一种自适应数据分析与模型管理的方法和系统与流程
本发明涉及深度学习领域,且更为具体地,涉及一种自适应数据分析与模型管理的方法和系统。
背景技术:
1、深度学习是机器学习领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。在进行深度学习时需要训练神经网络模型,它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
2、现有技术中,不同类型的业务需要训练不同的神经网络模型,因此需要针对不同业务准备不同的样本数据,人工对样本数据进行拆解分析后开展神经网络模型训练,其中对大量样本数据进行分析拆解的过程耗时较长、效率较低,影响了神经网络模型的生成与应用。因此,需要一种能够自动对样本数据进行分析处理并高效完成神经网络模型训练的技术方案。
技术实现思路
1、为了解决上述技术问题,提出了本技术,以提供一种能够自动对样本数据进行分析处理并高效完成神经网络模型训练的自适应数据分析与模型管理的方法和系统。
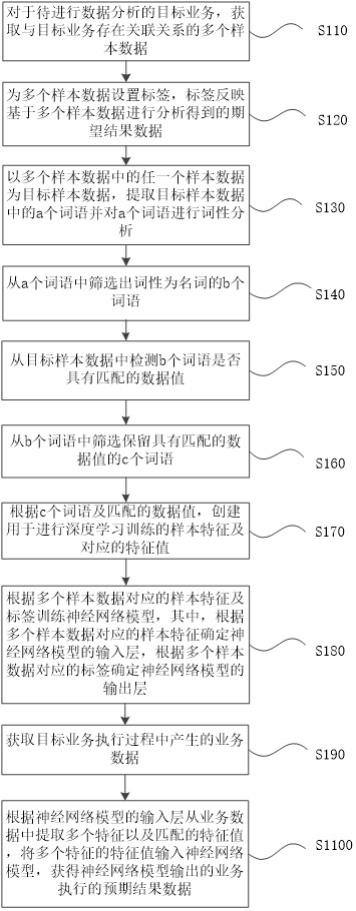
2、第一方面,本发明提供了一种自适应数据分析与模型管理的方法,包括:对于待进行数据分析的目标业务,获取与所述目标业务存在关联关系的多个样本数据;为所述多个样本数据设置标签,所述标签反映基于所述多个样本数据进行分析得到的期望结果数据;以所述多个样本数据中的任一个样本数据为目标样本数据,提取所述目标样本数据中的a个词语并对所述a个词语进行词性分析;从所述a个词语中筛选出词性为名词的b个词语;从所述目标样本数据中检测所述b个词语是否具有匹配的数据值;从所述b个词语中筛选保留具有匹配的数据值的c个词语;根据所述c个词语及匹配的数据值,创建用于进行深度学习训练的样本特征及对应的特征值;根据所述多个样本数据对应的样本特征及标签训练神经网络模型,其中,根据所述多个样本数据对应的样本特征确定所述神经网络模型的输入层,根据所述多个样本数据对应的标签确定所述神经网络模型的输出层;获取所述目标业务执行过程中产生的业务数据;根据神经网络模型的输入层从所述业务数据中提取多个特征以及匹配的特征值,将所述多个特征的特征值输入所述神经网络模型,获得所述神经网络模型输出的所述目标业务执行的预期结果数据。
3、优选地,前述的自适应数据分析与模型管理的方法,所述根据所述c个词语及匹配的数据值,创建用于进行深度学习训练的样本特征及对应的特征值的步骤包括:以所述c个词语的任一词语为候选样本特征,将所述候选样本特征的名称与预设的与所述目标业务对应的数据字典中记录的多个标准特征的名称进行比较,在所述候选样本特征的名称与所述数据字典中任一标准特征的名称相同或相似度高于预设阈值时,将所述候选样本特征的名称修改为该标准特征的名称,并记录为所述目标样本数据的样本特征,其特征值为所述候选样本特征对应的数据值,其中,计算相似度的公式为
4、,
5、表示所述候选样本特征,表示所述数据字典中的任一标准特征,表示与之间的相似度,表示中的第个字符,表示中的第个字符,表示的长度,表示的长度,表示将中的前个字符修改为中的前个字符所需要的操作次数。
6、优选地,前述的自适应数据分析与模型管理的方法,所述将所述候选样本特征的名称修改为该标准特征的名称,并记录为所述目标样本数据的样本特征,其特征值为所述候选样本特征对应的数据值的步骤还包括:根据所述数据字典中预记录的与该标准特征对应的特征值规则,判断所述样本特征对应的特征值是否符合所述特征值规则,在判断结果为否时,将所述样本特征删除。
7、优选地,前述的自适应数据分析与模型管理的方法,所述为所述多个样本数据设置标签的步骤包括:对于所述多个样本数据中的每个样本数据,获取多个用户所提交的对于该样本数据的结果数据;计算所述多个用户中每个用户提交的结果数据相对于其他用户提交的结果数据之间的差距:
8、,
9、其中,表示所述多个用户中的一个用户提交的结果数据,表示所述多个用户中的任一其他用户提交的结果数据,表示所述多个用户中提交的结果数据相对于其他用户的结果数据之间的差距,表示所述多个用户中的其他用户的人数;将最小差距值对应的结果数据,设置为对应样本数据对应的标签的值。
10、优选地,前述的自适应数据分析与模型管理的方法,所述从所述b个词语中筛选保留具有匹配的数据值的c个词语的步骤还包括:计算所述c个词语中每个词语在所述多个样本数据中出现的频率,根据出现频率高低从所述c个词语中选择一个或多个词语过滤掉。
11、优选地,前述的自适应数据分析与模型管理的方法,所述根据出现频率高低从所述c个词语中选择一个或多个词语过滤掉的步骤包括:根据对所述神经网络模型分析数据的时间限制,计算从所述c个词语中过滤掉的词语数量,其中,z为常数,t为对所述神经网络模型分析数据的最大限制时间。
12、优选地,前述的自适应数据分析与模型管理的方法,所述从所述b个词语中筛选保留具有匹配的数据值的c个词语的步骤还包括:从所述c个词语中选择所述多个样本数据中出现一次以上的任一词语;根据该词语对应的多个数据值计算离散度,其中,为该词语的第o个数据值,为该词语对应的多个数据值的平均值;在该词语的离散度高于预设阈值时,将该词语从所述c个词语中过滤掉。
13、优选地,前述的自适应数据分析与模型管理的方法,所述根据所述多个样本数据对应的样本特征及标签训练神经网络模型的步骤包括:获取当前用于训练所述神经网络模型的cpu资源以及内存资源;根据所述神经网络模型的cpu资源以及内存资源,计算所述神经网络模型训练过程中的迭代次数,其中,表示当前的cpu资源,表示当前的内存资源,h和为权重系数。
14、第二方面,本发明提供了一种自适应数据分析与模型管理的系统,包括:样本数据获取模块,对于待进行数据分析的目标业务,获取与所述目标业务存在关联关系的多个样本数据;标签设置模块,为所述多个样本数据设置标签,所述标签反映基于所述多个样本数据进行分析得到的期望结果数据;分词模块,以所述多个样本数据中的任一个样本数据为目标样本数据,提取所述目标样本数据中的a个词语并对所述a个词语进行词性分析;第一筛选模块,从所述a个词语中筛选出词性为名词的b个词语;数据值检测模块,从所述目标样本数据中检测所述b个词语是否具有匹配的数据值;第二筛选模块,从所述b个词语中筛选保留具有匹配的数据值的c个词语;特征创建模块,根据所述c个词语及匹配的数据值,创建用于进行深度学习训练的样本特征及对应的特征值;模型训练模块,根据所述多个样本数据对应的样本特征及标签训练神经网络模型,其中,根据所述多个样本数据对应的样本特征确定所述神经网络模型的输入层,根据所述多个样本数据对应的标签确定所述神经网络模型的输出层;业务数据获取模块,获取所述目标业务执行过程中产生的业务数据;结果输出模块,根据神经网络模型的输入层从所述业务数据中提取多个特征以及匹配的特征值,将所述多个特征的特征值输入所述神经网络模型,获得所述神经网络模型输出的所述目标业务执行的预期结果数据。
15、本发明上述一个或多个技术方案,至少具有如下一种或多种有益效果:
16、本发明的技术方案,并未如现有技术方案对样本数据进行人工拆解分析,而是在获得目标业务对应的样本数据并设置标签后,首先进行分词及词性分析,由于特征的名称往往为名词,所以可以据此筛选出词性为名词的词语,其次由于特征必然具有与其匹配的特征值,所以可以据此对剩余的名词词语进行二次筛选过滤,通过两次筛选过滤可以实现自动地从样本数据中提取样本特征及对应的特征值,结合标签即可明确神经网络模型的输入层、输出层并进行训练,基于训练好的神经网络模型可实现对业务执行过程中产生的业务数据进行实时分析处理并输出预测的结果数据,使用样本数据训练神经网络模型的过程不需人工参与,相比现有技术更加高效。
- 还没有人留言评论。精彩留言会获得点赞!