一种机器翻译模型训练方法和装置与流程
本申请涉及机器翻译,尤其涉及一种机器翻译模型训练方法和装置。
背景技术:
1、早期的机器翻译模型主要是基于规则的机器翻译方法,该方法需要人来书写规则,虽然对少部分句子具有较高的翻译精度,但是对翻译现象的覆盖度有限,而且对规则或者模板中的噪声非常敏感,模型的鲁棒性较差。而基于数据驱动的机器翻译方法不依赖人书写的规则,机器翻译的建模、训练和推断都可以自动地从数据中学习,特别是统计机器翻译很快成了当时机器翻译研究与应用的代表性方法。随着机器学习的进步,特别是基于神经网络的深度学习方法在机器视觉、语音识别中被成功应用,同时也广泛应用于机器翻译。
2、现有的机器翻译模型大多数都依赖于大量的有标签的平行语料进行训练。然而该方法在遇到新的语言或者语料时难以获得良好的翻译效果,在翻译语言结构复杂的句子时也往往表现不佳。因此,如何能够使模型在遇到新的语言或者语料时具有更强的泛化能力,提高翻译效果,是亟待解决的技术问题。
技术实现思路
1、有鉴于此,本申请实施例提供了一种机器翻译模型训练方法、装置、电子设备及计算机可读存储介质,以解决现有技术在遇到新的语言或者语料时泛化能力有限的问题。
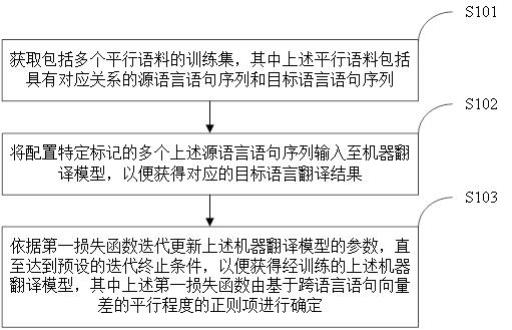
2、本申请实施例的第一方面,提供了一种机器翻译模型训练方法,包括:
3、获取包括多个平行语料的训练集;其中所述平行语料包括具有对应关系的源语言语句序列和目标语言语句序列;
4、将配置特定标记的多个所述源语言语句序列输入至机器翻译模型,以便获得对应的目标语言翻译结果;
5、依据第一损失函数迭代更新所述机器翻译模型的参数,直至达到预设的迭代终止条件,以便获得经训练的所述机器翻译模型;其中所述第一损失函数由基于跨语言语句向量差的平行程度的正则项进行确定。
6、本申请实施例的第二方面,提供了一种机器翻译模型训练装置,适用于第一方面所述的机器翻译模型训练方法,包括:
7、训练集获取模块,能够获取包括多个平行语料的训练集;其中所述平行语料包括具有对应关系的源语言语句序列和目标语言语句序列;
8、目标语言翻译模块,能够将配置特定标记的多个所述源语言语句序列输入至机器翻译模型,以便获得对应的目标语言翻译结果;
9、机器翻译模型训练模块,能够依据第一损失函数迭代更新所述机器翻译模型的参数,直至达到预设的迭代终止条件,以便获得经训练的所述机器翻译模型;其中所述第一损失函数由基于跨语言语句向量差的平行程度的正则项进行确定。
10、本申请实施例的第三方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器中并且可在处理器上运行的计算机程序,该处理器执行计算机程序时实现第一方面所述方法的步骤。
11、本申请实施例的第四方面,提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现第一方面所述方法的步骤。
12、本申请实施例与现有技术相比存在的有益效果至少包括:本申请实施例获取包括多个平行语料的训练集,平行语料包括具有对应关系的源语言语句序列和目标语言语句序列,将配置特定标记的多个源语言语句序列输入至机器翻译模型,获得对应的目标语言翻译结果,依据第一损失函数迭代更新该机器翻译模型的参数,获得经训练的机器翻译模型,该第一损失函数由基于跨语言语句向量差的平行程度的正则项进行确定。本申请实施例的机器翻译模型训练方法,在传统损失函数基础上加入了语句向量间平行关系并进行正则化处理,提高模型的泛化能力,使得模型能够很好地适用于新语料或者复杂语料。
技术特征:
1.一种机器翻译模型训练方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述机器翻译模型包括编码器和解码器;和/或,将配置特定标记的多个所述源语言语句序列输入至机器翻译模型,以便获得对应的目标语言翻译结果的过程,包括:
3.根据权利要求2所述的方法,其特征在于,由基于跨语言语句向量差的平行程度的正则项确定所述第一损失函数的过程,包括:
4.根据权利要求3所述的方法,其特征在于,确定多个所述向量差的平行程度表征,并获得相应的平行程度正则项,包括:
5.根据权利要求4所述的方法,其特征在于,所述平行程度表征包括任意两个向量差之间的夹角余弦值或者任意两个向量差之间的内积。
6.根据权利要求2所述的方法,其特征在于,所述机器翻译模型还包括线性分类器;所述线性分类器能够将所述目标语言潜向量和所述第二标记向量分别转化为所述目标语言翻译结果和所述特定标记。
7.根据权利要求1所述的方法,其特征在于,所述机器翻译模型包括bart、t5、gpt2、gpt3中任一种预训练语言模型。
8.一种机器翻译模型训练装置,其特征在于,适用于权利要求1至7任一项所述的机器翻译模型训练方法,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并且可在所述处理器上运行的计算机程序,其特征在于,所述处理器在执行所述计算机程序时,实现如权利要求1至7中任一项所述方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述方法的步骤。
技术总结
本申请涉及机器翻译技术领域,提供了一种机器翻译模型训练方法和装置。该方法包括:获取包括多个平行语料的训练集;其中平行语料包括具有对应关系的源语言语句序列和目标语言语句序列;将配置特定标记的多个源语言语句序列输入至机器翻译模型,以便获得对应的目标语言翻译结果;依据第一损失函数迭代更新机器翻译模型的参数,直至达到预设的迭代终止条件,以便获得经训练的机器翻译模型;其中第一损失函数由基于跨语言语句向量差的平行程度的正则项进行确定。本申请在传统损失函数基础上加入语句向量间平行关系并进行正则化处理,提高了模型泛化能力,使模型更好地适用于新语料或复杂语料。
技术研发人员:蒋敏,暴宇健
受保护的技术使用者:深圳须弥云图空间科技有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!