曲线模式分段的半导体制造无监督异常检测方法及设备与流程
本发明涉及半导体制造异常检测,具体涉及一种曲线模式分段的半导体制造无监督异常检测方法、设备及存储介质。
背景技术:
1、随着科技的不断发展,半导体产品开始应用在生活的方方面面。半导体产品的异常检测对于半导体产品的质量控制具有重要意义。然而半导体制造是一个历经多过程多设备的复杂加工过程,传统的异常检测方法通过检测半导体最终成品的各项参数是否满足设定要求来判断该产品是否异常。该方法虽然准确率高,但是由于检测的对象是最终半导体成品,因此不能及时检测加工过程中出现的异常,从而效率较低,且异常产品继续加工浪费后续的设备资源。
2、随着智能制造的发展,目前半导体制造引入了众多的传感器对半导体制造过程进行监控。这些传感器收集半导体加工过程的压强,温度和光强等几十个参数,可以有效表征半导体加工过程是否发生异常。目前已有很多方法通过分析半导体加工过程的传感器监控参数变化曲线来检测半导体加工过程是否发生异常。这些方法主要分为包括整段分析方法和逐点分析方法。整段分析方法通过机器学习,统计学习等算法学习正常和异常半导体加工过程传感器监控曲线的不同模式来构建异常与正常的分类边界,从而可以检测出异常。然而整段学习方法容易忽略监控曲线中细小的异常,容易产生漏报。逐点分析方法通过分析传感器监控曲线每个监控点与历史大量监控曲线该监控点的分布情况进行对比来分析是否发生异常,然而这种方法容易将正常加工过程误分类为异常过程,从而产生大量误报。
3、机器学习可以自主学习特征,尤其是有监督的方法可以学习标签与特征之间的映射关系。但在工业制造场景中,传感器的序列长度长,数据特征维度高,这意味着许多时间点的特征与故障无关,影响机器学习的性能。无监督的分类方法一般是寻找正常样本的边界,但如果不配合较强的特征提取模型,效果也差强人意。分类模型通常希望预先进行有效的特征降维或者特征提取,以达到更好地分类效果。
4、半导体制造是一个复杂的过程,涉及多种加工步骤,包含多种物理过程。不同的物理过程反应到传感器数据上,呈现出不同的曲线模式,例如阶跃函数代表开关开断,振荡过程代表振动或欠阻尼驱动,尖峰代表瞬时扰动等。传统的统计学方法,其统计特征表征能力不强,并且依赖于数据分布假设,因此分类的准确度不高,存在大量误报。而依据制程划分管控窗口再提取统计特征,虽然效果有提升,单依旧受到同一制程内不同曲线模式的影响。
5、深度学习是目前表现最好的特征提取方法,但在实际应用中深度学习往往在耗费资源和处理时间上不尽人意。而其他的特征提取方法尤其统计学特征提取速度快、耗费资源少,但表征能力不强。因此行业需要处理速度更快、耗费资源更少,同时特征提取能力较强的方法。本发明提出的目的意在解决这类问题。
技术实现思路
1、本发明提出的一种曲线模式分段的半导体制造无监督异常检测方法、设备及存储介质,可至少解决背景技术中的技术问题之一。
2、为实现上述目的,本发明采用了以下技术方案:
3、一种曲线模式分段的半导体制造无监督异常检测方法,包括以下步骤,
4、收集半导体加工设定一段时间正常加工的数据作为训练样本数据;
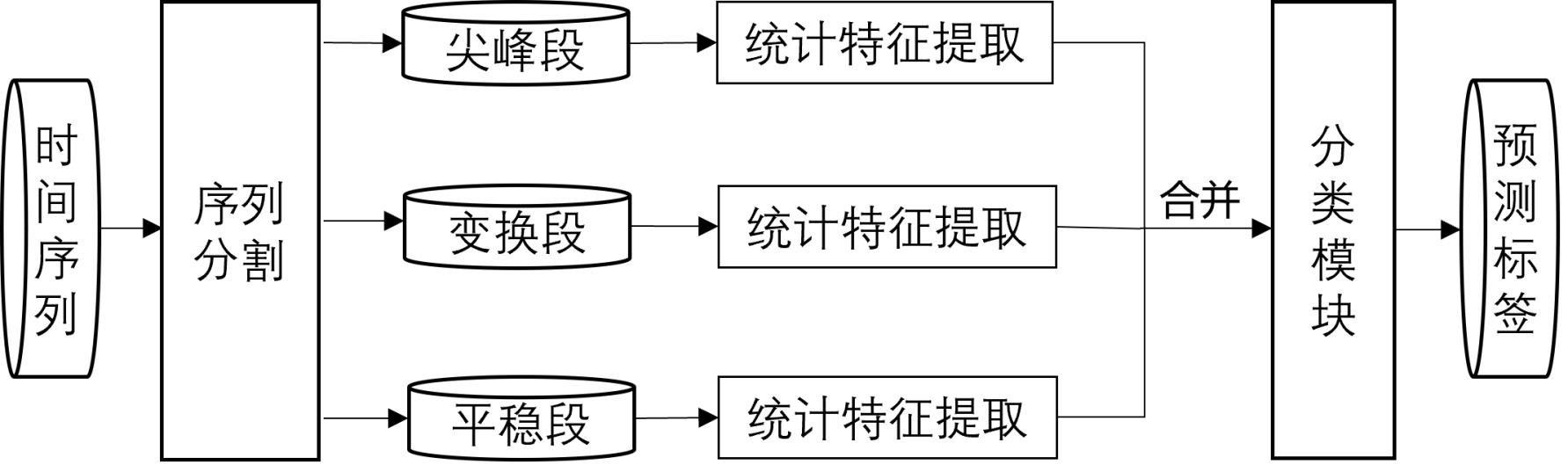
5、采用信号处理技术对训练样本数据进行处理,即对传感器曲线进行模式分割,之后针对不同的曲线模式提取不同的统计特征;
6、再把提取不同的特征输入到机器学习算法中进行学习,构建基于密度的局部异常因子检测的无监督机器学习分类模型,用于对半导体产品的异常检测。
7、进一步地,信号处理技术包括进行数据预处理步骤,
8、在获得一批样本数据进行插值后,首先要剔除噪声数据,采用的方法是lof离群样本检测,剔除不集中的样本;
9、之后为了进行窗口划分为传感器计算代表样本,采用的方法分两步:进行动态时间翘曲和求代表性曲线;
10、动态时间翘曲是进行数据对齐的算法,具体如下:
11、假设有两个时间序列q和c,长度分别为n和m,具体表示为:
12、
13、
14、首先计算一个距离的映射矩阵,矩阵的元素是表示为对应两点的平方差,计算公式如下:
15、
16、之后在距离矩阵中从到之间寻找一条最优翘曲路径;翘曲路径定义为映射矩阵元素的连续集合,其第 k个元素被定义为,此时有:
17、
18、其中
19、翘曲路径需要满足所有元素之和是最小的,即:
20、
21、将累计距离定义为当前单元距离和相邻累计距离的最小值之和,公式如下:
22、
23、选择一条参考曲线,将所有训练样本对齐后,对每一个时间点的数值求平均,得到一条代表性曲线,具体计算公式如下:
24、
25、其中,s代表样本个数,t代表时间点数,代表传感器的时间序列。
26、进一步地,对传感器曲线进行模式分割包括,
27、首先进行尖峰模式的识别,采用连续小波变换的方法进行尖峰重构,筛选出候选区域;
28、信号的连续小波变换是其本身与小波母函数卷积得到的,具体公式如下:
29、
30、其中,是特定小波母函数的收缩和偏移形式,s和b分别代表收缩尺度和平移参数;
31、选择母小波和卷积参数,涉及最小尺度、最大尺度、最大频率成分、最小频率成分、母函数阶数m和中心频率;
32、具体计算公式如下:
33、
34、
35、
36、
37、其中,表示信号的最大频率范围,表示采样频率,表示频率的最低分辨率,表示采样间隔;
38、小波变换后得到一个信号与不同收缩尺度母函数卷积后形成的系数矩阵;
39、为了进行尖峰信号重构,要进行滤波,将与尖峰相关尺度较低的成分滤除;
40、采用的是中值绝对偏差阈值法;阈值的计算公式如下:
41、
42、其中表示cwt矩阵在地个时间点、第个尺度的系数,n为信号的长度,;
43、根据去噪的连续小波变换系数矩阵进行重构信号,数值非零的区域即为尖峰模式段的候选区域;
44、下一步利用极值法筛选出真实的尖峰区域,即检验候选区域中是否存在满足极值条件的点,它的边界定义为尖峰点临近的极小值点或者区域的临界点;
45、在进行变化段和稳态段的识别之前,将尖峰段去除;去掉尖峰后,在尖峰区域内采用线性插补的方法补齐数据;最后进行变化段和稳态段的识别;
46、采用基于滑动窗口的标准偏差结合聚类的方法自动区分变化段和稳态段;用滑动窗口法将去除尖峰的信号分成多个子序列,每个子序列求标准偏差,计算公式如下:
47、
48、其中n表示窗口的大小,表示第i个点,表示窗口内的平均值;表示第j个子序列;
49、计算出每个子序列的标准偏差后,用k-means聚类方法将子序列样本分为两类,偏差值较高的为变化段,较低的为稳态段;
50、获取每个子序列的标签后,进行窗口合并,得到变化段和稳态段的索引;之后检验尖峰模式是否与变化段和稳态段的索引重合,如若重合,进行分离,最终完成曲线模式分割,将信号分为三种模式。
51、进一步地,针对不同的曲线模式提取不同的统计特征,包括,
52、计算尖峰突显程度作为尖峰模式的特征,即峰峰值;
53、传感器数据的变化段是斜坡,计算对应的斜率、最大值、最小值、变化时间和曲线下面积作为变化段的特征;
54、计算平均值、标准偏差、最大值和最小值作为表征平稳段的特征。
55、进一步地,构建基于密度的局部异常因子检测的无监督机器学习分类模型,实现精准的异常检测,具体包括,
56、收集半导体加工设定一段时间正常加工的数据作为训练样本,依据对样本进行处理和特征提取后,使用lof无监督方法建立单分类模型;
57、首先计算所有训练数据的离群程度得分,剔除训练样本中的离群样本,防止其影响单分类模型的性能,之后依据纯净的正常数据构建无监督的异常检测模型;
58、lof无监督方法是基于密度的单分类方法,它包括输入样本后,第一步计算每个样本的第k距离领域内各样本的第k可达距离,计算公式如下:
59、
60、其中p表示要计算的样本,即邻域中心,o表示邻域内的样本,表示p的第k邻域内样本o的第k距离,表示o到p的距离,距离公式选择欧式距离;第k距离指样本中心与距离其第k远的样本之间的距离,第k邻域指样本中心第k距离内的所有邻近样本;
61、第二步计算每个样本的第k局部可达密度,计算公式如下:
62、
63、其中表示p点的第k距离邻域,包括第k距离上的点,;
64、第三部计算每个样本的局部离群因子,计算公式如下:
65、
66、局部离群因子将p的邻域内所有样本的平均局部可达密度与p的局部可达密度作比较,比值越大于1,表明p的密度越小,越可能是异常点;比值越小于1,表明p的密度大,p点越是正常。
67、又一方面,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述方法的步骤。
68、再一方面,本发明还公开一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如上方法的步骤。
69、由上述技术方案可知,本发明的一种基于曲线模式分段的半导体制造无监督异常检测方法,该方法为传感器监控参数曲线按照模式(包括平稳模式,变化模式和尖峰模式)不同分成若干段,再为这些阶段提取不同的特征输入到机器学习算法中进行学习,得到一个可以判断半导体是否发生异常的分类器。考虑到实际中异常制造过程极少出现,本专利采用无监督机器学习算法仅仅学习正常加工过程传感器监控曲线的分类边界,超出边界则认为是异常。
70、本发明的一种基于曲线模式分段的半导体制造无监督异常检测方法。该方法认为不同的曲线模式需要提取的特征是不同的,首先采用信号处理技术对传感器曲线进行模式分割,这一步的目的是依据曲线模式自动划分管控窗口,解决了人工参与过多和窗口划分不合理的问题。之后针对不同的曲线模式提取不同的统计特征,进行快速、高效的特征提取。最后构建基于密度的局部异常因子检测(local outlier factor,lof)的无监督机器学习分类模型,实现精准的异常检测。
71、本发明提出了一种结合曲线模式分割的无监督故障检测方法,针对不同的敏感模式计算不同的统计特征,实现高效、快速的特征提取。采用基于密度的局部离群因子的方法,构建高准确度、高效率的无监督机器学习模型,实现高性能的单变量异常检测方法。经过实际测试,本发明的准确性高、耗费的计算资源低,能进行快速的在线故障检测。
- 还没有人留言评论。精彩留言会获得点赞!