一种基于多域失真学习的无参考图像质量评价方法
本发明涉及图像、视频处理,尤其是涉及一种结合多域失真学习的特征学习方式以及深度学习进行无参考图像质量评价的方法。
背景技术:
1、图像质量评价(image quality assessment,iqa)在机器视觉领域是一个极为基础而又重要的任务。iqa是指通过对图像信号进行相关特性分析,评价图像的视觉失真程度。iqa方法可以分为主观iqa方法和客观iqa方法。主观iqa方法是指通过大量的观测者主观判断获取图像的视觉质量。客观iqa是指通过客观算法自动计算图像的视觉质量。特别地,客观iqa又可以细分为全参考iqa,半参考iqa,无参考iqa。相较于全参考iqa和半参考iqa,无参考iqa无需参考图片信息,而且它拥有更广阔的应用市场和实际价值。根据无参考iqa在计算图像退化质量时是否需要图像的主观分数来进行训练,无参考iqa可分为基于监督学习的无参考iqa和基于无监督学习的无参考iqa。
2、基于监督学习的无参考iqa主要包括基于传统机器学习的方法和基于深度学习的方法。基于传统机器学习的方法旨在设计有效的视觉特征表达方法,通过支持向量回归等传统机器学习方法学习视觉特征到图像退化质量的映射模型。
3、随着深度学习的蓬勃发展,计算机视觉领域达到了新的高度,对图像和视频的处理也有了很大突破。传统的依靠对人类视觉效应(hvs)的建模来完成图像质量评价的方法复杂性高,计算量大,且由于用户生成的野外拍摄图像包含的失真类型众多,传统建模算法难以实现较高的预测准确度。因此,基于深度学习更高效、更准确的视频质量评价方法获得了持续的研究热度。
4、现有基于深度学习的nr-iqa方法主要依赖图像语义信息、局部特征信息来进行特征判断,鲜有关注图像本身的退化。我们希望不只关注语义信息而更多的关注退化的信息,而是能在相似的场景下能够区别好坏图片。对于nr-iqa任务来说,算法感知内容变化图像的质量问题是一个重要且极具挑战的任务,如图1所示在一个相似场景下,现有模型预测分数往往不能正确区分图片质量。
技术实现思路
1、针对现有质量评价方法的不足,本发明提供了一种基于多域失真学习的无参考图像质量评价方法。
2、根据hvs研究表明:hvs会根据内部状态推断环境。受此启发,我们假设hvs在感知退化图像时会预测原始图像的样子,然后根据退化-想象中的恢复的图像对进行比对判断退化质量。因此我们觉得有必要对真实拍摄场景他图片基于一个简单有效的模型进行特征修复。利用修复好的图像对失真退化图像帮助进行质量预测。同时,人眼对于图像内容和图像边缘信息中的中高频信息特别敏感。因此我们可以根据人眼对不同频域敏感度不同,对频域信息进行不同的处理。因此我们有必要对中高频信息进行特征提取来学习图像退化质量,帮助模型能够正确区分图像质量。
3、一种基于多域失真学习的无参考图像质量评价方法,包括步骤如下:
4、步骤(1)、构建基于多域失真学习的无参考图像质量评价模型;
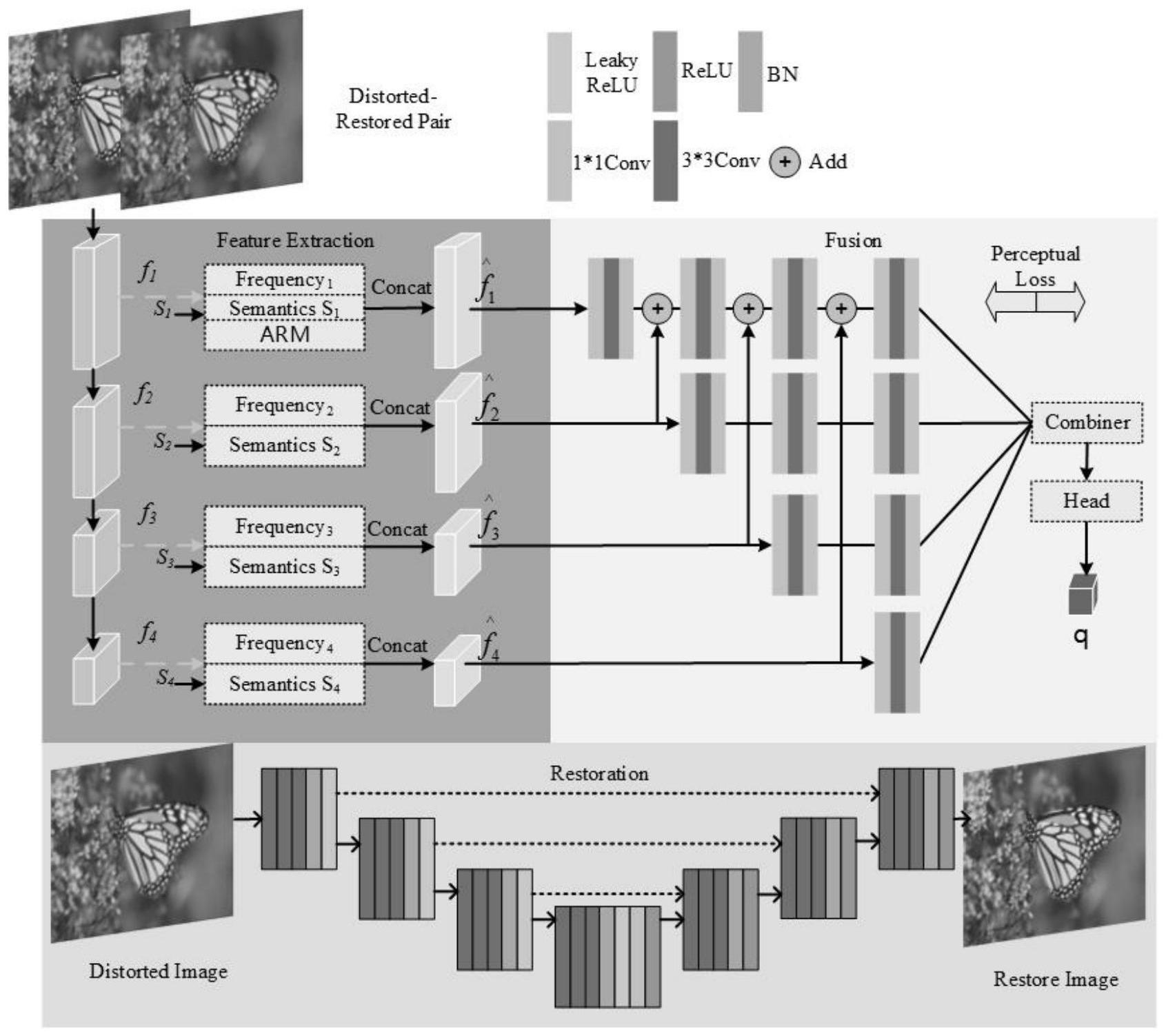
5、所述的基于多域失真学习的无参考图像质量评价模型,包括失真图像修复模块(restoration)和网络主模块;
6、网络主模块由多域失真提取子模块和特征融合子模块构成。其中多域失真提取子模块由频域失真提取模块、语义特征提取模块和边缘信息提取模块组成。特征融合子模块包括多尺度特征连接和“combiner”特征融合模块。
7、步骤(2)、失真图像修复:
8、通过失真图像修复模块(restoration)对输入的失真图像(即质量退化图像)进行退化修复。
9、步骤(3)、通过多域失真提取子模块完成多域失真学习,得到对应的频率特征。
10、步骤(4)、通过语义特征提取模块完成多尺度语义特征提取;
11、步骤(5)、通过边缘信息提取模块完成边缘信息提取;
12、步骤(6)、根据获得的将多尺度频率特征、多尺度语义特征和图像边缘信息,实现特征融合与质量回归;
13、步骤(7)、对构建基于多域失真学习的无参考图像质量评价模型进行训练方法。
14、进一步的,所述的失真图像修复模块总体结构为一个“编码器-解码器”模型,编码器部分子模块由3个3*3卷积,batch norm层和leakyrelu激活层构成;解码器部分子模块由3个3*3卷积,batch norm层和relu激活层构成。将修复好的图像和质量退化图像形成图像对作为网络主模块的输入。
15、进一步的,所述的频率失真提取模块首先通过三次下采样操作,得到不同尺度的修复好的图像和质量退化图像,再采用频率特征提取器分别对不同尺度的修复好的图像和质量退化图像进行频率特征提取,得到对应的频率特征f1,f2,f3,f4。
16、进一步的,步骤(4)具体方法如下:
17、利用预训练的卷积神经网络作为语义特征提取模块。预训练的卷积神经网络是利用resnet50网络在imagenet21k数据集上预先训练得到的图像分类模型构建成的网络,其中保留了stage1-4的特征提取模块;
18、用于提取图像对中对于内容多尺度的语义特征。具体如下:
19、
20、其中,表示来自ith块的resnet50,其中i∈{1,2,3,4},b表示批量大小,ci,mi,ni表示通道大小,宽度和高度。将每个stage的最后一层的输出作为从输入图像中提取的多尺度语义特征。
21、进一步的,边缘信息提取模块(arm)由两个非对称残差块组成,使用非对称残差块从原始图像对中提取图像边缘信息。具体来说每一个非对称残差块由三个并行的3*3,3*1和1*3的卷积组成,将三个卷积的输出合并后接一个bn层和prelu。
22、进一步的,步骤(6)具体方法如下;
23、首先将相同尺度的频率特征和语义特征进行concat操作,对于原始尺度的图像提取得到的频率特征和语义特征需要与图像边缘信息进行concat操作,分别得到对应的相加后的特征
24、将相加后的特征输入特征融合子模块的特征连接部分,将多尺度特征通过“add”操作汇集到第一层连接链路上,最后将四个尺度的特征经过“combiner”特征融合模块对特征进行融合,最后经过“head”层输出预测的质量分数。
25、进一步的,步骤(7)具体方法如下:
26、在模型的4个尺度上分别将待评价图像的特征图和修复后图像的特征图两两计算感知损失,公式表示如下:
27、
28、其中r,d分别表示退化图像和修复后图像;cjwjhj表示第j层上的特征图尺寸,ω()表示所提出的模型函数。
29、模型使用adam优化器对整体模型进行训练,其中权重衰减为0,初始学习率为2*10-5,之后每10个epoch增强10%。采用预训练的resnet50网络对模型进行权重初始化,训练中使用l1损失函数,具体如下:
30、
31、模型总体损失函数具体如下:
32、l=λ1l1+λ2ploss (5)
33、其中λ1,λ2分别为0.5。
34、特别地,在训练阶段,人工合成失真数据集由于已经有参考图像,则直接将参考图片当作修好后的图像输入到主模型中进行共同训练。对于自然失真数据集,需要对失真图像做图像修复操作。
35、本发明的有益效果如下:
36、本发明提出使用多域失真学习方法,帮助模型识别图像信息中的各种噪声,并有效地提高图像质量。现有基于深度学习的nr-iqa方法主要依赖图像语义信息、局部特征信息来进行特征判断,鲜有关注图像本身的退化。我们希望不只关注语义信息而更多的关注退化的信息,而是能在相似的场景下能够区别好坏图片。本发明提出了多域失真学习方法,我们在图像语义特征的基础之上引入频域信息来辅助预测质量分数。
- 还没有人留言评论。精彩留言会获得点赞!