一种基于互动的社交媒体用户分类方法与流程
本发明涉及网络的,特别是涉及一种基于互动的社交媒体用户分类方法。
背景技术:
1、
2、目前国内外的相关研究主要有李忠俊提出的基于话题检测与聚类的内部舆情监测系统,该方法采用内外结合的频谱话题检测法来发现当前关注的热点,运用话题聚类预测模型对当前热点话题的可能发展趋势进行预评估,并采取相应措施,主要解决大多数舆情系统响应速度慢的问题;陈华城等人提出了基于兴趣本体的文档敏感信息检测方法,引入本体的概念来帮助敏感信息监控,这样增加了权重计算、语义距离的计算,虽然较原始的算法有所改进,但是由于实时监控的数据量巨大,仍然不能够有较理想的实际效果。国外文献中也有其他舆情分析思路,其中ermalai i等人通过设计个体的局部相互作用规则,引入个体心理因素和外界媒体影响,提出了利用计算机仿真技术建立舆论传播演化模型的基本思路。此外,国内外也有已经投入商用的舆情系统,例如,国外buzzlogic公司的insight,visible technologies公司的trucast和truview服务,reputation defender的客户监控网络,采用微格式聚合blog、flickr、youtube、mapquest以及myspace等网络空间的内容;国内的北大方正智思舆情分析应对整体解决方案、中国科学院天玑网络舆情监测系统、乐思网络舆情监测系统等。
3、目前所研究的敏感舆情模型中,不论是基于文本或是数据挖掘的分析方法都是直接处理网络舆情,未结合网络传播特性分析。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于互动的社交媒体用户分类方法,根据从社交媒体中爬取的推文进行分析,量化推文的敏感程度,对推文进行分类,然后再根据用户之间的交互关系,对评论内容进行情感分析,进而对用户进行分类,挖掘具有发表敏感舆论倾向的用户。
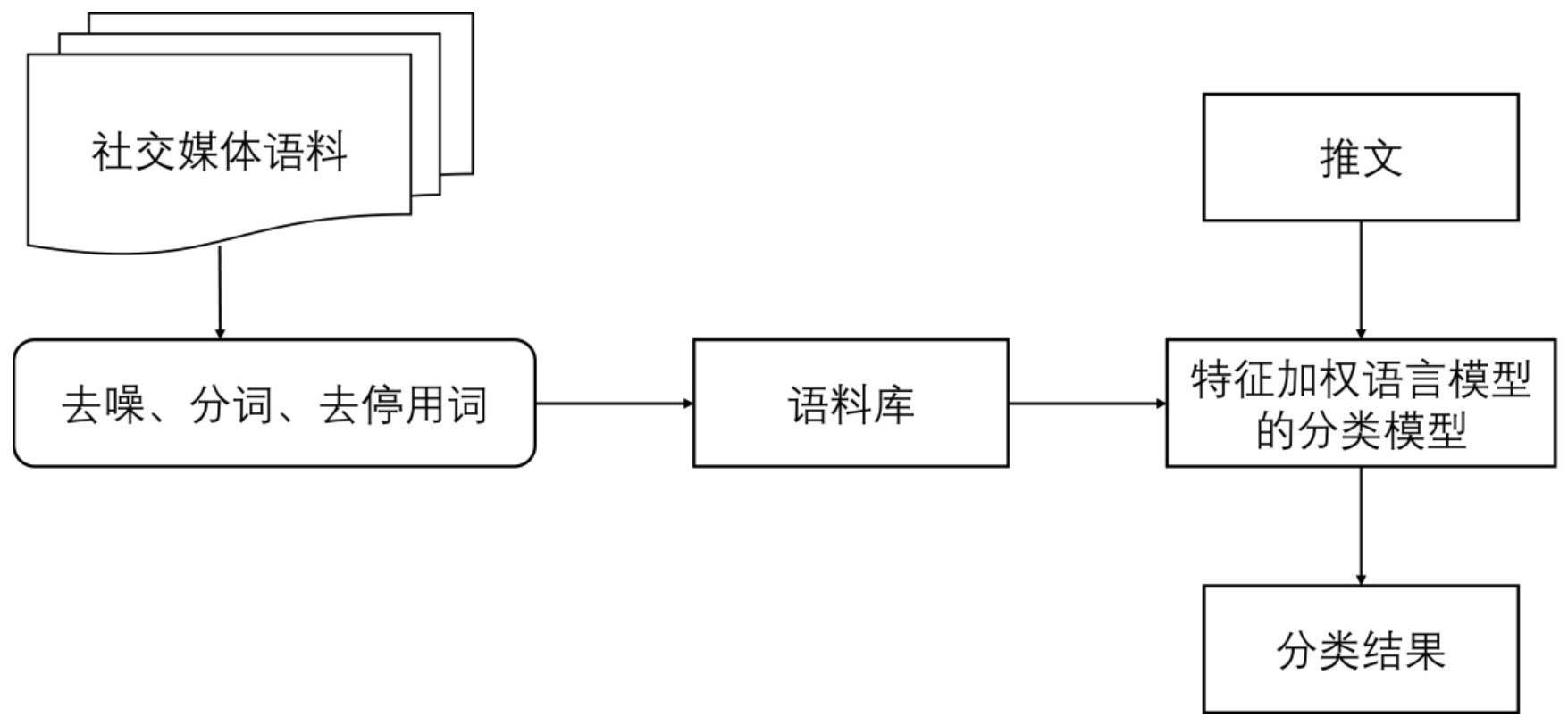
2、本发明的一种基于互动的社交媒体用户分类方法,包括以下步骤:
3、1.社交媒体推文分类;
4、2.用户分类;
5、3.推文和用户关联分类。
6、本发明作进一步改进,步骤1具体方法如下:
7、(11)推文分类模型的基本架构
8、首先对从社交媒体中爬取的推文进行预处理,然后对处理好的推文建立语料库,在语料库中对基于字符串语言模型的推文分类模型进行训练,对于任意的一个推文通过训练好的分类模型得到分类结果,最后对得到的最终结果用相应的指标进行评价;
9、(12)基于特征加权语言模型的推文分类
10、传统的语言模型主要是利用特征词在文档和语料集中的分布,专注于一个词在一个具体类别中的分布,可得:
11、
12、其中,ck是当前类别,ωi是推文中的特征词,|ck|为当前类别的长度,即当前类别中特征词的个数,表示特征词在当前类别中出现的次数,是特征词ωi在当前类别中的最大似然估计;
13、采用的权重加权估算方法如式(2)和式(3)所示:
14、
15、
16、其中,使用的比率是一个特征词在当前类别中出现的概率比上该特征词在其他类别中出现概率的平均值,n表示数据集合中类别总数目,c’k表示其他类别数目,tp(ωi,c’k)表示特征词ωi在其他类别中出现的评价似然估计。
17、本发明作进一步改进,步骤2具体方法如下:
18、(21)基于用户分类的基本架构;
19、(22)模型的建立;
20、(23)交互关系算法。
21、本发明作进一步改进,步骤(21)具体方法如下:
22、首先利用社交媒体提供的搜索功能检索出与关键词有关的推文,检索出的推文经过专业分词软件分词、人工去噪、筛选后得到敏感用户,将其加入到敏感用户库中进行分类,同时根据交互关系算法继续查找该用户社群内的潜在敏感用户,并对潜在敏感用户持续监控,若在监控期间发表敏感推文,则加入敏感用户库,否则放弃监控。
23、5、如权利要求4所述的一种基于互动的社交媒体用户分类方法,其特征在于,步骤(22)具体方法如下:
24、使用(23)中交互关系算法对用户进行分类,通过量化敏感推文的敏感值,并计算不同方式与敏感推文交互的用户获得的传递敏感值进行判定。
25、本发明作进一步改进,(23)交互关系算法包括如下内容:
26、a)敏感推文的量化
27、敏感词的敏感权重通过敏感词库得到,词库由网络上敏感词集合经过人工整理添加敏感词权重得到,式(4)定义了量化一条推文的敏感值的方法;
28、e(vi,m)=(w11×vcon+w12×vre+w13×vcom)×∑ei 式(4)
29、其中:e(vi,m)代表用户vi第m条推文的敏感值;vcon、vre、vcom分别代表推文长度、推文被转发数量及推文被评论的数值,可直接从推文文本中获得;w11、w12、w13分别代表这三个指标对应的归一化系数;ei代表推文中敏感词的敏感权重,推文中可能存在多个敏感词,因此可再将多个敏感词的敏感权重累加计算推文的敏感值;
30、b)敏感度传播系数
31、敏感推文交互方式和次数直接影响对用户分类的判定;
32、(3)交互行为是转发、点赞,转发和点赞敏感推文就相当于在转发者的主页发布这个敏感推文,把这种交互行为得到的用户和推文发布者归为一类敏感用户;
33、(4)交互行为是评论、提及,用户评论某条敏感推文或者在推文中提及,都表示该用户参与此条推文的传播,但评论和提及的敏感度传播系统不同,用符号i(vj,vi,m)表示用户vj与用户vi的第m条敏感推文进行交互时的敏感度传播系数;
34、c)传递敏感值
35、通过用户与敏感推文交互得到的敏感度传播系数和该推文的敏感值能够计算得到,计算公式如下:
36、
37、其中:表示用户vj从用户vi第m条敏感推文获得的传递敏感值;e(vi,m)表示用户vi第m条推文的敏感值,由式(4)计算得到,i(vj,vi,m)表示敏感度传播系数;
38、d)用户潜在敏感值
39、用户潜在敏感值是衡量用户敏感程度的指标,其值越大,该用户与敏感推文交互更频繁,成为敏感用户的可能性越高,用户潜在敏感值的计算以传递敏感值为基础,考虑到一个用户可能与多条敏感推文有交互,给出如下计算公式:
40、
41、其中:表示用户vj的潜在敏感值;set(vi)是用户vi所有敏感推文的集合;表示用户vj从用户vi第m条敏感推文获得的传递敏感值。
42、本发明作进一步改进,步骤3具体方法如下:在对推文和用户分类后,根据推文类型的种类与用户建立数组关系,通过对用户最新点赞、转发和评论的推文进行分析,若用户点击某种类型的推文,则数组中对应某种类型的推文数量加1,在对该类型的推文点击次数达到某个数值后,即可判定该用户与该类型推文有相同的倾向性。
43、本发明作进一步改进,对从社交媒体中爬取的推文进行预处理的方法包括去噪、分词、去停用词。
44、与现有技术相比本发明的有益效果为:首先对从社交媒体中爬取的推文进行预处理,然后对处理好的推文建立语料库,在语料库中对基于字符串语言模型的推文分类模型进行训练,对于任意的一个推文通过训练好的分类模型得到分类结果,最后对得到的最终结果用相应的指标进行评价;利用语言模型计算每个特征词在特定类别中出现的概率,最终的特征词的权重是对于一个特征词的权重,是特征词在一个具体类别中出现的概率比上在其他类别中出现的概率;通过自建包含敏感词和敏感权重的词库,检索发布敏感信息的社交媒体用户,以交互关系算法为核心,最终达到以用户为单位,自动化地检测、发掘新的敏感用户的目的;
45、本方法所提供的模型及算法对基于互动的社交媒体的用户分类有较好的准确性和精确度,对新一代互联网舆情的监控也有更好的适应性,未来有更好的应用和推广发展前景。
- 还没有人留言评论。精彩留言会获得点赞!