一种术语及类型的二元组单步抽取方法及其模型
本发明涉及一种术语抽取方法,具体为一种融合依存结构和边界损失的术语及类型的二元组单步抽取方法及其模型。
背景技术:
1、术语抽取是文本挖掘和信息抽取的关键步骤,对于机器翻译、信息检索、本体构建和知识图谱等领域至关重要。自从20世纪30年代初以来,研究者们就广泛探索了与术语相关的领域,从繁琐耗时的人工术语抽取方法到自动术语抽取模型的研究。近年来,随着在线智慧教育的兴起,对基础教育领域中的术语抽取方法进行了深入研究,并在多个学科领域取得了不错的成果。中学数学术语作为中学数学学科知识表示的核心,其准确的抽取将直接影响构建中学数学知识图谱的质量,同时术语所属的知识点类型获取也能丰富知识图谱中术语实体的信息。此外,随着学科知识库的不断充实和中学数学教材的更新迭代,网络数学学习资源也快速增长。因此,如何从海量的非结构化中学数学知识中准确地、自动地、联合地抽取术语及对应类型是一个难题。
2、术语是专业领域内知识概念的语言指称和主要载体,具有高度概括性和领域性。在中学数学领域中,术语存在单字、多义、多重嵌套等多个形式,其对应的知识点类型在不同语境下归属不同,甚至同语境下同一术语可表现为多种类型。例如,“平面直角坐标系中方程的图象中心点既是原点又是圆心”,其中“中心点”中的“点”作为术语,在“原点”和“圆心”两个术语所属类型的影响下,同属于“平面几何”和“坐标系与直角坐标”两种知识点类型。因此,根据不同语境正确划分术语的知识点类型,可作为提示进一步强化对数学知识概念或习题的理解。
3、现有传统的术语抽取方法,如基于规则和统计的方法存在耗时耗力、泛化能力较弱的缺陷,而近些年的术语抽取方法大多基于深度学习的序列标注方式,且大多聚焦于丰富词嵌入表示或引入额外提示信息以提升术语抽取性能。但中学数学学科的知识表示大多富有强逻辑性、结构性和多样性,这给中学数学术语抽取带来单字多义术语难以精准抽取、多重嵌套术语难以被完整抽取、复杂语境下术语抽取难度较大等难点。
4、针对中学数学领域,现有的一些术语抽取方法依旧对数学知识语义理解有限,导致术语边界识别较为模糊,且从其本身蕴含的依存结构信息角度挖掘句子深层语义的工作也较少,能同时考虑缓解错误分词或依存结构信息带来影响的工作更是几乎没有。
5、对于术语类型的划分通常借助分类模型实现,但针对不同语境下的术语所属类型不一致的问题,多分类方法无法解决。而现有的一些命名实体识别方法虽然可以对多种类型的实体进行序列标注,但无法解决同一句子中术语所属多类型的问题。
6、此外,术语及类型的抽取方法可以分为流水线式和联合式。借鉴关系抽取方法,流水线式的三元组抽取方法存在不可逆的误差传递问题,即前一个模块抽取的术语有误,后续对应的术语分类一定是错误的。同理基于流水线式的术语及类型抽取方法也存在这类问题,但采用联合抽取术语及类型的方式可以得到一定的解决。
技术实现思路
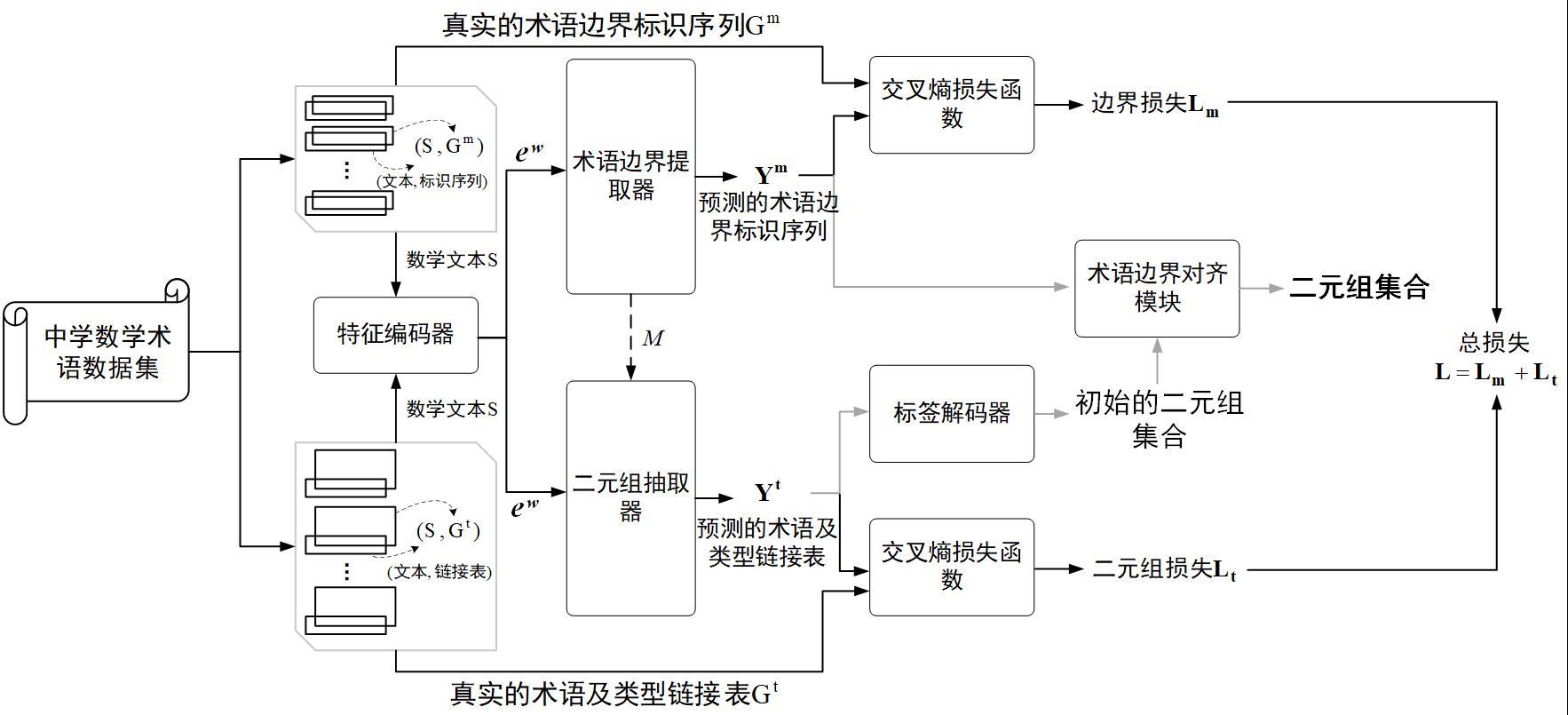
1、为了解决上述技术问题,本发明提供一种术语及类型的二元组单步抽取方法及其模型,从全新视角将术语抽取和对应类型分类统一为术语及类型二元组联合抽取任务,避免了误差传递,实现术语及类型抽取的一步到位,同时解决了术语及类型不一致和所属多类型问题。
2、本发明采用的技术方案如下:一种术语及类型二元组单步抽取方法,利用融合依存结构和边界损失完成术语及类型二元组的单步抽取,其步骤如下:
3、步骤s1,构建中学数学术语数据集和构建依存关系集合;
4、步骤s2,定义术语及类型二元组抽取任务形式化;
5、步骤s3, 将步骤s1中的中学数学术语数据集输入到术语及类型二元组单步抽取模型,将数学文本输入到术语及类型二元组单步抽取模型的特征编码器中,获取数学文本中所有字嵌入特征向量;
6、步骤s4,将步骤s1构建的依存关系集合和步骤s3获得的字嵌入特征向量直接输入到术语边界提取器中,得到预测的术语边界标识系列,再通过交叉熵损失函数计算边界损失lm,优化更新特征编码器和术语边界提取器的模型参数,获得术语边界标识;
7、步骤s5,将步骤s3获得的字嵌入特征向量和步骤s4获得的术语边界提取器中的语义融合层输出的融合语义向量进行残差计算,将残差计算结果输入到二元组抽取器中,通过二元组抽取器的标识解码器解码得到初始二元组集合,同时通过交叉熵损失函数计算二元组损失lt;
8、步骤s6,对步骤s4得到边界损失lm和步骤s5得到二元组损失lt联合求和得联合损失l,并优化特征编码器、术语边界提取器与二元组抽取器的参数,达到术语边界提取和二元组抽取条件;
9、步骤s7,将术语边界标识和初始二元组集合输入到术语边界对齐模块,将术语边界标识对齐初始二元组集合的术语,将初始二元组集合内的二元组中未包含在术语边界标识中的术语连同二元组共同筛选出来,得到最终术语及类型二元组集合。
10、进一步的,步骤s1中构建中学数学术语数据集;具体为:
11、步骤s11,收集中学数学领域术语及类型抽取的句子,去除重复句子;
12、步骤s12,使用构建好的中学术语词典进行自动标注,同时为每个术语进行类型标注;
13、步骤s13,对标注结果进行标识一致性检验,即针对多个人对同一内容的标注结果进行相似性计算,取相似度高的标注结果;
14、步骤s14,将相似度高的标注结果进行检查和校正,保留符合要求的中学数学术语数据,构建中学数学术语数据集,并按照训练集:验证集:测试集为8:1:1的比例对中学数学术语数据集进行划分。
15、进一步的,步骤s1中构建依存关系集合,由斯坦福大学自然语言工具包中的依存句法分析模型直接抽取所得。
16、进一步的,步骤s2中定义术语及类型二元组抽取任务形式化,具体为:
17、定义包含n个数学文本的数据集为,每个数学文本s作为术语及类型二元组单步抽取模型输入,, 包含x种术语类型集合为;
18、其中,s1为第1个数学文本,s2为第2个数学文本,sn为第n个数学文本;为数学文本s中第1个字,为数学文本s中第2个字,为数学文本s中的第z个字,z是字的个数;为第1种术语类型,为第2种术语类型,为第x种术语类型,x为术语类型的个数;
19、定义含有5种术语边界标识集合为,含有4种二元组标识集合为;二元组抽取器的预测的术语及类型链接表为:
20、;
21、其中,为二元组抽取器预测的术语及类型链接表,为数学文本s中的第i个字,为数学文本s中第i个字第x种术语类型对应的预测标识,为多字术语的开始,为多字术语的中部,为多字术语的结束,为单字术语,为非术语;m表示术语边界,t表示二元组。
22、进一步的,步骤s3中特征编码器由预训练好的中文预训练bert模型构成,具体为:
23、将数学文本s中的第i个字输入到中文预训练模型bert中,获取对应的字嵌入特征向量,计算过程如公式(1)所示;
24、 (1);
25、其中,为数学文本s中的第i个字经过中文预训练模型bert得到的初始的第i个字嵌入特征向量。
26、进一步的,步骤s4中术语边界提取器,具体的提取步骤如下:
27、步骤s41,将获得的字嵌入特征向量和构建的依存关系集合输入到术语边界提取器中的依存信息构建层中,依存信息构建层将输入的依存关系集合转化成依存关系邻接矩阵和依存标识特征向量;
28、步骤s42,构建依存关系邻接矩阵,将存在依存关系的两个词各自包含的字相互之间构建无向连接边,得到对称的第一依存关系邻接矩阵;
29、其中,a是大小的矩阵,表示第一依存关系邻接矩阵a中的第i个字、第j个字对应的元素值,且存在关系的两个词所组成的字之间的元素值为1,否则为0;
30、步骤s43,构建依存标识特征向量,同样构造大小的矩阵,大小的矩阵中第i个字与第j个字对应的元素取值为0到u-1, u表示共有u种依存关系,利用嵌入函数获取依存标识特征向量;其中表示第i个字与第j个字之间的依存标识特征向量,dep表示依存标识;
31、步骤s44,在结构表示层中利用依存信息构建层构建好的依存标识特征向量对第一依存关系邻接矩阵的初始权重值进行优化更新,得到第二依存关系邻接矩阵,计算过程如公式(2)所示;
32、(2);
33、其中,表示第二依存关系邻接矩阵中的第i个字、第j个字对应的元素值,,表示级联操作,·表示内积操作,表示初始的第i个字嵌入特征向量和初始的第j个字嵌入特征向量;
34、接着,进一步融合依存标识特征向量和更新后的第二依存关系邻接矩阵,将初始的第j个字嵌入特征向量和第i个字与第j个字之间的依存标识特征向量的信息进行融合,赋予更新后的第二依存关系邻接矩阵的权重加权,再通过激活函数与初始的第j个字嵌入特征向量进行级联,得到最终结构特征向量;计算过程如公式(3)所示;
35、(3);
36、其中,为第i个字对应的图卷积神经网络最终结构特征向量,表示relu激活函数,为可学习的权重矩阵,表示结构表示层的偏置项;
37、步骤s45,利用双向长短期记忆网络层获取数学文本s中第i字对应的上下文语义特征向量,将初始的第i个字嵌入特征向量分别对应输入前向和后向的双向长短期记忆网络层中,计算过程如公式(4)所示;
38、(4);
39、其中,为第i字对应的上下文语义特征向量,分别表示前向长短期记忆网络的输出向量和后向长短期记忆网络的输出向量;
40、步骤s46,通过注意力机制将第i个字对应的图卷积神经网络最终结构特征向量与第i字对应的上下文语义特征向量在语义融合层进行融合,获得对应的融合语义向量,计算过程如公式(5)、公式(6)所示;
41、(5);
42、(6);
43、其中,为第i个字对应的融合语义向量,attention为注意力函数,分别表示查询向量、键向量和值向量,softmax为归一化指数函数,dd为查询向量和键向量的第二维度大小,t为查询向量和键向量的转置,分别表示自注意力机制时第i个字的查询向量、键向量和值向量的投影参数矩阵;、,表示对第i个字对应的图卷积神经网络最终结构特征向量进行线性变换的参数矩阵;
44、步骤s47,将第i个字对应的融合语义向量输入到标识预测层中,利用条件随机场模型对标识序列进行约束和预测得到所有的术语边界,输出预测的术语边界标识序列ym;预测计算如公式(7)所示,概率计算如公式(8)所示;
45、(7);
46、(8);
47、其中,表示预测的术语边界标识序列,表示第1个字预测的术语边界标识,表示第2个字预测的术语边界标识,表示第i个字预测的术语边界标识,表示第i-1个字预测的术语边界标识;表示输入为数学文本s的条件下得到预测的术语边界标识序列的概率,表示任意可能的术语边界标识序列,且,表示任意可能的术语边界标识序列中的第i个标识,表示可能的第i个术语边界标识的条件随机场层的权重矩阵,表示第i个字预测的术语边界标识的条件随机场层的权重矩阵,表示第i-1个字和第i个字预测的术语边界标识条件随机场层的偏置项;
48、步骤s48,将预测的术语边界标识序列和真实的术语边界标识序列输入到正则化的交叉熵损失函数,计算出术语边界损失,计算过程如公式(9)所示;
49、(9);
50、其中,为术语边界损失,表示第i个字预测的术语边界标识,表示第i个字真实的术语边界标识,,,表示输入为数学文本s的条件下第i个字预测的术语边界标识与第i个字真实的术语边界标识相同的概率;为正则化参数,为术语及类型二元单步抽取模型中所有特征向量的权重矩阵集合。
51、进一步的,步骤s5中二元组抽取器,具体的抽取步骤如下:
52、步骤s51,将初始的第i个字嵌入特征向量和第i个字对应的融合语义向量在残差层中进行残差计算即进行向量相加,得到融合特征向量作为二元组抽取器的输入到二元组预测层;
53、步骤s52,在二元组预测层中将术语与类型看成一个整体二元组,并为数学文本s构造x个术语类型的链接表,链接表大小统一为,每个链接表对应一个术语类型,接着利用评分函数对x个术语类型的链接表进行填充;
54、步骤s53,评分函数与残差层的输出无缝连接,通过参数矩阵自适应学习从术语特征到术语及类型对特征表示的映射函数,使用可学习的类型矩阵进行特征空间的转换,得出评分函数计算过程如公式(10)所示;
55、(10);
56、其中,为第x个术语类型链接表中第i个字对应的得分,表示可学习类型矩阵的转置,,表示实数空间,dim为嵌入维度,4是标识集合的标识总数,x为术语类型的个数,·表示内积,relu为激活函数,dropout表示随机失活函数,可防止过拟合,为线性函数中的参数矩阵,,表示 dim个嵌入维度乘dim个嵌入维度的实数空间,表示线性函数中的偏置项;
57、接着,通过归一化指数函数计算分类器对每种标识的分类概率,计算过程如公式(11)所示;
58、(11);
59、其中,表示输入为数学文本s的条件下得到二元组抽取器预测的术语及类型链接表的概率,softmax为归一化指数函数,为第i个字和第种术语类型对应的得分;
60、步骤s54,根据计算的每种标识的分类概率,采用交叉熵损失函数对二元组抽取器进行参数更新和优化得到二元组损失,计算过程如公式(12)所示;
61、(12);
62、其中,为二元组损失,为数学文本s中第i个字、第x种术语类型对应的预测标识,,为数学文本s中第i个字、第x种术语类型对应的真实标识,,表示二元组抽取器真实的术语及类型链接表;
63、步骤s55,针对输入为数学文本s的条件下得到的概率,在第x种术语类型链接表中填充上四种标识,在标识解码器中按照预设规则对术语及类型二元组进行解码。
64、进一步的,在标识解码器中按照预设规则对术语及类型二元组进行解码,具体为:
65、步骤s551,术语解码顺序按照数学文本从左到右逐字解码,共解码x种术语类型的链接表;
66、步骤s552,当识别到标识“”时,继续向右识别,直到识别到“”,即 “”到“”对应的文本区间就对应一个完整的多字术语;
67、步骤s553,当识别到标识“”时,即文本中的单字对应单字术语;
68、步骤s554,剩下的“”标识表示非术语,是无效标注,解码过程中可以跳过。
69、进一步的,在术语边界对齐模块中对二元组集合中的术语进行筛选,当二元组中的术语与术语边界不匹配,则将不匹配的二元组进去除。
70、另一方面,本技术提出:一种术语及类型二元单步抽取的模型,包括特征编码器、术语边界提取器、二元组抽取器、术语边界对齐模块四个大模块;
71、特征编码器分别连接术语边界提取器和二元组抽取器,术语边界提取器和二元组抽取器再分别连接术语边界对齐模块,术语边界提取器与二元组抽取器呈并行结构且进行数据交互;
72、术语边界提取器包括依存信息构建层、结构表示层、双向长短期记忆网络层、语义融合层、标识预测层,特征编码器分别连接依存信息构建层和双向长短期记忆网络层,依存信息构建层链接结构表示层,依存信息构建层和结构表示层是串行结构,依存信息构建层和结构表示层与双向长短期记忆网络层是并行结构;结构表示层和双向长短期记忆网络层分别连接语义融合层,语义融合层连接标识预测层,标识预测层连接术语边界对齐模块;
73、二元组抽取器包括残差层、二元组预测层和标识解码层,残差层连接二元组预测层,二元组预测层连接标识解码层,标识解码层链接术语边界对齐模块。
74、本发明的优点:(1)本发明从新的视角,通过构建术语及类型链接表,将术语及类型抽取问题转化成了二元组抽取任务,统一了两个任务的抽取模型并实现一步到位的抽取效果,且实现了不同语境下术语所属类型不一致、同一术语对应多种类型等复杂场景下的术语抽取;(2)本发明采用联合抽取术语及类型的方式,解决了术语抽取到类型分类这一过程存在的不可逆的误差传递问题;(3)针对数学知识表示的强逻辑性、结构性和多样性,本发明引入术语边界提取器,与二元组抽取任务进行联合训练,在为字嵌入特征向量融入结构信息的同时缓解结构信息自身带来负面影响,在提高术语边界的识别精度的同时提升了二元组抽取的准确性。
- 还没有人留言评论。精彩留言会获得点赞!