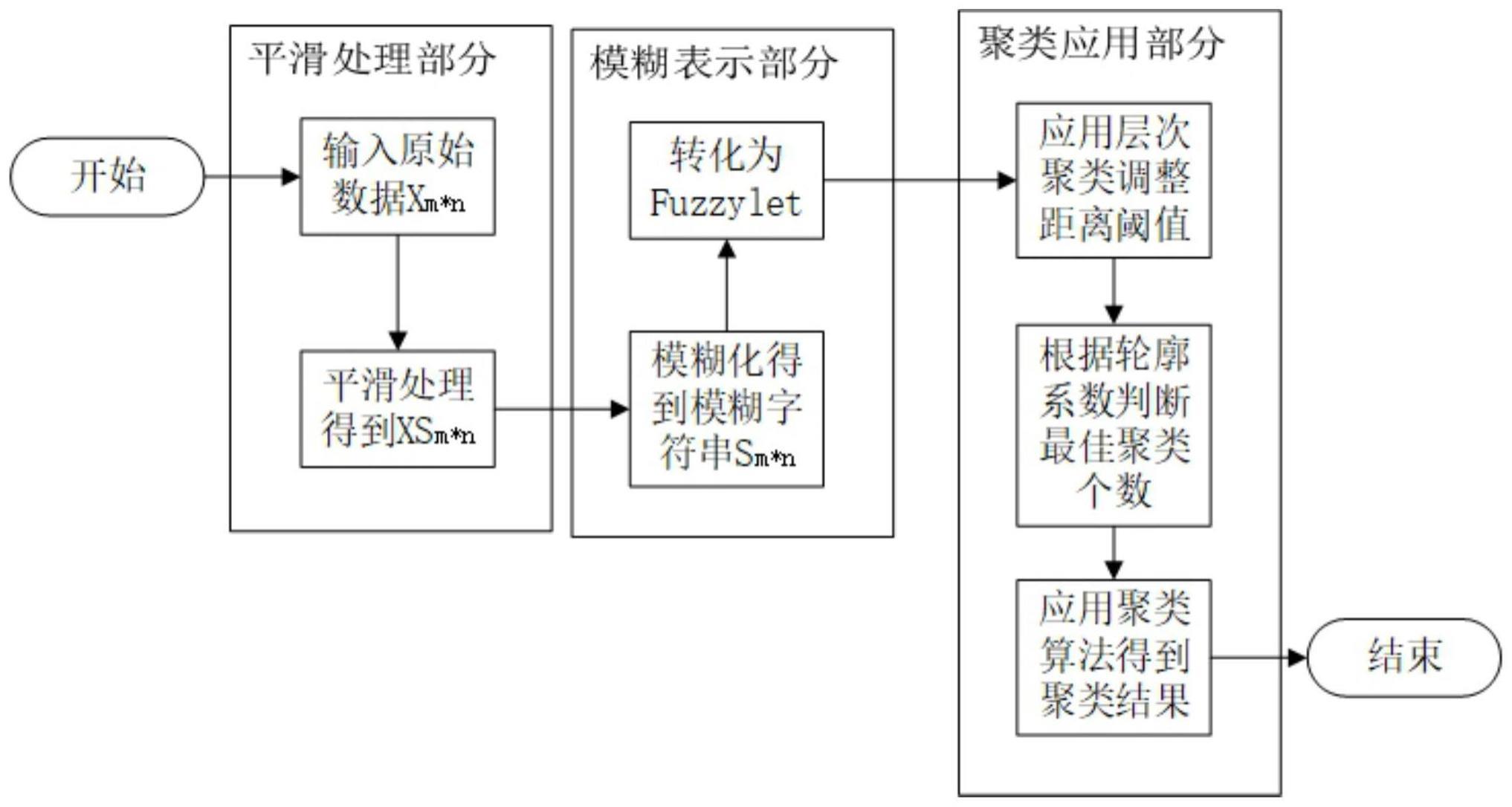
2、为实现上述目的,本发明公开了一种时序数据的模糊表示及聚类方法,包括以下步骤:
3、步骤s1、对原始时序数据集xm*n进行平滑处理,得到处理后的时序数据集xsm*n,其中,m表示样本数量,n表示各样本中的时间点;
4、步骤s2、通过隶属度函数对处理后的时序数据集xsm*n进行模糊化,得到模糊字符串集sm*n;
5、步骤s3、将模糊字符串集sm*n中的每个样本分段,得到每个样本的模糊子f,重复m次,得到模糊子集合fm*n;
6、步骤s4、通过层次聚类和轮廓系数,确定最佳聚类个数;
7、步骤s5、基于最佳聚类个数,分别通过k-means和birch聚类算法进行聚类,通过轮廓系数和ch指数对两个聚类结果进行评估,选取最优的评估结果作为聚类结果。
8、进一步的,所述步骤s1具体包括:
9、通过指数加权平均对原始时序数据集xm*n进行平滑处理,得到处理后的时序数据集xsm*n,具体的:
10、vt=β*v(t-1)+(1-β)θt
11、其中,m为数据集中的样本个数,n为每个样本中的时间点个数,vt为经指数加权平均处理后数据集在t时刻的值,vt∈xsm*n,θt为原始时序数据集xm*n的值,β∈(0,1)为可调节的超参数值。
12、进一步的,步骤s2具体包括:
13、步骤s21、针对每个样本,通过k-means算法,获取隶属度函数的边界值;
14、步骤s22、设定模糊变量的集合为q={l1,l2,…,lk},其中,k为模糊变量的个数;
15、步骤s23、通过隶属度函数,计算时序数据集xsm*n中每个时间点对应的模糊变量的隶属度,取隶属度最大的模糊变量作为当前时间点的隶属度数据,对其中的第i个样本进行处理,得到每个样本的模糊字符串si={j1,j2,…,jn},jn∈q,进而得到所有样本的模糊字符串集sm*n={s1,s2,…,sm}t。
16、进一步的,所述步骤s21具体包括:
17、针对每个样本,基于隶属度函数,设置簇中心个数,通过k-means算法对时序数据集xsm*n进行聚类,得到簇中心的值,即为隶属度函数的边界值。
18、进一步的,所述步骤s23具体包括:
19、所述隶属度函数为三角隶属度函数,包括:
20、
21、
22、
23、其中,μl(x),μm(x),μh(x)为低、中、高隶属度,x为样本时间点,a,b,c为边界值。
24、进一步的,所述步骤s23具体包括:
25、所述隶属度函数为梯形隶属度函数,包括:
26、
27、
28、
29、其中,μl(x),μm(x),μh(x)为低、中、高隶属度,x为样本时间点,a,b,c,d为边界值。
30、进一步的,所述步骤s3具体包括:
31、对模糊字符串集sm*n中每个样本的模糊字符串si中的时间点分段,设段长为u,得到g段模糊字符,若不能整除,则向下取整;
32、则模糊子f为:
33、f={v1,v2,…,vg}
34、其中,vg为第g段模糊字符对应的模糊子,
35、vg={|l1|,|l2|,…,|lk|}
36、其中,|lk|为第k个模糊变量在第g段中出现的次数。
37、进一步的,所述步骤s4具体包括:
38、基于模糊子集合fm*n,设定不同的距离阈值,使用层次聚类得到聚类结果,计算不同距离阈值下聚类结果的轮廓系数,选择轮廓系数最高的聚类结果对应的阈值距离,获取该阈值距离下的聚类数量,得到最佳聚类个数。
39、本发明的一种时序数据的模糊表示及聚类方法的有益效果为:使用平滑处理方法对数据进行降噪,在不改变数据特征的前提下大幅减弱噪声的影响。针对噪声、高维度高数量级和复杂特征问题,从模糊逻辑中汲取思路,对时序数据进行模糊表示,模糊逻辑由于其模糊化的表示方式,可以处理数据的不确定性和不完备信息,即时序数据中的噪声,并且由于模糊逻辑思想来源于对现实的抽象,其计算方式简洁,计算量不会随着数据量级和维度的增加而过度增长,同时这种抽象的表示方式适用于处理非线性、非单调的数据关系,在复杂特征的提取上具有优势。
- 还没有人留言评论。精彩留言会获得点赞!