一种基于元学习的医学常识知识图谱自动化构建方法
本发明属于自然语言处理,具体的说是一种基于元学习的医学常识知识图谱自动化构建方法。
背景技术:
1、当今世界,随着信息时代的到来,衍生了海量的数据,知识图谱成为了整合和表示领域知识的有效工具。知识图谱是一种表示知识的方法,可以将知识按照三元组(头实体,关系,尾实体)的形式组织成图谱,从而使得知识之间的联系变得清晰可见。在医学领域,构建医学常识知识图谱可以帮助医生、研究人员和决策者更好地理解和利用医学知识,医学知识图谱的主要应用方向为语义搜索、知识问答和临床决策支持,同时在一些新领域,如辅助药物研发和公共卫生事件应对,知识图谱也逐渐显示出其优势。然而,传统的手工构建知识图谱的方法需要大量的人力和时间,并且在面对不断增长的医学文献和临床数据时,很难跟上知识的更新和扩展。
2、因此人们考虑用模型从现有的医学常识知识图谱中学习知识,从而生成新的可能的医学常识知识,也即当前的热门的知识图谱补全问题。知识图谱补全技术可以自动地从不完整的知识图谱中推断出缺失的知识点,从而更好地帮助人们学习常识知识。然而,当前知识图谱补全技术面临的一个重要问题就是训练数据的缺乏,知识实体和关系需要通过大量的人工标注才能得到,这个过程非常耗费时间和精力。另外,由于知识图谱的不断更新和扩展,需要不断地添加新的知识实体和关系,这也会导致知识图谱中存在许多未标注的实体和关系。因此,训练数据的缺乏是当前知识图谱补全技术面临的一个主要挑战。为了解决这个问题,一些研究者提出了半监督学习和远程监督学习的方法,利用已有的知识图谱和其他的外部知识来辅助补全未标注的实体和关系,但是它过于依赖已标注的数据,一旦数据标注不准确就会影响知识图谱补全的效果;另外,一些研究者提出了基于生成对抗网络和强化学习的方法,通过生成虚拟的知识图谱数据来扩充训练数据,但这种训练方式过于复杂。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出一种基于元学习的医学常识知识图谱自动化构建方法,以期能仅使用少量的训练数据训练模型就可以精准地实现医学常识知识图谱自动化构建,并能精准地生成新的医学常识知识,从而为医学研究、医学教育和医学知识管理等领域提供有利支持。
2、本发明为达到上述发明目的,采用如下技术方案:
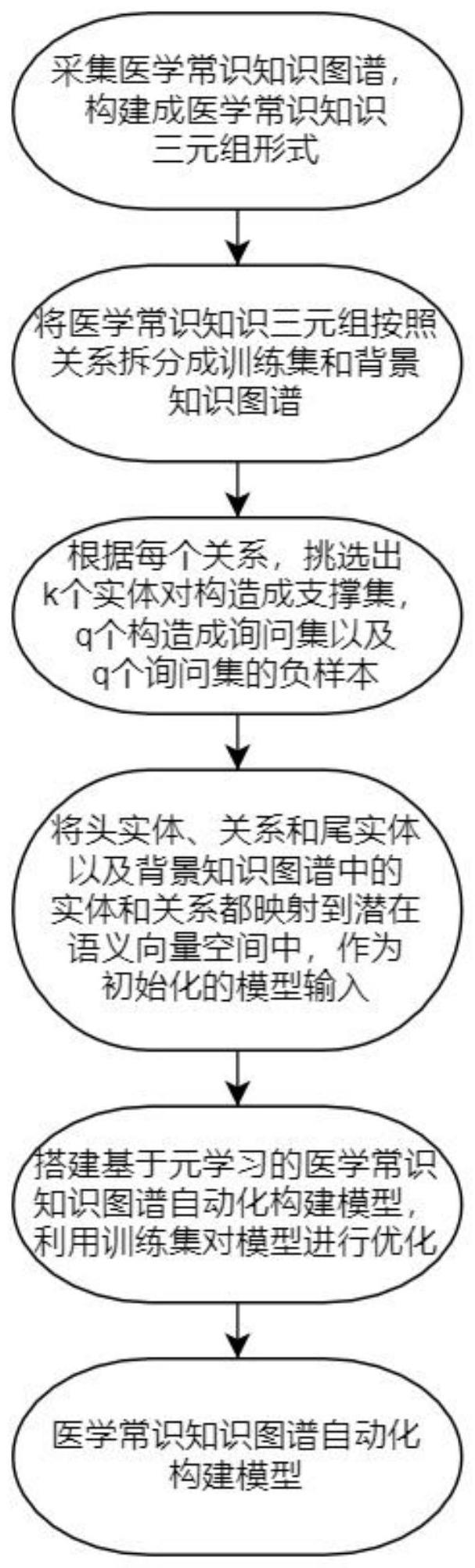
3、本发明一种基于元学习的医学常识知识图谱自动化构建方法的特点在于,是按如下步骤进行:
4、步骤一:获取医学常识知识图谱,并根据医学常识知识图谱中的各个实体以及各实体间的关系构建医学常识知识图谱g={(h,r,t)∈ε×r×ε},其中,h表示头实体节点,r表示关系节点,t表示尾实体节点;ε和r分别为所述医学常识知识图谱g对应的实体节点集合和关系节点集合;
5、步骤二:从医学常识知识图谱g中抽取部分三元组作为背景知识图谱g′,所述背景知识图谱g′包含关系节点集合r中的部分关系节点,r中剩余的关系节点所对应的三元组作为训练知识图谱gtrain;
6、步骤三:从训练知识图谱gtrain中随机抽取第i个关系节点ri,并选取第i个关系节点ri所对应的部分三元组来构建针对关系节点ri的支撑集si,利用第i个关系节点ri其余的三元组构建询问集qi;再将询问集qi中的所有尾实体均替换成与自身头实体无关联关系的实体,从而构建负询问集
7、步骤四:构建交互注意编码器,并以交互的方式对支撑集si和询问集qi的头、尾实体的语义信息进行编码,以生成更具区分性的实体对表示;
8、步骤4.1对实体语义信息进行编码,得到头实体的最终向量表示和尾实体的最终向量表示
9、步骤4.2利用式(7)得到实体对的向量表示
10、
11、式(7)中,和是待训练的参数,tanh是激活函数;
12、步骤4.3按照步骤4.1-步骤4.2的过程得到关于第i个关系节点ri的询问集qi的实体对向量表示
13、步骤五:构建自适应原型网络,通过聚合实体对向量表示来生成关系原型表示pi;
14、步骤5.1利用式(8)得到询问实体对和支撑集中的第j个参照实体对的相似度分数αi,j:
15、
16、式(8)中,⊙是点积操作,代表支撑集si中的第l个参照实体对,代表实体对的向量表示;
17、步骤5.2利用式(9)得到与询问集相关的原型表示pi:
18、
19、式(9)中,αi,j是询问实体对和支撑集si中的第j个参照实体对的相似度分数;
20、步骤六、由交互注意编码器和自适应原型网络构成医学常识知识模型,并基于医学常识知识图谱g与背景知识图谱g′,利用反向传播算法对所述医学常识知识模型进行训练,同时计算如式(10)所示的损失函数l以更新模型参数,当损失函数l不断下降直至收敛时,得到最优医学常识知识模型:
21、
22、式(10)中,γ是边缘超参数,为询问集qi中实体对的向量表示,为负询问集中实体对的向量表示;[·]+是铰链损失函数;
23、步骤七、将现有的医学常识知识图谱输入所述最优医学常识知识模型中,从而输出模型生成的新的医学常识知识三元组的可信度概率,并将概率靠前的医学常识知识三元组输出,从而实现医学常识知识图谱自动化构建。
24、本发明所述的基于元学习的医学常识知识图谱自动化构建方法的特点也在于,所述步骤4.1是按如下步骤进行:
25、步骤4.1.1生成第i个关系节点ri的支撑集si中第j个实体对的邻居其中,表示头实体的邻居,且表示尾实体的邻居,且其中,表示与头实体在背景知识图谱g′中有关联的实体,rh表示头实体与头实体邻居之间的关系,表示与尾实体在背景知识图谱g′中有关联的实体,rt表示尾实体与尾实体邻居之间的关系;
26、步骤4.1.2统计头实体的邻居的个数设置潜在语义特征向量的维度为d,利用随机初始化法构建维的邻居关系向量矩阵维的邻居实体向量矩阵
27、步骤4.1.3计算头实体的邻居注意力权重矩阵
28、使用随机初始化化分别生成头实体和尾实体的向量表示和
29、利用式(1)生成第i个关系节点ri的初始化向量表示uri:
30、
31、利用式(2)计算头实体的邻居注意力权重矩阵
32、
33、式(2)中,是两个权重矩阵;
34、步骤4.1.4生成头实体的加权邻居向量表示
35、利用式(3)计算头实体的邻居的融合语义信息的向量矩阵
36、
37、式(3)中,tanh是激活函数,||是连接操作,和分别是待训练的参数矩阵;
38、利用式(4)生成头实体的加权邻居向量表示
39、
40、式(4)中,是待训练权重矩阵,vk是头实体的第k个邻居的融合语义信息的向量表示,αk是头实体的第k个邻居对于头实体的注意力得分,并由式(5)得到;
41、
42、式(5)中,aq是头实体的邻居注意力权重矩阵中的第q个注意力权重,ak是头实体
43、的邻居注意力权重矩阵中的第k个注意力权重;
44、步骤4.1.5利用式(6)得到头实体的最终向量表示
45、
46、式(6)中,是两个待训练的权重矩阵,tanh是激活函数;
47、步骤4.1.6按照步骤4.1.2-步骤4.1.5的过程得到尾实体的最终向量表示
48、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述医学常识知识图谱自动化构建方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
49、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述医学常识知识图谱自动化构建方法的步骤。
50、与现有技术相比,本发明的有益效果在于:
51、1、针对医学常识知识缺乏问题,本发明充分利用现有的医学常识知识图谱的知识信息,并将常识知识的语义信息融入到向量表示中,尤其在面对多个三元组涉及的关系语义不同时,更能精准地捕捉到与模型需要生成的医学常识知识有关的特征,从而达到更准确和有针对性地生成医学常识知识的目的;
52、2、针对训练数据缺乏的问题,本发明使用了基于元学习的方法,使得仅利用很少的常识知识三元组就可以学习到有用的信息,进而精准地生成可信度高的新的医学常识知识,大大提高了学习模型的整体效果,从而实现了更有效的医学常识知识推理和应用;
53、3、本发明设计了交互注意编码器和自适应原型网,分别用来生成实体对的向量表示以及生成适应不同询问三元组的关系原型,从而能更加精准地捕捉到实体对的底层关系语义信息以及使模型更多地关注到与要生成的三元组相关的特征,达到为实际应用中的问题解决和决策支持提供了更准确、可靠的医学常识知识的目的;
54、4、元学习旨在使模型能够通过从少量样本中学习到的先验知识,快速适应新任务或新环境。在医学常识知识图谱的构建中,元学习可以用来自动学习和推断医学实体和关系之间的规则和模式。本发明通过将元学习算法与医学文献、临床数据和专家知识相结合,可以实现医学常识知识图谱的自动化构建。基于元学习的医学常识知识图谱自动化构建方法具有以下优势:首先,它可以大大减少手工工作量,提高知识图谱的构建效率。其次,通过从少量样本中学习到的先验知识,可以快速适应新的医学领域和新的知识。最后,它可以通过整合多个数据源和专家知识,提高了知识图谱的准确性和完整性。
- 还没有人留言评论。精彩留言会获得点赞!