一种基于多层次细化的U-Transformer动作分割方法
本发明涉及模式识别与计算机视觉,尤其是一种基于多层次细化的u-transformer动作分割方法。
背景技术:
1、随着科技的发展,动作检测是近些年来的热点研究问题,在无人驾驶、安全监控、交通运输、人机交互系统等领域,动作分割的应用越来越广泛。现有的大多数最先进的动作检测方法采用transformer架构,tansformer能够有效地替代卷积神经网络应用于动作分割任务中。而transformer在动作分割的应用仍存在许多问题,一方面,transformer对输入数据的结构归纳偏置较少,因此需要大量的数据进行训练,而相比于其他领域数据集规模,动作分割数据集规模较小。另一方面,transformer中的自注意力层难以直接处理过长的未剪辑的样本视频序列。现主流的方法基于transformer通过局部连通性和预定义的层次表示模式,或者通过局部、全局注意力替换来解决这两个问题,但这样很难挖掘相邻行为的上下文关系或者不能捕获长期时序信息。因此,如何有效地利用transformer进行建模仍然是一个悬而未决的问题。针对上述情况,我们提出一种基于多层次细化的u-transformer动作分割方法。
技术实现思路
1、本发明提出一种基于多层次细化的u-transformer动作分割方法,能够有效地对视频动作进行分割。
2、本发明采用以下技术方案。
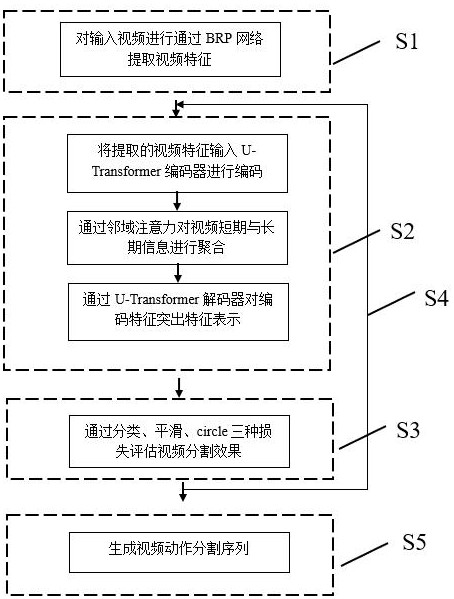
3、一种基于多层次细化的u-transformer动作分割方法,用于分割视频动作,包括以下步骤;
4、步骤s1:对输入视频进行通过brp网络提取视频特征;
5、步骤s2:首先将提取的视频特征输入u-transformer编码器进行编码,通过邻域注意力对视频短期信息与长期信息进行聚合,而后通过解码器对编码特征突出特征表示;
6、步骤s3:通过分类、平滑、circle三种损失对动作分割效果进行评估优化;
7、步骤s4:调整u-transformer结构中感受野重复步骤s2、s3逐步动作分割细化分割效果;
8、步骤s5:根据特征生成视频动作分割序列。
9、步骤s1包括以下步骤;
10、步骤s11:使用brp网络对视频数据提取特征,得到大小为n×d的特征序列x∈rn×d,其中n为视频长度,d为特征维数,供训练过程使用;
11、步骤s12:基于brp网络构建端到端的视频序列特征建模神经网络模型,以优化泛化能力及视频序列特征建模。
12、步骤s2具体包括以下步骤:
13、步骤s21:将brp预先提取的视频序列特征作为编码器的输入,分别通过全连接层、编码块以及全连接层三部分组成的编码器进行特征表示;即首先通过一个完全连接层调整特征的维度;而后通过一系列编码器块细化特征;最后,经由一个完全连接层输出预测;具体公式表示如下:
14、fi=fc(e(fc(xi)));
15、其中,fi表示第i个编码器的输出表示,xi表示第i个编码器的输入特征,fc(·)表示全连接层,e(·)表示编码块操作;
16、步骤s22:所述编码块主要由前馈层以及注意力层构成;通过下采样构建u型结构的编码器部分,通过扩展时间卷积作为前馈层,注意力层使用分层模式首先关注局部特征,然后逐渐扩大感受野不断细化特征,以获取全局信息;编码器公式表述描述如下:
17、
18、
19、
20、其中,xi为第i个编码器输入特征,downsample(·)为下采样层,att(·)为邻域注意力层,in(·)为实例归一化层,ffn(·)为前馈层;
21、步骤s23:所述邻域注意力将高维表示向量映射到低维编码空间,即从中随机抽取m表示xm∈rm×d,然后通过线性投影得到qm和km;通过计算q与k与的点积将q,k∈rn×d映射到一个m维空间得到两个低秩矩阵将近距离矩阵的计算分解为两个低秩矩阵的乘法,将复杂度从o(n2d)显著降低到o(n2m)。具体计算公式如下:
22、
23、而后利用相邻帧特征相似性对近距离矩阵进行系数权重设置;通过对近距离矩阵值进行排序,选取视频输入序列设置合适的长度k,从近距离矩阵中计算top-k的值并设置权重,将前top-k的权重设置为1,其余设置为0,使其关注近距离矩阵的top-k相近的值,具体公式如下:
24、
25、最后,基于近距离矩阵转换为注意力挖掘相邻动作的关系,具体公式如下:
26、
27、步骤s24:编码器输出的初始预测为解码器的输入,首先通过全连接层,调整特征大小,然后通过解码块细化特征;通过注意机制允许引入外部信息来指导细化过程;解码块结构表示如下:
28、
29、
30、
31、其中,fi为第i个解码器输入特征,upsample(·)为上采样层,att(·)为步骤s23所注意力层,in(·)为实例归一化层,ffn(·)为前馈层。
32、步骤s3包括以下步骤;
33、步骤s31:通过交叉熵损失计算每一帧预测的动作概率和相应的标签之间的帧级损失:
34、
35、其中,yt为第t帧预测为动作类别的概率;帧级损失的分类损失独立对待每一帧,在执行视频动作段的分割,存在导致过度分割效果的机率;
36、步骤s32:使用截断均方误差作为平滑损失,平滑过渡帧间和减少过度分割错误;
37、
38、
39、
40、其中,t为输入视频帧数量,c为动作类别总数,为第t帧预测为动作类别的概率。
41、步骤s33:计算circleloss,通过深度特征学习的配对相似度优化视图,最大化类内的相似度,最小化类间的相似度,以缓解过度分割问题;具体为,当将分类损失函数中的最大值视为样本属于某类的概率时设置权重;circleloss损失函数通过加权每个相似度分数来学习深度特征,其有一个独立的权重因子,在重新缩放前乘以每个相似度分数,以实现灵活优化和显式收敛;具体公式如下:
42、
43、其中,和是权重因子,γ是比例因子,相似性得分分别为和r为类内相似度得分,l为类间相似度得分;
44、步骤s34:通过权重设置计算多种损失函数的组合,对编码器和解码器的所有损耗进行累积和训练,以寻找最小的最优值,有效解决u型结构带来的过度分割,平滑原分类效果,并产生更精确的校准序列,具体公式如下:
45、lloss=lcls+λlsmo+βlcircle
46、其中,lcls是交叉熵损失,lsmo为平滑损失,lcircle为circleloss,λ和β为平衡权值。
47、步骤s4具体包括以下步骤;
48、步骤s41:修改编码器时间卷积感受野,按照指数进行扩大,即s={2si,si=0,1,2...},再次进行编码操作细化特征;
49、步骤s42:修改解码器时间卷积感受野,按照指数进行扩大,即s={2si,si=0,1,2...},再次进行解码操作细化分割效果;
50、步骤s43:重复步骤s3计算损失,反向更新网络参数。
51、步骤s5具体包括以下步骤:
52、步骤s51:通过全连接层输出每一帧的分类结果并生成视频动作分割结果。
53、与现有技术相比,本发明有以下有益效果:
54、1、针对动作分割数据集规模较小难以利用transformer模型进行训练,本发明提出了一种新型的多层次u型transformer结构,通过u型分层表示模式使感受野随层数呈指数增长不断细化特征信息,结合多尺度信息和相邻帧之间的短期信息,弥补动作分割方面缺乏的训练数据。
55、2、针对动作分割的长时序信息建模问题,本发明提出了一种基于近距离矩阵的邻域注意力,通过计算近距离矩阵挖掘相邻帧的邻域信息,并引入特征的局部连通性归纳先验信息,对视频帧的特征进行聚合,有效地处理长时序消息。
56、针对动作分割过程中常见的过度分割问题,本发明提出了一种新颖的损失函数优化策略,对于动作分割过程中常见的过度分割问题,引入一种基于深度特征学习的配对相似度优化视图,平滑原分类效果产生更精确的校准序列。
- 还没有人留言评论。精彩留言会获得点赞!