一种数字人教师多模态大语言模型预训练学科语料库的构建方法
本发明涉及人工智能,可应用于元宇宙、虚拟数字人等场景,具体涉及一种数字人教师多模态大语言模型预训练学科语料库的构建方法。
背景技术:
1、在教育领域,数字化技术的应用已经成为一种趋势,其中包括教育数字人学科(educational digital humanities)的发展。教育数字人学科涵盖了学习、教育、教学方法和资源的数字化分析和研究,以提高教育质量和学习效果。为了进行教育数字人学科领域的研究和应用,构建一个专门针对该领域的语料库非常重要。语料库是指收集和组织大量文本数据以供研究和应用使用的资源。然而,在教育数字人学科领域内找到合适的语料数据并构建一个完备的语料库是一项具有挑战性的任务。
2、在现有技术中,教育数字人学科语料库的构建往往是一个耗时且人力成本高昂的过程。传统的方法涉及手动收集、标注和组织语料数据,这需要大量的时间和专业知识。此外,由于教育数字人学科的特殊性,一般的语料库构建方法无法满足该领域的特定需求。
技术实现思路
1、本发明涉及一种数字人教师多模态大语言模型预训练学科语料库的构建方法,旨在提供一种高效、准确且多模态的语料库构建方法,以满足教育领域数字人教师的学科需求。该方法通过多模态数据的采集和处理,结合预训练模型的应用,构建适用于数字人教师的学科语料库。本发明的数字人教师多模态大模型预训练学科语料库构建方法可以提供更加准确和全面的学科语料资源,为数字人教师的学习、教育和研究提供有力支持。同时,该方法可以降低语料库构建的成本和人力投入,提高语料库的利用效率和可持续发展性。
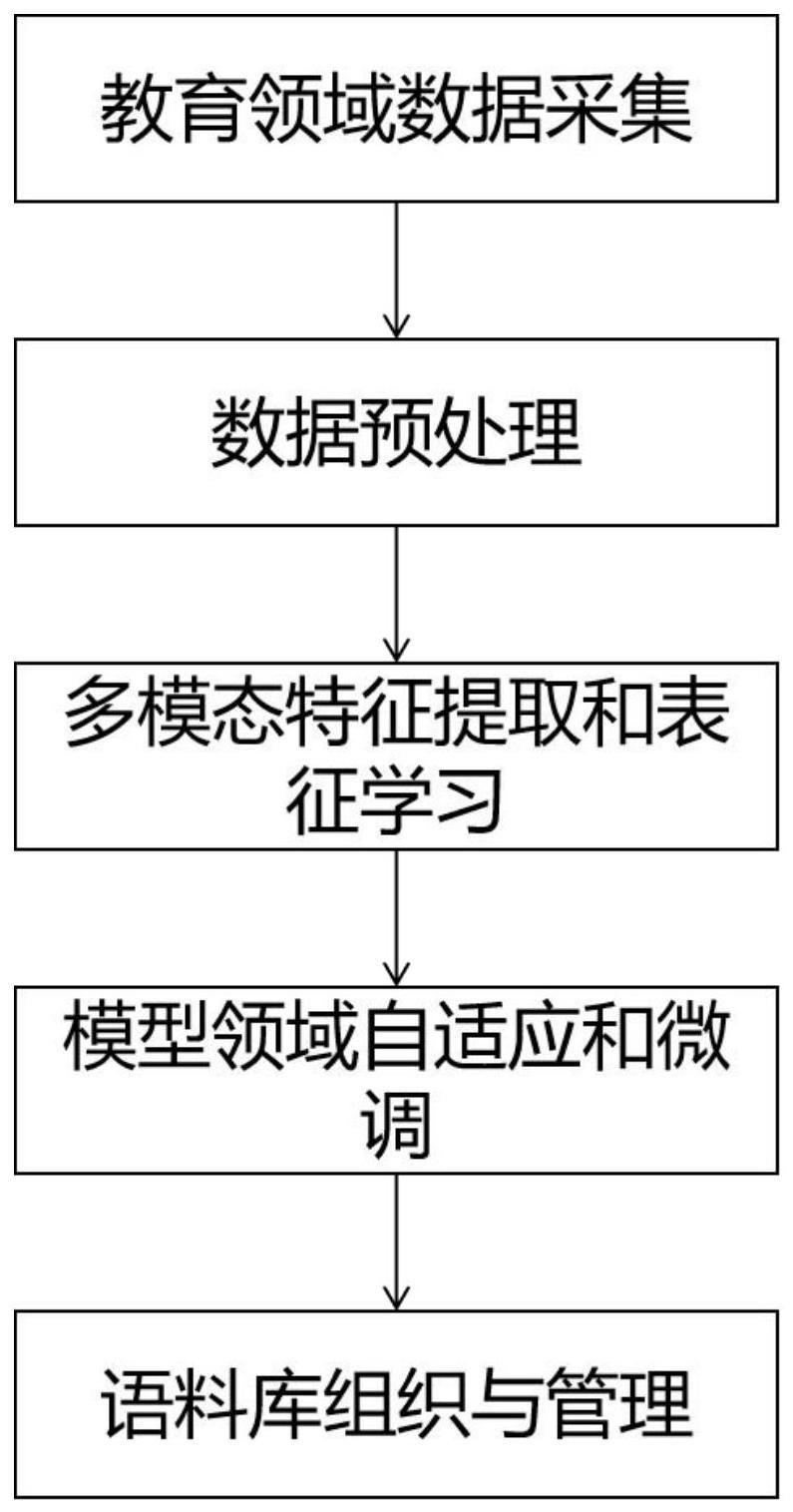
2、具体而言,本发明的一种数字人教师多模态大语言模型预训练学科语料库的构建方法,包括以下步骤:
3、(1)数据收集:从各种学科相关的文献、教材、课程资料、学术期刊、网站收集学科相关的多模态数据,包括文本、图像、音频,这些数据来源涵盖了教育数字人学科的相关领域和内容;
4、(2)数据预处理:对收集到的数据进行预处理,分为对文本数据、图像数据、音频数据的处理,以准备后续的标注和划分工作;
5、(3)多模态特征提取和表征学习:基于深度学习的模型对多模态数据进行特征提取和表征学习;
6、(4)模型领域自适应和微调:根据学科的特点和需求,对预训练模型进行领域自适应和微调,以提高模型在数字人教师学科任务上的性能和适应性;
7、(5)语料库组织与管理:根据语料数据划分的结果,将语料数据组织成一种结构化的语料库形式,以便后续的语料库检索和应用。
8、进一步的,步骤(1)数据收集包括如下步骤:
9、1.1从各种学科相关的文献、教材、课程资料、学术期刊、网站收集学科相关的多模态数据,包括文本、图像、音频,设收集到的文本数据来源为图像数据来源为音频数据来源为各个来源的相关度为其中n1+n2+n3表示数据来源的总数,ci表示数据来源si的相关度,j表示所有数据来源的索引,∑jcj表示对所有数据来源的相关度求和,则每个来源的权重可以通过以下公式计算:
10、
11、1.2综合考虑各个数据来源的权重,采用加权平均的方式将不同来源的原始语料数据进行融合,得到一个初始的语料库数据集,设从各个来源收集到的原始语料数据为d={d1,d2,...,dn},初始语料库数据集通过加权平均的方式计算:
12、dtotal=∑iw(si)*di,其中1≤i≤n
13、通过以上公式,计算出初始语料库数据集,其中dtotal表示最终得到的初始语料库数据集。
14、进一步的,步骤(2)数据预处理包含对文本数据、图像数据、音频数据的处理,包括如下步骤:
15、2.1文本数据预处理
16、2.1.1去除标点符号:使用正则表达式或预定义的标点符号列表,将文本中的标点符号去除或替换为空格;
17、2.1.2去除停用词:使用自然语言处理库nltk(natural language toolkit)中的停用词列表,通过遍历文本中的单词并与停用词列表进行比较,将匹配的停用词(如"the"、"is"、"and"等)移除;使用nltk提供的stopwords.words('english')来获取英文停用词列表,并结合列表推导式和条件判断实现去除停用词的操作,以减少对分析和建模的影响;
18、2.1.3词干提取或词形还原:使用nltk库中的词干提取器(porterstemmer)对文本中的单词进行处理,遍历文本中的单词,并应用相应的词干提取,将单词转换为其原始形式;
19、2.2图像数据预处理
20、2.2.1格式转换:将图像数据转换为特定格式的png格式,以保持兼容性;
21、2.2.2图像增强:通过opencv库对采集的图像应用图像处理技术,主要进行对比度增强、色彩校正、图像平滑等统一操作,以提高图像质量和视觉特征的可辨识度;
22、2.2.3目标检测和裁剪:使用目标检测算法yolo进行目标检测和裁剪,使用已经训练好的yolo模型,通过调用相应的函数实现目标检测,并提取目标的位置信息,然后根据目标的位置信息,使用图像处理库中的函数裁剪出特定对象或区域;
23、2.3音频数据预处理
24、2.3.1格式转换:将音频数据转换为特定的mp3格式,确保一致性和兼容性;
25、2.3.2降噪处理:应用高斯滤波算法来减少背景噪声对语音信号的影响;
26、2.3.3特征提取:从音频中提取mel频谱特征以供后续的语音分析和建模使用;
27、通过以上步骤,可以获得预处理后的多模态数据,设预处理后的文本数据为d′text,图像数据为d′image,音频数据为d′audio。
28、进一步的,步骤(3)多模态特征提取和表征学习包括如下步骤:
29、在多模态任务中,不同模态的数据(文本、图像和音频)包含了丰富的信息,通过提取它们的特征和学习它们的表征,可以更好地捕捉数据的语义和视觉特征,从而提升后续任务的性能,具体步骤如下:
30、3.1文本数据特征提取和表征学习
31、针对文本数据的特征提取和表征学习引入了一种改进的方法,结合预训练语言模型和自注意力机制来获取更具表达能力的文本表示,首先,通过预训练语言模型bert获取文本数据的嵌入表示,将其表示为文本嵌入矩阵,记作text_embeddings,
32、text_embeddings=bert(d′text)
33、嵌入矩阵text_embeddings捕捉了文本的语义信息和上下文关系;
34、然后采用自注意力机制sa对文本嵌入矩阵进行进一步的特征提取,自注意力机制允许文本中的每个词与其他词进行交互,根据它们之间的关系自动学习不同词之间的重要性权重,
35、self_attention=mha(text_embeddings)
36、t=sa(text_embeddings)
37、其中,self_attention表示自注意力机制;mha表示多头注意力机制模型,简写sa表示自注意力机制,t表示经过自注意力机制处理后的文本特征表示;
38、3.2图像数据特征提取和表征学习
39、在对图像数据进行预处理后,采用resnet作为卷积神经网络模型来提取图像的特征和学习其表征,resnet包含多个基本块,每个基本块包含一系列卷积层、批量归一化和激活函数,用于建立深层网络结构,在resnet的基本块中引入注意力机制,用于捕捉图像中不同位置之间的关联信息,在每个基本块的最后一个卷积层之后添加注意力模块,假设基本块的输入特征图为x,尺寸为h×w×c;
40、3.2.1特征映射计算
41、查询特征映射q:通过对输入特征图进行卷积操作,得到查询特征映射q,尺寸为h×w×c';
42、键特征映射k:通过对输入特征图进行卷积操作,得到键特征映射k,尺寸为h×w×c';
43、值特征映射v:通过对输入特征图进行卷积操作,得到值特征映射v,尺寸为h×w×c';
44、h和w表示特征图在空间维度上的高度和宽度,c表示特征图的通道数,而c'表示通过特征映射计算得到的新的特征映射的通道数;
45、3.2.2相似度计算:
46、对于每个像素位置(i,j),计算查询特征qi和键特征ki之间的相似度得分,使用点积操作得到相似度矩阵s,尺寸为h×w:
47、s(i,j)=qi·ki
48、3.2.3相似度归一化
49、对相似度矩阵s进行归一化,使用softmax函数将相似度得分转换为注意力权重a,尺寸为h×w:
50、a(i,j)=softmax(s(i,j))
51、3.2.4加权融合
52、将注意力权重a与值特征映射v相乘,并对乘积进行求和操作,得到基本块的注意力输出特征图i,尺寸为h×w×c':
53、i(i,j)=σ(a(i,j)·vi)
54、3.2.5特征映射变换
55、通过一个卷积层将注意力输出特征图i转换为与输入特征图x相同的通道数c,以便与后续的基本块相连接,
56、在每个基本块的最后一个卷积层之后,注意力模块通过计算相似度、归一化和加权融合的过程,对特征图进行自适应的特征加权,从而增强了基本块的表征能力;
57、3.3音频数据特征提取和表征学习
58、在卷积神经网络特征提取过程中,将mel频谱特征或mfcc系数作为输入,通过卷积层和池化层进行特征提取和降维,使用激活函数激活卷积层的输出,将最后一个卷积层的输出作为音频数据的特征表示,输入音频数据的mel频谱特征表示为xmel,维度为(m,n),其中m表示帧数,n表示特征维度;
59、对于第i个卷积核,卷积操作可以表示为:
60、ci=f(xmel*wi+bi)
61、其中,ci表示第i个卷积核的输出特征图,*表示卷积操作,wi表示第i个卷积核的权重参数,bi表示第i个卷积核的偏置参数;
62、对卷积输出进行激活函数处理,以增强特征表达能力:
63、ai=relu(ci)
64、最后一个卷积层的输出a即为音频数据的特征表示。
65、进一步的,步骤(4)模型领域自适应和微调包括如下步骤:
66、4.1特征融合
67、将不同模态的特征进行融合,以建立多模态特征表示,文本特征表示为t,图像特征表示为i,语音特征表示为a,采用以下公式进行特征融合:
68、fused_feature=concatenate(t,i,a)
69、fused_feature表示融合后的多模态特征表示,concatenate表示拼接文本、图像和语音特征;
70、4.2多任务学习
71、学科任务包括文本问题回答和图像问题回答,采用以下公式进行多任务学习:
72、loss=λ1*losstext+λ2*lossimage+λ3*lossaudio
73、综合考虑文本问题、图像问题和音频回答的损失函数,λ1、λ2和λ3为权重参数。
74、4.3迁移学习
75、根据数字人教师学科任务的特点和数据分布,对模型进行自适应,采用有监督训练或对抗训练技术,对数字人教师学科任务的标注数据,采用以下公式进行领域自适应:
76、loss=losspretrained+β*lossspecific
77、综合考虑预训练模型的损失和特定学科任务的损失,loss表示总体损失,用于衡量模型在预训练和特定学科任务上的表现,losspretrained表示预训练模型的损失,lossspecific表示特定学科任务的损失,β为权重参数。
78、进一步的,步骤(5)语料库组织与管理包括如下步骤:
79、5.1建立索引:
80、建立索引是提高语料库检索效率的重要步骤,索引是一种数据结构,用于快速查找和定位语料库中的文档或语料数据;
81、5.2设计查询接口:
82、为了方便用户对语料库进行检索,需要设计一个查询接口,查询接口是基于关键词搜索的,用户输入关键词,系统返回包含关键词的相关文档或语料数据,以及设计更高级的查询接口,可以基于语义查询,使用自然语言处理技术理解用户的查询意图,并提供更准确的结果;
83、5.3实现检索功能:
84、根据设计的查询接口,实现语料库的检索功能,通过索引和查询接口,快速检索语料库中的文档或语料数据,并返回与查询条件匹配的结果;
85、5.4组织语料数据:
86、根据划分与分类的结果和需求,将语料数据组织成一种结构化的形式,采用层次结构、目录结构或标签体系进行组织,以便用户能够根据学科、主题、难度级别进行浏览和访问,同时,可以对语料数据进行元数据的记录,以方便管理和检索;
87、5.5维护和更新:
88、定期对已构建的语料库进行维护和更新是保持语料库时效性和准确性的重要步骤,维护和更新操作包括添加新的语料数据,修正错误或更新旧数据,调整分类;同时还根据用户反馈和需求进行持续改进和优化。
89、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器运行所述计算机程序时,执行如上面所述的一种数字人教师多模态大语言模型预训练学科语料库的构建方法的步骤。
90、本发明还提供一种计算机可读存储介质,其存储计算机程序,所述计算机程序使得计算机执行上面所述的一种数字人教师多模态大语言模型预训练学科语料库的构建方法的步骤。
91、本发明的有益技术效果:
92、1、本发明的一种数字人教师多模态大语言模型预训练学科语料库的构建方法,通过采用自动化的方法进行教育数字人学科语料库的构建,提高了构建效率,降低语料库构建的成本和人力投入,提高语料库的利用效率和可持续发展性。
93、2、本发明的一种数字人教师多模态大语言模型预训练学科语料库的构建方法,可以提供更加准确和全面的学科语料资源,为数字人教师的学习、教育和研究提供有力支持。
94、3、本发明的一种数字人教师多模态大语言模型预训练学科语料库的构建方法,构建专属于教育数字人学科的学科语料库,能够更好地满足该领域的研究和应用需求,同时为教育数字人学科的发展和应用提供了重要的技术支持。
- 还没有人留言评论。精彩留言会获得点赞!