基于CSR编码的卷积计算加速器及加速方法
本发明属于芯片设计,具体涉及一种基于csr编码的卷积计算加速器及加速方法。
背景技术:
1、随着卷积神经网络的研究不断推进,其样本学习能力与目标分类能力随之不断增强,cnn在移动端和边缘端的多个应用场景中的部署规模也逐年增加。同时,随着应用场景和融入学科的增加,卷积神经网络的规模和计算复杂度也急剧增大。
2、传统的卷积神经网络应用方案主要采用将神经网络部署在云端,以处理终端采集数据,并将运算结果返回终端。但这种方法面临着实时性不足的问题。随着搭载神经网络并本地处理数据的物联网设备应用需求日益增长,网络部署实时性的问题显得愈加紧迫。因此,如何高性能、低功耗、且具备实时性地进行深层卷积神经网络的部署,已经成为各研究机构与相关企业的研究热点。同时由于卷积计算在卷积神经网络所占的比例高达百分之九十以上,如何高效实现卷积运算便成了在边缘数据部署卷积神经网络的一大重点。
3、卷积运算需要十分庞大的参数量,在边缘设备的存储空间将其所需的数据全部存起来是不可能的。基于此,相关研究人员提出了一张重启脉动阵列的思想,在卷积计算中采用脉动阵列的方式,可以通过大量的数据复用去减少设备的存储压力,也使得大规模并行计算卷积运算成为可能。文献一《bismo:a scalable bit-serial matrix multiplicationoverlay for reconfigurable computing》在脉动阵列结构的基础上,提出了一种位串行算法,将量化后的数据乘法分解成popcount操作和加法操作,去完成数据复用以及减少资源消耗去优化卷积运算。文献二《eyeriss:an energy-efficient recon-figurableaccelerator for deep convolutional neural networks》提出了一种eyeriss卷积神经网络加速器,其主要采用基于脉动阵列的可重构架构,同时为了避免卷积中的冗余计算,采用了csc编码方式,并且提出了行驻留的数据流方式去完成数据复用。
4、然而,上述文献一中的方法由于采用了位串行算法,因此只适用于经过低比特量化的数据,例如4bit以及以下的数据,无法适用于高并行卷积计算,同时也没有考虑到零所带来的冗余计算,使得算法功耗较大。文献二的方法虽然采用csc编码跳过了零的冗余计算,但是由于其提出的行驻留数据流,需要将相同id的数据匹配在一个时钟周期里,因此需要多级缓存结构去缓存数据,直到id匹配完全才全部读出,所造成的缓存压力较大。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于csr编码的卷积计算加速器及加速方法。本发明要解决的技术问题通过以下技术方案实现:
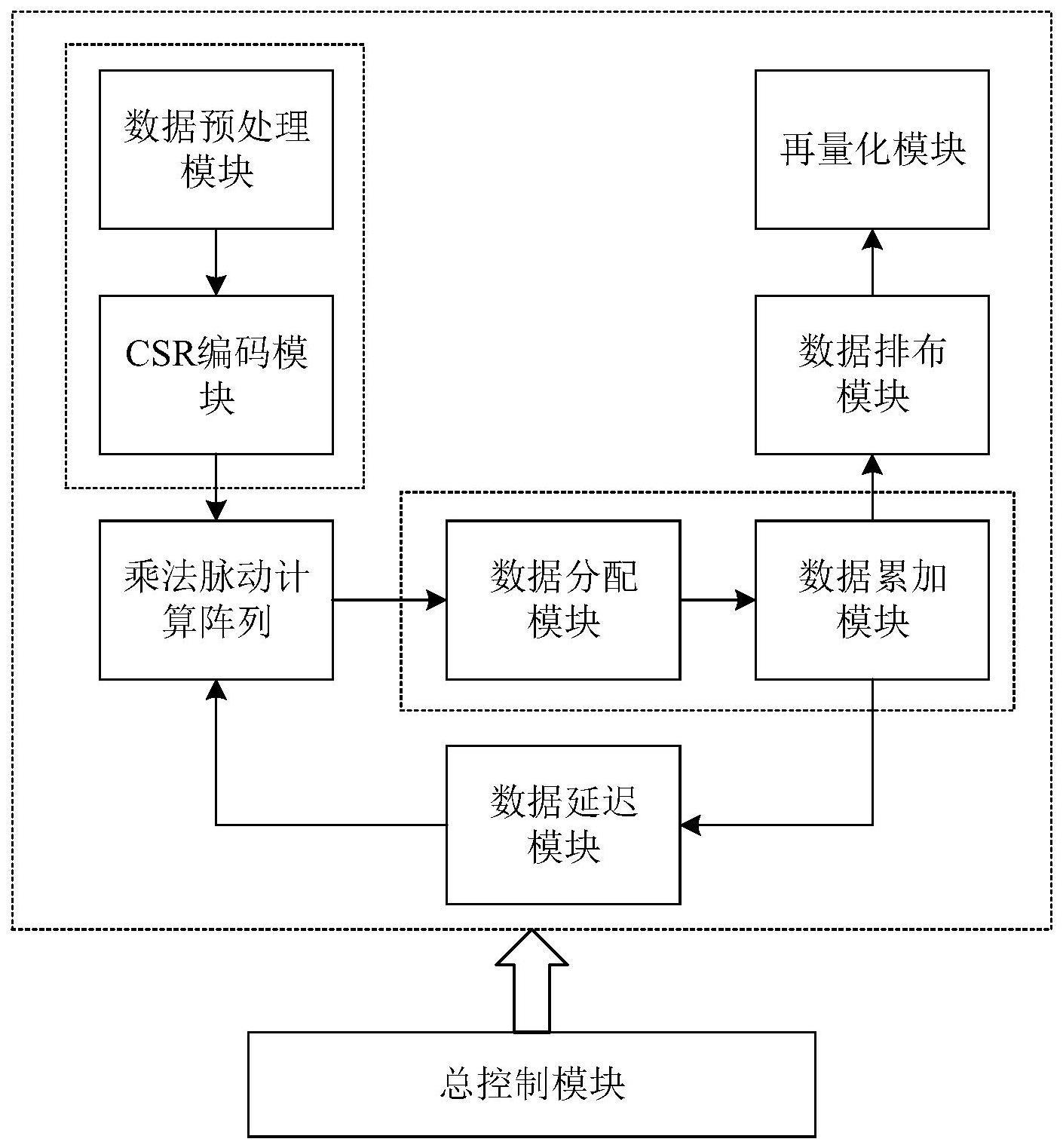
2、第一方面,本发明提供了一种基于csr编码的卷积计算加速器,包括:
3、数据预处理模块、csr编码模块、乘法脉动计算阵列、数据分配模块、数据累加模块、数据延迟模块、数据排布模块、再量化模块以及总控制模块;其中,
4、所述数据预处理模块用于通过dma从外部读取数据,并进行分块处理,得到分块后的数据;
5、所述csr编码模块用于对分块后的数据进行csr编码,得到特征数据及其对应的地址;
6、所述乘法脉动计算阵列用于根据所述地址对对应的特征数据和权重进行自然流动复用计算,并将计算结果传入所述数据分配模块;
7、所述数据分配模块用于将传入的计算结果划分为本窗口数据和跨窗口数据,分别传入所述数据累加模块中的相应累加单元进行数据累加;
8、所述数据延迟模块用于在判断所述数据累加模块发生加法写冲突时,向所述乘法脉动计算阵列反馈反压信号,以暂停当前工作,并在延迟数据相加完毕后重新启动当前工作;
9、所述数据排布模块用于对所述数据累加模块输出的累加数据进行整合并通过所述再量化模块重新映射位宽后,通过dma写进片外存储,以完成不连续输入数据的复用卷积计算;
10、所述总控制模块用于控制其余所有模块的调用和数据交互。
11、第二方面,本发明提供了一种基于csr编码的卷积计算加速方法,应用于上述实施例提供的基于csr编码的卷积计算加速器,包括以下步骤:
12、获取外部数据并进行分块预处理和csr编码,得到特征数据及其对应的地址;
13、基于脉动阵列通过所述地址对对应的特征数据和权重进行自然流动复用计算,并将计算结果划分为本窗口数据和跨窗口数据;
14、通过加法器复用分别对所述本窗口数据和所述跨窗口数据进行累加,并在判断发生加法写冲突时,通过反压控制暂停当前工作,并在延迟数据相加完毕后重新启动当前工作;
15、对累加数据进行整合和重新映射位宽后,写进片外存储,以完成不连续输入数据的复用卷积计算。
16、本发明的有益效果:
17、1、本发明提供的基于csr编码的卷积计算加速器通过对输入数据分块预处理节省了编码的额外开销,通过csr编码处理有效规避了神经网络卷积计算中的冗余部分,通过编码之后的脉动计算阵列以及后续的一系列处理完成了不连续输入数据的复用,通过数据延迟模块实现反压控制,解决了输入数据不连续所带来的加法写冲突;同时,通过将数据分为本窗口和跨窗口两部分数据节省了匹配数据所需要的存储大小,减少了片上存储的压力,降低了功耗,使得高并行卷积计算成为了可能;
18、2、本发明提供的基于csr编码的卷积计算加速器将预处理与csr编码与缓存封装在一起,利用乒乓操作节省了编码的时间开销;
19、3、本发明通过数据分类和模块复用节省了额外的面积开销,既实现了脉动阵列中的特征值复用和加法器复用,又可以享受到编码带来的去除零冗余计算的便捷。
20、以下将结合附图及实施例对本发明做进一步详细说明。
技术特征:
1.一种基于csr编码的卷积计算加速器,其特征在于,包括:数据预处理模块、csr编码模块、乘法脉动计算阵列、数据分配模块、数据累加模块、数据延迟模块、数据排布模块、再量化模块以及总控制模块;其中,
2.根据权利要求1所述的基于csr编码的卷积计算加速器,其特征在于,所述数据预处理模块和所述csr编码模块与数据输入通道的存储空间封装在一起并复制一次,以实现兵乓操作。
3.根据权利要求1所述的基于csr编码的卷积计算加速器,其特征在于,所述乘法脉动计算阵列采用编码数据横向流动、权重广播之后纵向流动的方式完成数据复用;其中,所述权重是根据卷积数据按照列排布的方式广播的。
4.根据权利要求3所述的基于csr编码的卷积计算加速器,其特征在于,所述乘法脉动计算阵列包括若干pe单元,每个pe单元均包括一个地址计算模块、一个流水线寄存器以及一个乘法器;其中,
5.根据权利要求1所述的基于csr编码的卷积计算加速器,其特征在于,所述数据分配模块在进行数据分配时,基于存储跨窗口数据的空间大小与窗口成正比,以及编码的额外开销位与窗口成反比的原则来设定窗口大小。
6.根据权利要求1所述的基于csr编码的卷积计算加速器,其特征在于,所述数据累加模块包括第一级加法器和第二级加法器,且所述第一级加法器可进行复用;其中,
7.根据权利要求6所述的基于csr编码的卷积计算加速器,其特征在于,所述第一级加法器包括本窗口累加单元和跨窗口累加单元;
8.根据权利要求6所述的基于csr编码的卷积计算加速器,其特征在于,所述卷积计算加速器还包括数据暂存模块,所述数据暂存模块连接所述第一级加法器中的跨窗口累加单元和所述第二级加法器;
9.根据权利要求8所述的基于csr编码的卷积计算加速器,其特征在于,所述数据暂存模块采用同步fifo实现。
10.一种基于csr编码的卷积计算加速方法,其特征在于,应用于如权利要求1-9任一项所述的基于csr编码的卷积计算加速器,包括以下步骤:
技术总结
本发明公开了一种基于CSR编码的卷积计算加速器,包括:数据预处理模块,用于从外部读取数据,并进行分块处理;CSR编码模块,用于对分块数据进行CSR编码,得到编码数据及其对应的地址;乘法脉动计算阵列,用于根据地址对对应的编码数据进行计算;数据分配模块,用于将计算结果划分为本窗口数据和跨窗口数据,并传入数据累加模块进行累加;数据延迟模块,用于在判断发生加法写冲突时,向乘法脉动计算阵列反馈反压信号,以暂停当前工作,并在延迟数据相加完毕后重新启动当前工作;数据排布模块,用于对累加数据进行整合并通过再量化模块重新映射位宽后,写入片外存储。该方法减少了片上存储的压力,降低了功耗,适用于高并行卷积计算。
技术研发人员:彭琪,陈纪宇,王一凡,朱樟明
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!