基于贫样本层次可信聚类热力图的软件性能可视评价方法
本发明涉及软件性能评价领域,尤其涉及一种基于贫样本层次可信聚类热力图的软件性能可视评价方法。
背景技术:
1、软件性能优劣往往是用户在多款功能相似的软件中选择适用工具时需考虑的重要因素。软件性能指标数据往往需通过测试获得,受测试环境不确定性的影响,即使采用相同的测试工具和测试用例对同一款软件进行多次重复测试所得的同一性能指标值也往往存在一定的波动。软件性能响应数据包括执行各类性能测试用例时所需的响应时间、内存占用量等不同类型,各类数据具有不同的量纲和不同的数量级,其值难以直接反映软件性能的优劣。此外,现有基于纯数学运算处理的软件性能评价方法不够直观。
技术实现思路
1、现有基于测试数据的软件性能评价方法没有考虑若干次重复测试所得不确定性测试数据数学描述方式对评价结果可信度的影响,且不够直观。本发明的目的在于提供一种基于贫样本层次可信聚类热力图的软件性能可视评价方法,该方法针对样本较少的性能测试数据建立各性能指标的区间描述并计算其可信度,从而利用贫样本数据获得性能指标的可信得分,进而通过绘制层次可信聚类热力图直观呈现性能测试数据中所蕴含的软件性能优劣信息。
2、本发明的目的是通过以下技术方案来实现的:一种基于贫样本层次可信聚类热力图的软件性能可视评价方法,包括如下步骤:
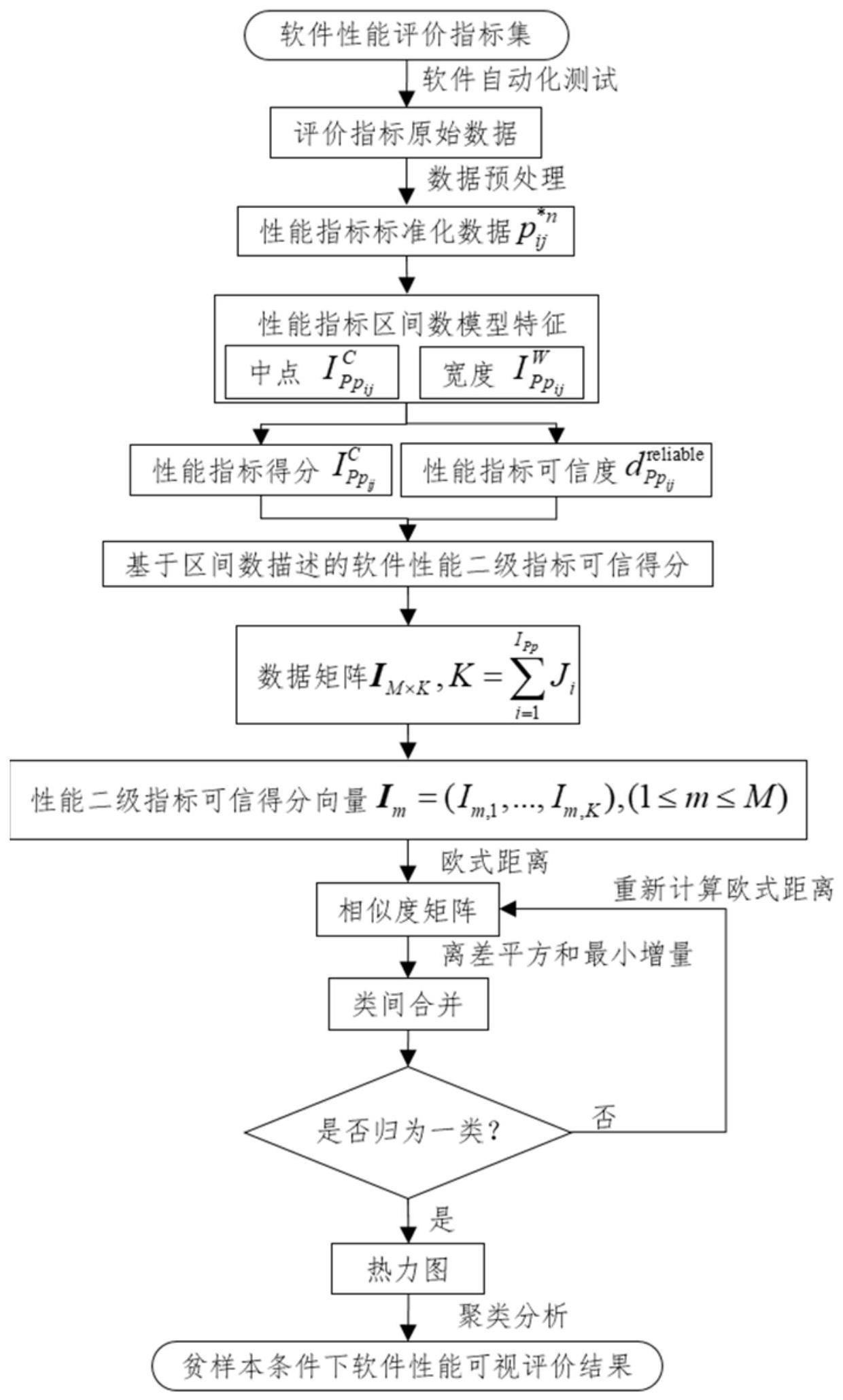
3、s1:确定软件性能评价指标集,包括性能一级指标ppi,1≤i≤ipp及其下属的性能二级指标ppij,1≤j≤ji,其中,ipp为性能一级指标个数,ji为性能一级指标ppi下的性能二级指标个数;
4、s2:执行n次测试,获取各性能二级指标的原始测试数据,并进行标准化处理得到标准化数据;
5、s3:依据性能评价指标的一系列标准化数据n=1,2,…,n建立区间数其中获取中点表示性能二级指标得分,宽度表示性能二级指标得分的不确定性,性能二级指标的不确定度为可信度为
6、s4:将各性能二级指标得分与可信度相乘,获得贫样本条件下基于区间数描述的软件性能二级指标可信得分
7、s5:假设有m款软件进行比较,每款软件的性能二级指标可信得分为im,k,1≤m≤m,1≤k≤k,其中k为所有一级指标对应的二级指标的个数之和,即将im,k,1≤m≤m,1≤k≤k整合为一个包含各款软件所有性能二级指标可信得分的二维数据矩阵ιm×k,ιm×k中的每一行im=(im,1,...,im,k),1≤m≤m为第m款软件所有性能二级指标可信得分构成的性能二级指标可信得分向量;从ιm×k中选取任意两个性能二级指标可信得分向量和1≤m1,m2≤m,m1≠m2,计算其欧式距离进而计算其相似度
8、s6:初始时,两个性能二级指标可信得分向量和均各自组成一个单独的簇,分别为簇m1和簇m2,当这两簇合并时,离差平方和增量其中和分别为簇m1和簇m2中向量的个数,和分别为簇m1和簇m2的中心向量;
9、计算所有两簇合并可能下的离差平方和增量,选取离差平方和增量最小的合并情况,将对应的两簇合并为一个新簇,其他簇保持不变,为旧簇;
10、s7:重新计算新簇和旧簇组成的簇集合中任意两个簇间的相似度;
11、s8:重复s6和s7,直到所有性能二级指标可信得分向量归为一簇,获得层次可信聚类后的热力图;
12、s9:对层次可信聚类热力图进行聚类分析,直观获得软件性能可视评价结果。
13、进一步地,步骤s2中,对性能二级指标ppij的总共n个原始测试数据中的第n个数据样本若ppij为效益型指标,即越大反映对应的软件性能越好,则标准化数据若ppij为成本型指标,即越大反映对应的软件性能越差,则标准化数据其中和分别为所有参与测试的软件的同一性能二级指标ppij对应的响应数据最大值和最小值。
14、本发明的有益效果是:
15、(1)利用区间数来描述贫样本条件下软件性能指标的不确定性,进而计算各性能指标的可信度,在性能指标量化过程中充分考虑了软件性能测试数据中所蕴含的区间不确定性的影响,获得了基于区间数的软件性能指标可信得分。
16、(2)利用软件性能指标的可信得分构造了层次聚类热力图,能够直观地反映不同软件各类别性能指标的相似度,进而直观地分析软件各类性能的优劣,克服了现有侧重于通过数学建模与运算获得软件性能评分的方法过于抽象的不足。
技术特征:
1.基于贫样本层次可信聚类热力图的软件性能可视评价方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于贫样本层次可信聚类热力图的软件性能可视评价方法,其特征在于,所述s2中,对性能二级指标ppij的总共n个原始测试数据中的第n个数据样本若ppij为效益型指标,即越大反映对应的软件性能越好,则标准化数据若ppij为成本型指标,即越大反映对应的软件性能越差,则标准化数据其中和分别为所有参与测试的软件的同一性能二级指标ppij对应的响应数据最大值和最小值。
技术总结
本发明公开了一种基于贫样本层次可信聚类热力图的软件性能可视评价方法。将贫样本条件下的数据集进行标准化处理,通过区间数建立各性能指标的数学描述并计算其可信度,从而获得软件性能二级指标可信得分。将各软件性能二级指标可信得分整合为一系列可信得分向量,通过欧式距离计算两个可信得分向量间的相似度,根据离差平方和最小增量原则选取最相似的两个向量进行类间合并。当所有向量归为一类时,得到层次聚类热力图,对其进行聚类分析,获得软件性能评价结果。提出的方法考虑了样本数据量较少情况下通过自动化测试获得的性能数据的波动,运用可视化技术实现对软件性能的评价,结果直观可信。
技术研发人员:程锦,叶虎强,谭建荣,刘振宇
受保护的技术使用者:浙江大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!