一种模型构建方法、装置、设备及计算机存储介质与流程
本技术属于联邦学习,尤其涉及一种模型构建方法、装置、设备及计算机存储介质。
背景技术:
1、随着互联网、大数据、人工智能技术的高速发展,各行业所掌握的数据量呈几何级数增长,为了在保证数据安全的前提下充分利用多行业、多用户的数据,通常采用联邦学习的方式来实现多个用户的数据联合建模。
2、目前,横向联邦学习是将初始模型算法发送给每个用户,每个用户利用自己的数据来计算初始模型的梯度,然后基于每个用户提供的梯度更新模型参数,以得到最终的目标模型。然而,由于每个用户的算力资源存在差异,因此每个用户计算梯度所需时间不同,需要等待全部的用户都完成梯度计算后才能够生成目标模型,导致目标模型构建效率较低。
技术实现思路
1、本技术实施例提供一种模型构建方法、装置、设备及计算机存储介质,能够提高目标模型的搭建效率。
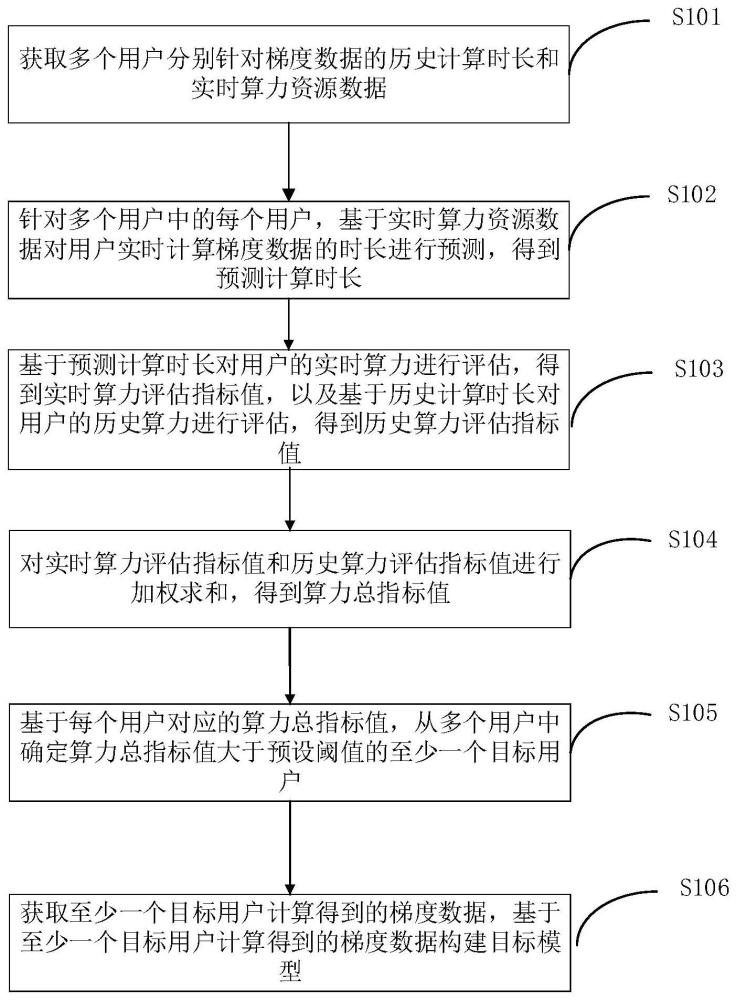
2、第一方面,本技术实施例提供一种模型构建方法,方法包括:
3、获取多个用户分别针对梯度数据的历史计算时长和实时算力资源数据;其中,梯度数据是与目标模型对应的数据;
4、针对多个用户中的每个用户,基于实时算力资源数据对用户实时计算梯度数据的时长进行预测,得到预测计算时长;
5、基于预测计算时长对用户的实时算力进行评估,得到实时算力评估指标值,以及基于历史计算时长对用户的历史算力进行评估,得到历史算力评估指标值;
6、对实时算力评估指标值和历史算力评估指标值进行加权求和,得到算力总指标值;
7、基于每个用户对应的算力总指标值,从多个用户中确定算力总指标值大于预设阈值的至少一个目标用户;
8、获取至少一个目标用户计算得到的梯度数据,基于至少一个目标用户计算得到的梯度数据构建目标模型。
9、在一些实施例中,在基于预测计算时长对用户的实时算力进行评估,得到实时算力评估指标值之前,方法还包括:
10、按照多个用户的预测计算时长的大小对多个用户进行排序,得到排序结果;
11、基于预测计算时长对用户的实时算力进行评估,得到实时算力评估指标值,包括:
12、根据用户在排序结果中的排序位置,将排序位置对应的预设实时算力评估指标值确定为用户的实时算力评估指标值。
13、在一些实施例中,基于历史计算时长对用户的历史算力进行评估,得到历史算力评估指标值,包括:
14、获取多个历史时间段内的历史计算时长,根据多个历史时间段内的历史计算时长构建多维特征向量;
15、将用户的多维特征向量与多个预设特征向量进行比对,确定多维特征向量的所属预设多维特征向量;预设多维特征向量是在多个用户的多维特征向量中确定的;
16、将多维特征向量的所属预设特征向量对应的预设算力评估指标值确定为用户的历史算力评估指标值。
17、在一些实施例中,在实时将用户的多维特征向量与多个预设特征向量进行比对,确定多维特征向量的所属预设特征向量之前,还包括:
18、对多个多维特征向量取平均值,得到首个预设特征向量;
19、计算每个多维特征向量与首个特征向量之间的欧式距离;
20、在多个欧式距离中确定最大欧式距离,将最大欧式距离对应的多维特征向量确定为非首个目标特征向量;
21、计算每个多维特征向量到首个目标特征向量以及前k-2个目标特征向量的距离和值;其中,k为大于2的整数;
22、在多个距离和值中确定最大距离和值,将最大距离和值对应的多维特征向量确定为第k个非首个目标特征向量;
23、将k赋值为k+1,返回执行计算每个多维特征向量到前k-2个预设特征向量的距离和值的步骤,直至k=k-2,得到k-1个非首个预设特征向量;其中,k为大于1的整数;k小于或等于k-2;
24、基于首个预设特征向量和k-1个非首个目标特征向量,得到k个预设特征向量。
25、在一些实施例中,将用户的多维特征向量与多个预设特征向量进行比对,确定多维特征向量的所属预设特征向量,包括:
26、计算多维特征向量到每个预设特征向量的欧式距离;
27、在多维特征向量到每个预设特征向量的欧式距离中确定欧式距离最小值;
28、将欧式距离最小值对应的预设特征向量确定为多维特征向量的所属预设特征向量。
29、在一些实施例中,针对多个用户中的每个用户,基于实时算力资源数据对用户实时计算梯度数据的时长进行预测,得到预测计算时长,包括:
30、将实时算力资源数据输入至预设的二叉树决策模型;
31、利用二叉树决策模型基于每个用户的实时算力资源数据,对每个用户实时计算梯度数据的时长进行预测,输出得到预测计算时长。
32、在一些实施例中,在将实时算力资源数据输入至预设的二叉树决策模型之前,方法还包括:
33、获取多个用户的历史算力资源数据以及每个历史算力资源数据对应的计算时长;
34、根据多个用户的历史算力资源数据依次确定二叉树决策模型的节点对应的取值范围;
35、根据二叉树决策模型的每个路径中每个节点的取值范围,在每个历史算力资源数据对应的计算时长中分别匹配得到每个路径对应的计算时长取值,得到二叉树决策模型。
36、在一些实施例中,每个历史算力资源数据包括至少一种资源类型的资源数据;根据多个用户的历史算力资源数据依次确定二叉树决策模型的节点对应的取值范围,包括:
37、根据目标数据集中属于同一资源类型的任意两个资源数据,以及任意两个资源数据所属的历史算力资源数据对应的计算时长,计算任意两个资源数据对应的平方误差函数值,得到多个平方误差函数值;目标数据集中包括多个历史算力资源数据;
38、在多个平方误差函数值中确定最小值;
39、将最小值对应的两个资源数据的中位数作为分割点,对目标节点所指示的目标取值范围进行分割处理,得到目标节点的第一子节点所指示的第一取值范围和第二子节点所指示的第二取值范围;
40、按照第一取值范围和第二取值范围对目标数据集进行分割处理,得到第一取值范围和第二取值范围分别对应的数据集;
41、在数据集中历史算力资源数据的数据量大于1的情况下,将数据集作为新的目标数据集,将新的目标数据集对应取值范围所在的子节点作为新的目标节点,返回执行根据目标数据集中属于同一资源类型的任意两个资源数据,以及任意两个资源数据所属的历史算力资源数据对应的计算时长,计算任意两个资源数据对应的平方误差函数值,得到多个平方误差函数值,直至对目标取值范围进行分割处理的次数达到预设次数,得到二叉树决策模型的每个节点对应的取值范围。
42、第二方面,本技术实施例提供一种模型构建装置,包括:
43、获取模块,用于获取多个用户分别针对梯度数据的历史计算时长和实时算力资源数据;其中,梯度数据是与目标模型对应的数据;
44、预测模块,用于针对多个用户中的每个用户,基于实时算力资源数据对用户实时计算梯度数据的时长进行预测,得到预测计算时长;
45、评估模块,用于基于预测计算时长对用户的实时算力进行评估,得到实时算力评估指标值,以及基于历史计算时长对用户的历史算力进行评估,得到历史算力评估指标值;
46、加权求和模块,用于对实时算力评估指标值和历史算力评估指标值进行加权求和,得到算力总指标值;
47、确定模块,用于基于每个用户对应的算力总指标值,从多个用户中确定算力总指标值大于预设阈值的至少一个目标用户;
48、构建模块,用于获取至少一个目标用户计算得到的梯度数据,基于至少一个目标用户计算得到的梯度数据构建目标模型。
49、第三方面,本技术实施例提供一种模型构建设备,设备包括:处理器以及存储有计算机程序指令的存储器;
50、处理器执行计算机程序指令时实现如第一方面任意一项的模型构建方法。
51、第四方面,本技术实施例提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序指令,计算机程序指令被处理器执行时实现如第一方面任意一项的模型构建方法。
52、第五方面,本技术实施例提供一种计算机程序产品,计算机程序产品中的指令由电子设备的处理器执行时,使得电子设备执行如第一方面任意一项的模型构建方法。
53、本技术实施例的一种模型构建方法、装置、设备及计算机存储介质,能够根据用户的历史梯度计算时长确定用户的历史算力评估指标值,根据用户的实时算力资源数据预测出的梯度计算预测时长,对用户的历史算力评估指标值以及梯度计算预测时长进行加权求和,以得到用于综合评估用户算力的算力总指标值,根据算力总指标值确定出算力资源较高的目标用户,仅基于目标用户提供的梯度来构建目标模型,无需等待全部用户都计算出梯度之后再构建目标模型,有效减少了等待时间,提高了目标模型的搭建效率。
- 还没有人留言评论。精彩留言会获得点赞!