一种面向无线边缘节点模型分割机器学习方法
本发明涉及人工智能,更具体地,涉及一种面向无线边缘节点模型分割机器学习方法。
背景技术:
1、随着深度学习的发展,基于深度神经网络的应用成为人们日常生活中不可或缺的一部分。深度神经网络的规模也越来越大,精确度越来越高。然而,无线边缘设备终端资源有限,无法完成延迟需求较高的大规模神经网络的训练任务。同时,边缘设备中用户数据的隐私性限制了上传数据到服务器进行集中式训练。随着5g与边缘计算的发展,使得低延迟的深度学习训练任务成为可能。例如,无线联邦学习系统可以从边缘设备的数据中学习知识,而无须将数据上传到服务器。通过将神经网络的训练过程和数据收集过程分离,无线联邦学习系统可以减少隐私数据的暴露,并为无线边缘设备提供全局模型的即时访问。
2、在传统无线联邦学习系统中,为了捕获不同边缘设备中用户数据的异构性。通常将全局模型进行分割,使边缘设备拥有一个独立的特征提取神经网络或分类神经网络来学习数据的异构性,但完整的神经网络训练步骤保留在边缘设备上。这种方案,对边缘设备的计算资源提出了很严格的要求,而计算资源受限的边缘设备通常无法训练一个完整的全局模型。为了降低边缘设备的资源需求,可以将所有边缘设备共同拥有的神经网络部分移至服务器,通过边缘设备和服务器多次交换模型的输出数据来训练神经网络。边缘设备由于仅进行小部分神经网络的训练,因此能够参与模型的训练过程中,然而边缘设备需要顺序等待服务器的处理和返回结果,这增大了边缘设备的等待延迟。而如果利用与边缘设备同等数量的服务器,尽管能减少边缘设备的等待延迟,但同时也提高了对服务器的需求。
3、综上,在利用边缘设备和服务器进行神经网络训练时,如何对任务进行合理划分,以满足边缘设备的资源要求,并且同时减少边缘设备的等待延迟是一个值得研究且具有实际应用价值的问题。
技术实现思路
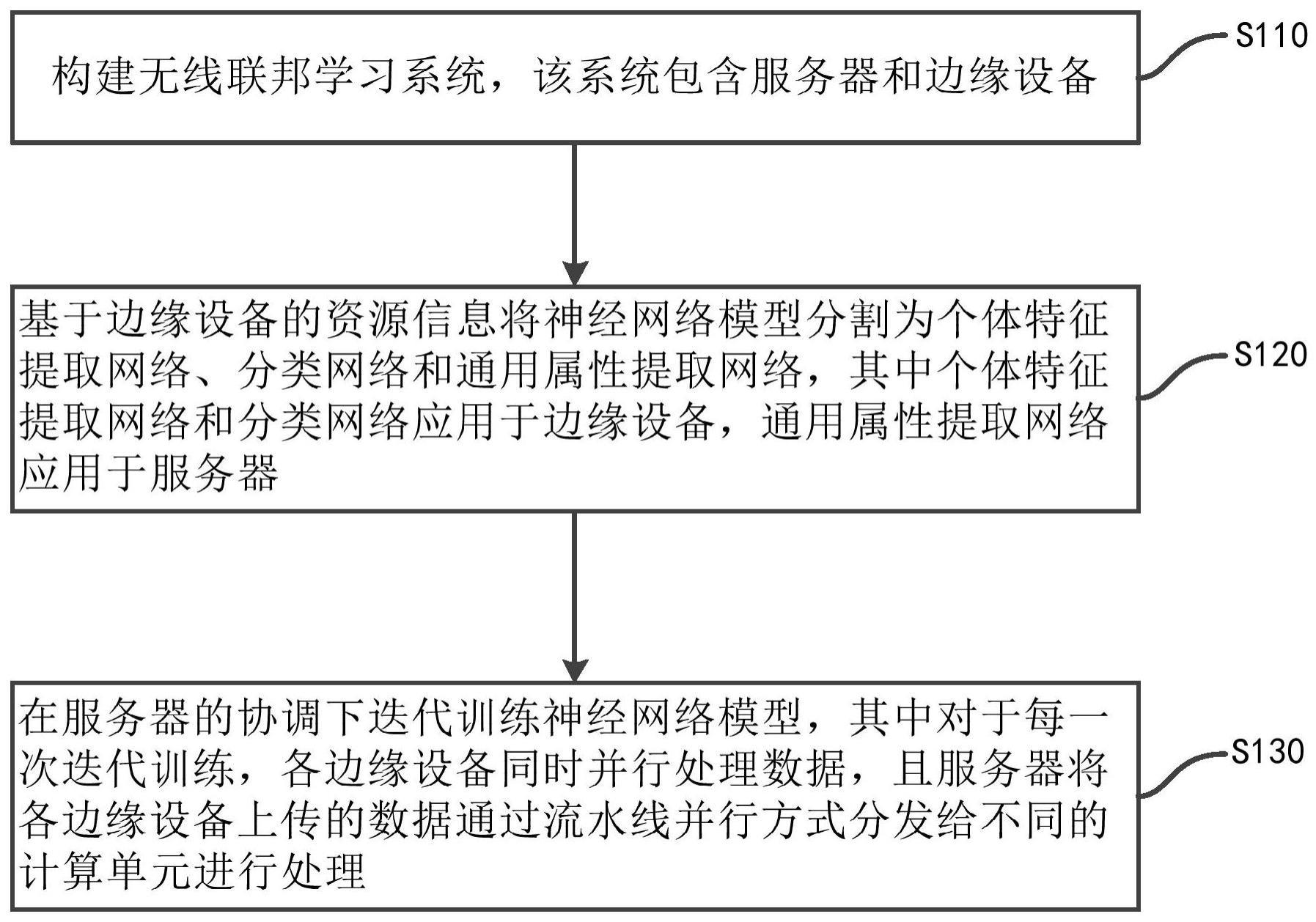
1、本发明的目的是克服上述现有技术的缺陷,提供一种面向无线边缘节点模型分割机器学习方法。该方法包括以下步骤:
2、构建联邦学习系统,该联邦学习系统包含服务器和一个或多个边缘设备;
3、基于各边缘设备的资源信息将神经网络模型分割为个体特征提取网络、分类网络和通用属性提取网络,其中所述个体特征提取网络和所述分类网络应用于边缘设备,所述通用属性提取网络应用于服务器;
4、在服务器的协调下,迭代训练所述神经网络模型,其中对于每一次迭代训练,各边缘设备同时并行处理数据,且服务器将各边缘设备上传的数据通过流水线并行的方式分发给不同的计算单元进行处理。
5、与现有技术相比,本发明的优点在于,在利用边缘设备和服务器进行神经网络训练时,基于边缘设备的资源信息对任务进行合理划分,既满足了边缘设备的资源要求,同时降低了边缘设备的等待延迟。
6、通过以下参照附图对本发明的示例性实施例的详细描述,本发明的其它特征及其优点将会变得清楚。
技术特征:
1.一种面向无线边缘节点模型分割机器学习方法,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,对于第k次迭代,边缘设备和服务器执行以下过程:
3.根据权利要求2所述的方法,其特征在于,第k次迭代中,对于来自于边缘设备n的数据,服务器接收的数据表示为:
4.根据权利要求3所述的方法,其特征在于,所述边缘设备对每个无线信道执行功率控制来实现信道对齐:
5.根据权利要求1所述的方法,其特征在于,所述服务器将各边缘设备上传的数据通过流水线并行方式分发给不同的计算单元进行处理包括以下步骤:
6.根据权利要求1所述的方法,其特征在于,在所述神经网络模型训练过程中,边缘设备采用以下公式更新所述个体特征提取网络和所述分类网络的参数:
7.根据权利要求1所述的方法,其特征在于,在所述神经网络模型训练过程中,服务器采用以下公式更新所述通用属性提取网络的参数:
8.根据权利要求1所述的方法,其特征在于,还包括利用经训练的所述卷积神经网络模型进行分类预测。
9.一种计算机可读存储介质,其上存储有计算机程序,其中,该计算机程序被处理器执行时实现根据权利要求1至8中任一项所述的方法的步骤。
10.一种计算机设备,包括存储器和处理器,在所述存储器上存储有能够在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至8中任一项所述的方法的步骤。
技术总结
本发明公开了一种面向无线边缘节点模型分割机器学习方法。该方法包括:构建联邦学习系统,该联邦学习系统包含服务器和一个或多个边缘设备;基于各边缘设备的资源信息将神经网络模型分割为个体特征提取网络、分类网络和通用属性提取网络,其中所述个体特征提取网络和所述分类网络应用于边缘设备,所述通用属性提取网络应用于服务器;在服务器的协调下,迭代训练所述神经网络模型,其中对于每一次迭代训练,各边缘设备同时并行处理数据,且服务器将各边缘设备上传的数据通过流水线并行的方式分发给不同的计算单元进行处理。本发明通过对任务进行合理划分,既满足了边缘设备的资源要求,并且减少了边缘设备的等待延迟。
技术研发人员:董延杰,王鲁亚,郑建波,胡希平,梁中明
受保护的技术使用者:深圳北理莫斯科大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!