知识库构建方法及基于生成式大语言模型的问答对话方法和系统与流程
本发明涉及数据处理,特别涉及一种问答对话用文本知识库构建方法、及基于生成式大语言模型的文本知识库问答对话方法和系统。
背景技术:
1、近年来,大语言模型(如bert、gpt-3)的发展引起了广泛的关注和应用。大语言模型能够从大规模的文本数据中学习到丰富的语言知识和语境理解能力,不同类型的大语言模型可以应对不同类型的应用场景。比如属于自编码器模型(autoencoder models)的bert,这类模型通常包括编码器和解码器两个部分,编码器将输入文本转换为一个低维表示,解码器则将低维表示还原为原始文本,在文本动态向量化、分类标签、命名实体识别标签等应用场景上表现出色;而属于自回归模型(autoregressive models)的gpt-3这类模型,按照从左到右的顺序逐个生成单词或字符,在生成高质量的自然语言文本、自动文本摘要、对话系统等多个领域取得了重要的成果。知识库问答的主要任务是根据用户通过自然语言提出的问题,在结构化或者半结构化数据上完成查询、匹配,并将结果组合成自然语言形式返回给用户。其主要可看做由知识库的构建和基于自然语言的对话系统两大部分构成。
2、现有知识库问答的知识库构建部分,多采用从指定知识(即文本文件)中抽取的“实体a-关系-实体b”为基本单位的三元组来组成基于图结构的知识图谱。通常这一构建过程是半自动化的,即通过模型进行命名实体识别,自动抽取知识中的三元组添加进知识图谱中,再由人工纠正错误的、或添加未识别出来的三元组完善和提高该知识库的质量。然后基于自然语言对话的部分,同样对用户提出的问题进行命名实体识别,并将问题中的实体对知识库进行查询并给出答案。比如给定问题“中国的首都在哪里?”,会将其转化为(country:中国,capital_of_the_country:首都)进行查找并在知识库中匹配到三元组(country:中国,capital_of_the_country:首都,city:北京),从而给出答案“北京”。有的问答系统也会在知识图谱匹配的结果之上,通过全文索引或者向量相似度计算的方式,加上对原有知识文档的的查找结果,将匹配到的文档链接当做参考答案一并返给用户。即使知识图谱的答案不满足用户意图,用户可以再自行对相关文档进行查阅。然而,自然语言问题与知识库中的三元组存在语义鸿沟,即三元组关系在用户的自然语言问题中的可能有多种表达方式,使得实体名称存在歧义从而匹配出不准确或答非所问的答案,导致回复的准确率较低、用户体验差。
技术实现思路
1、为此,本发明提供一种问答对话用文本知识库构建方法、及基于生成式大语言模型的文本知识库问答对话方法和系统,解决现有知识库问答对话中图结构知识图谱构建耗时费力、匹配回复准确率低、用户体验差等情形。
2、按照本发明所提供的设计方案,提供一种问答对话用文本知识库构建方法,包含如下内容:
3、依据问答对话业务目标需求创建知识库名称及知识库中用于存储知识库文档数据的向量数据库库表存储结构,并将知识库元数据信息写入向量数据库,其中,知识库元数据信息包括知识库名称及预配置文本分割长度;
4、针对问答对话业务目标需求对应的文档文件,依据文档文件类型进行预处理,以获取文档文件中文本信息;并依据文本分割长度及文本终止符对文本进行分割,得到文档文件中文本信息所对应的若干文本块;
5、利用预训练大语言模型提取每个文本块对应的文本特征嵌入向量,并将文本块元数据信息及文本块对应的文本特征嵌入向量写入向量数据库中的库表存储结构,将向量数据库中存储的数据作为问答对话业务目标需求所需的知识库,其中,文本块元数据信息包括文档文件名称、文档连接、文本块原始文本和文本块在文档文件文本信息中的序号。
6、进一步地,依据文档文件类型进行预处理,以获取文档文件中文本信息,包含:
7、首先,判断文档文件类型,若为文字格式文件,则直接获取文档文件的纯文本信息;若为pdf或图片格式文件,则使用ocr技术识别并获取文档文件中的纯文本信息。
8、进一步地,依据文本分割长度及文本终止符对文本进行分割,得到文档文件中文本信息所对应的若干文本块,还包含:
9、判断分割后文本块的最后一个句子是否完整,如果不完整,则根据分割截断位置与句子终止符号两者之间的距离来舍弃该最后一个句子或补全该最后一个句子。
10、进一步地,所述向量数据库库表存储结构采用collection对象进行存储。
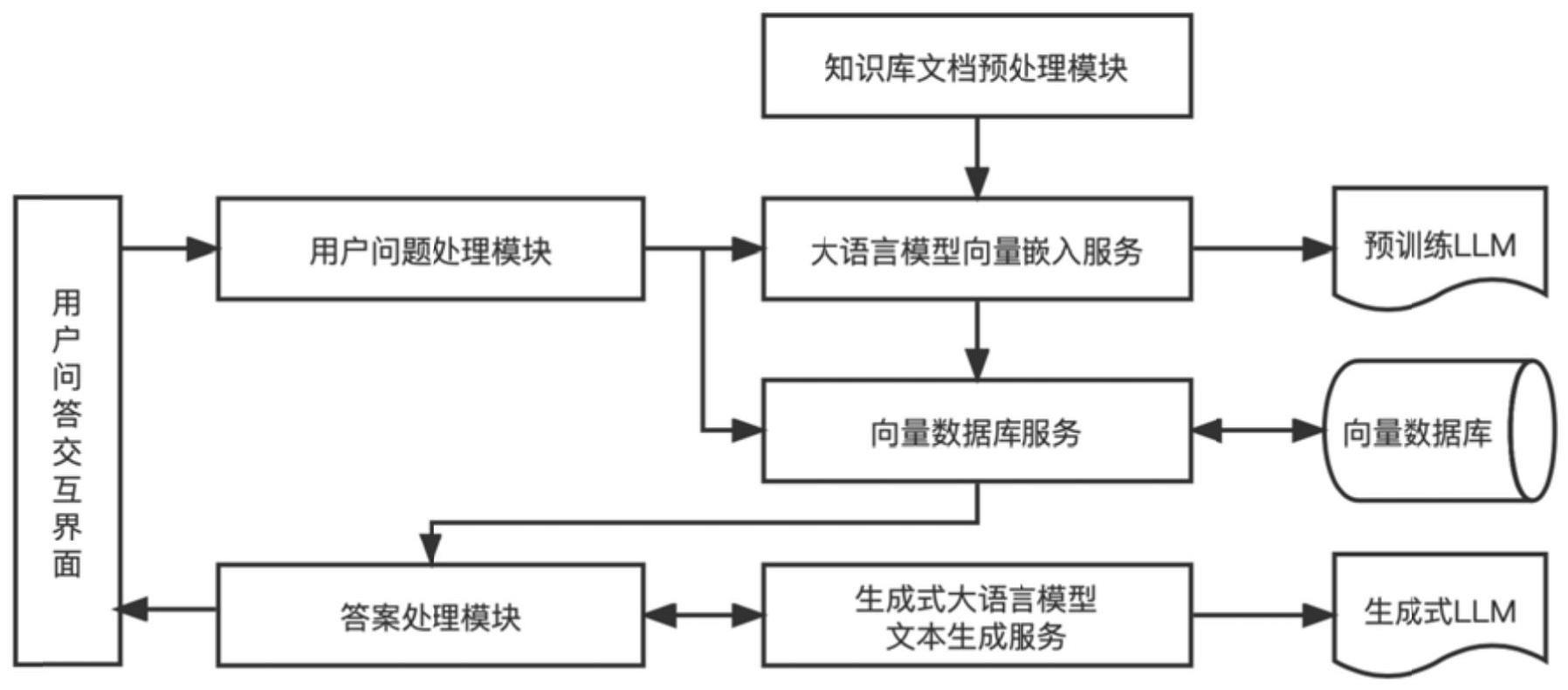
11、进一步地,本发明还提供一种基于生成式大语言模型的文本知识库问答对话方法,包含:
12、获取用户在输入栏输入的问题文本,利用第一预训练大语言模型获取问题文本的第一文本特征嵌入向量,其中,第一预训练大语言模型采用上述知识库构建过程中的预训练大语言模型;
13、针对第一文本特征嵌入向量,在上述所构建的知识库中查询语义最相近的目标文本块文本特征嵌入向量,并获取目标文本块序号前后的文本块;
14、利用目标文本块和目标文本块序号前后文本块组建引用知识,并整合引用知识和问题文本上下文;
15、将整合后的文本内容作为预训练生成式大语言模型输入,利用预训练生成式大语言模型来获取问题文本对应的响应文本,并将响应文本输出反馈给用户。
16、作为本发明基于生成式大语言模型的文本知识库问答对话方法,进一步地,在知识库中查询语义最相近的目标文本块文本特征嵌入向量,并获取目标文本块序号前后的文本块,包含:
17、首先,利用常用相似度计算方法计算出第一文本特征嵌入向量与知识库中文本块对应文本特征嵌入向量之间的相似度,依据相似度在知识库中选取对应地最接近的k个文本块作为目标文本块;
18、然后,查找每个目标文本块对应序号的前后l个文本块,以利用该前后l个文本块对目标文本块进行知识文本扩展。
19、作为本发明基于生成式大语言模型的文本知识库问答对话方法,进一步地,生成式大语言模型预训练过程,包含:
20、首先,采用开源社区生成式大语言模型作为基础模型;
21、然后,利用预先收集语料数据对基础模型进行微调训练,以获取用于问答对话的预训练生成式大语言模型。
22、进一步地,本发明还提供一种基于生成式大语言模型的文本知识库问答对话系统,包含:问题处理模块、语义匹配模块、知识构建模块和响应输出模块,其中,
23、问题处理模块,用于获取用户在输入栏输入的问题文本,利用第一预训练大语言模型获取问题文本的第一文本特征嵌入向量,其中,第一预训练大语言模型采用上述知识库构建过程中的预训练大语言模型;
24、语义匹配模块,用于针对第一文本特征嵌入向量,在上述所构建的知识库中查询语义最相近的目标文本块文本特征嵌入向量,并获取目标文本块序号前后的文本块;
25、知识构建模块,用于利用目标文本块和目标文本块序号前后文本块组建引用知识,并整合引用知识和问题文本上下文;
26、响应输出模块,用于将整合后的文本内容作为预训练生成式大语言模型输入,利用预训练生成式大语言模型来获取问题文本对应的响应文本,并将响应文本输出反馈给用户。
27、本发明的有益效果:
28、本发明无需对知识库文档进行实体要素和三元组信息的抽取以及进行图结构建模,利用大语言模型,提高对专业文档的语义特征嵌入能力,显著降低语义歧义问题,提高匹配答案的准确率,大大简化知识库构建的技术要求,减少建设知识库需要花费的工时;利用生成式大语言模型的强大的理解能力,通过将用户对话的上下文多轮问题提供给大语言模型,使问答对话系统可以理解和处理复杂的上下文信息,利用其强大的语言组织能力,对引用知识内容进行提炼摘要,把几大段的引用知识提炼出主要内容,并形成非常通顺的自然语言回答,提高用户体验;通过将冗余元数据信息存储在向量数据库,并在回答用户问题时将知识引用信息一并反馈给用户,从而让用户无需自行查找原始文档也可以知道答案内信息的来源,进一步强化并提升用户体验。
- 还没有人留言评论。精彩留言会获得点赞!