基于人工智能的气管插管关键结构识别模型系统及构建方法与流程
本发明涉及人工智能医疗急救,具体为基于人工智能的气管插管关键结构识别模型系统及构建方法。
背景技术:
1、可视喉镜的运用显著降低了急救相关专业人员完成气管插管的难度,但并非意味着其他专业急救人员完成气管插管也同样容易。急救气管插管还需要进行气管结构是否正常、是否适合进行插管等及时判断,快速完成关键临床决策。
2、气管插管决策通常需要长期临床实践的积累,而通常很难在普通的模拟人气管插管训练中获得。非医疗专业的现场施救人员在进行急救技术训练时,更加难以在短时间内形成这种判断能力。目前我国的急救体系中,最快到达急救现场的,又往往不是医疗专业人员。同时声门容易被其他组织(如会厌、肿瘤等组织)遮挡,其暴露过程中的形状不唯一,且急救场景下容易被异物干扰。因此,开发一种高灵敏性、特异性的基于人工智能的声门关键结构识别模型,在气管插管过程中,提供准确的声门结构识别和关键特征定位,能够帮助现场早期施救者及时决策,快速施救,减少病人的不适与损伤,对于提高气管插管的准确性和安全性具有重要意义。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了基于人工智能的气管插管关键结构识别模型系统及构建方法,解决了缺少一种高灵敏性、特异性的基于人工智能的声门关键结构识别模型的问题。
3、(二)技术方案
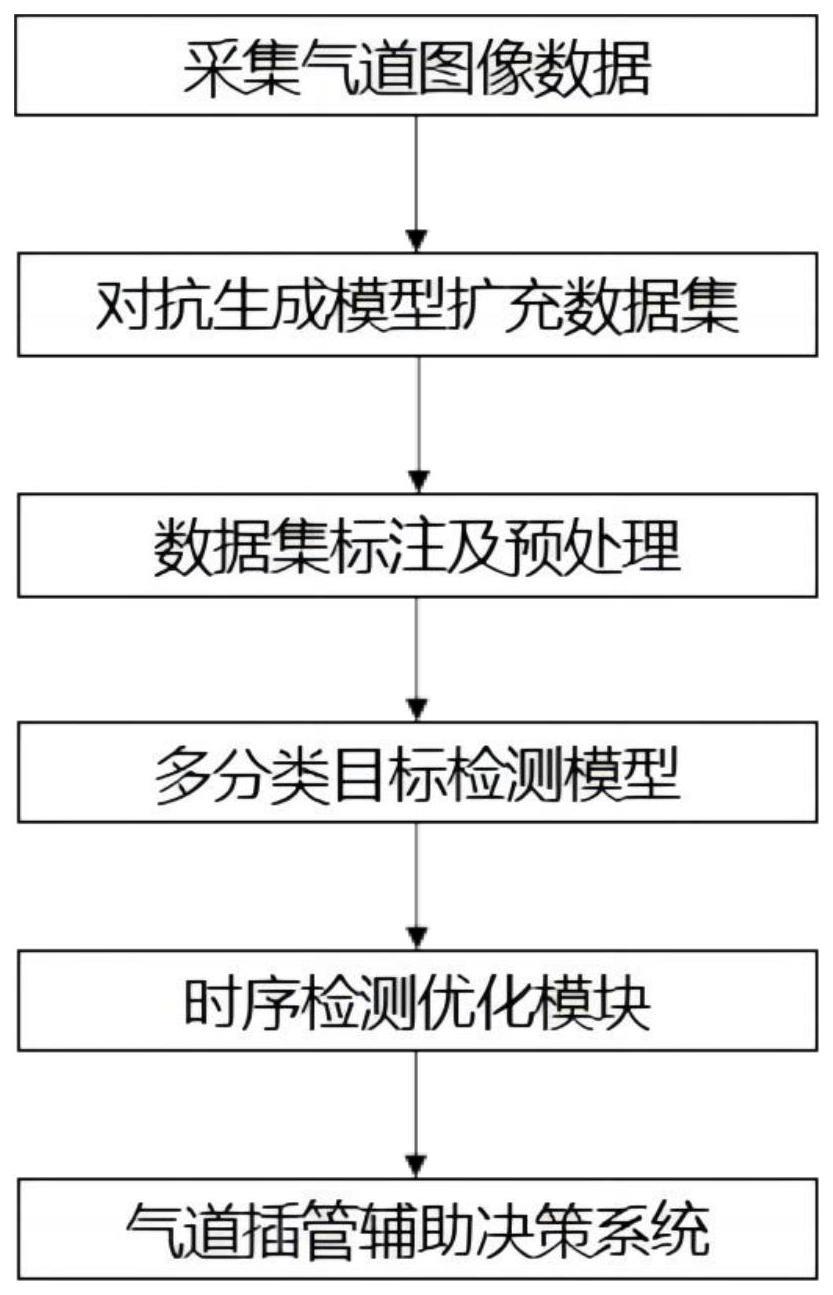
4、为实现以上目的,本发明通过以下技术方案予以实现:基于人工智能的气管插管关键结构识别模型系统,包括采集气道图像数据,所述采集气道图像数据连接有对抗生成模型扩充数据集,所述对抗生成模型扩充数据集连接有数据集标注及预处理;
5、所述数据集标注及预处理连接有多分类目标检测模型,所述多分类目标检测模型连接有时序检测优化模块,所述时序检测优化模块连接有气管插管辅助决策系统。
6、基于人工智能的气管插管关键结构识别模型构建方法,具体包括以下步骤:
7、s1.获得扩充数据集
8、采集若干目标画面,并使用对抗生成网络获得扩充数据集;
9、s2.图像框选标注
10、对步骤s1中获取的扩充气道图像使用cvat进行会厌软骨及声门结构的框选标注,得到yolo格式的标注文件;
11、s3.标注及预处理
12、对扩充后的数据进行关键结构的标注及预处理;
13、s4.建立检测模型
14、通过训练集和验证集以yolov5模型为框架训练一个针对会厌软骨和声门结构的检测模型;
15、s5.数据时序优化
16、对视频数据的检测进行了时序上的优化,考虑不同帧的时间上下文关系;
17、s6.决策实施
18、通过部署方式、环境要求和生成诊断结果进行插管决策系统的实施。
19、优选的,所述步骤s1中在急救场景下的气管插管图像数据往往难以获得,整体样本量较小,对于训练数据量有限的问题,需使用了一种高效的生成对抗网络,合成新的气管插管图像,用于声门结构的识别任务。
20、优选的,所述步骤s2中cvat标注的数据导出为yolo目标检测任务的一般格式为jpg或txt,且每张图像的标签存储在同一名称下的txt文件中。
21、优选的,所述步骤s3中数据增强预处理为通过对训练数据进行一系列变换和扩充,进一步提高模型的泛化能力,防止过拟合,以及使模型更加鲁棒,本方法中是对数据进行颜色、尺度维度随机的数据增强处理。
22、优选的,所述步骤s4中使用yolov5m框架及预训练模型,以yolov5使用cspdarknet作为主干网络,以及fpn和panet进行多尺度特征融合,能够较好地兼顾精度与性能表现,预训练模型已经在大规模数据集上进行了训练,并且学习到了丰富的特征表示,且yolov5网络的损失函数包括检测框损、置信度误差损失和分类误差损失。
23、优选的,所述步骤s5中需逐一对视频不同帧进行目标检测,产生对目标的预测信息,当超过设置的置信度阈值则表示检测到目标,但由于摄像头晃动,异物干扰,光照因素影响,视频检测会存在检测框闪烁的问题,而基于检测目标在时序上应该是稳定出现的,本方法将前若干帧超过一定阈值的预测值与本帧检测出的预测值累加,使检测模型获得记忆能力,提高检测的稳定性,同时考虑气管插管场景中会厌软骨及声门结构的先后逻辑顺序,将历史帧累积的声门预测概率使用一定权重去抑制会厌软骨的预测概率,即对于不符合前后关系的置信度进行抑制,从而进一步减少误判情况。
24、(三)有益效果
25、本发明提供了基于人工智能的气管插管关键结构识别模型系统及构建方法。具备以下有益效果:
26、本发明提供了基于人工智能的气管插管关键结构识别模型系统及构建方法,用本发明于准确识别和定位气管插管图像/视频中的声门、会厌软骨关键结构,并为气管插管提供智能辅助决策,其中方法包括:使用基于对抗生成网络及数据增强的扩充数据集,结合yolov5目标检测模型进行气管中多个关键结构的识别,准确定位当前图像/视频中的关键结构位置,并对视频数据进行了时序检测优化,降低画面干扰或某些罕见图像形态的影响,提高了检测稳定性和准确率,最终将模型部署到云平台通过手机端运行形成气管插管辅助决策系统,从而使得本发明在气管插管过程中,能够提供准确的声门结构识别和关键特征定位,能够帮助现场早期施救者及时决策,快速施救,减少病人的不适与损伤,对于提高气管插管的准确性和安全性具有重要意义。
技术特征:
1.基于人工智能的气管插管关键结构识别模型系统,包括采集气道图像数据,其特征在于:所述采集气道图像数据连接有对抗生成模型扩充数据集,所述对抗生成模型扩充数据集连接有数据集标注及预处理,所述数据集标注及预处理连接有多分类目标检测模型,所述多分类目标检测模型连接有时序检测优化模块,所述时序检测优化模块连接有气管插管辅助决策系统。
2.基于人工智能的气管插管关键结构识别模型的构建方法,其特征在于,具体包括以下步骤:
3.根据权利要求2所述的基于人工智能的气管插管关键结构识别模型的构建方法,其特征在于:所述步骤s1中在急救场景下的气管插管图像数据往往难以获得,整体样本量较小,对于训练数据量有限的问题,需使用了一种高效的生成对抗网络,合成新的气管插管图像,用于声门结构的识别任务。
4.根据权利要求2所述的基于人工智能的气管插管关键结构识别模型的构建方法,其特征在于:所述步骤s2中cvat标注的数据导出为yolo目标检测任务的一般格式为jpg或txt,且每张图像的标签存储在同一名称下的txt文件中。
5.根据权利要求2所述的基于人工智能的气管插管关键结构识别模型的构建方法,其特征在于:所述步骤s3中数据增强预处理为通过对训练数据进行一系列变换和扩充,进一步提高模型的泛化能力,防止过拟合,以及使模型更加鲁棒,本方法中是对数据进行颜色、尺度维度随机的数据增强处理。
6.根据权利要求2所述的基于人工智能的气管插管关键结构识别模型的构建方法,其特征在于:所述步骤s4中使用yolov5m框架及预训练模型,以yolov5使用cspdarknet作为主干网络,以及fpn和panet进行多尺度特征融合,能够较好地兼顾精度与性能表现,预训练模型已经在大规模数据集上进行了训练,并且学习到了丰富的特征表示,且yolov5网络的损失函数包括检测框损失、置信度误差损失和分类误差损失。
7.根据权利要求2所述的基于人工智能的气管插管关键结构识别模型的构建方法,其特征在于:所述步骤s5中需逐一对视频不同帧进行目标检测,产生对目标的预测信息,当超过设置的置信度阈值则表示检测到目标,但由于摄像头晃动,异物干扰,光照因素影响,视频检测会存在检测框闪烁的问题,而基于检测目标在时序上应该是稳定出现的,本方法将前若干帧超过一定阈值的预测值与本帧检测出的预测值累加,使检测模型获得记忆能力,提高检测的稳定性,同时考虑气管插管场景中会厌软骨及声门结构的先后逻辑顺序,将历史帧累积的声门预测概率使用一定权重去抑制会厌软骨的预测概率,即对于不符合前后关系的置信度进行抑制,从而进一步减少误判情况。
技术总结
本发明提供基于人工智能的气管插管关键结构识别模型系统及构建方法,涉及人工智能医疗急救技术领域。该基于人工智能的气管插管关键结构识别模型系统及构建方法,包括基于对抗生成模型的图像数据扩充、数据标注和预处理以及基于YOLOv5的多类目标检测算法。本发明能够对可视喉镜气管插管过程中拍摄的视频数据进行时序检测优化,降低画面干扰或某些罕见图像形态的影响,并遵循实际检测前后逻辑,提高了检测稳定性和准确率;能够将模型部署到云平台通过手机端运行形成气管插管辅助决策系统,从而使得本发明在气管插管过程中,能够提供准确的声门结构识别和关键特征定位,能够帮助现场早期施救者及时决策,特别是非医学专业人员,如消防、武警、保安等群众,能够快速施救,准确地经声门置入气管,提高急救通气成功率,减少病人的不适与损伤,对于提高气管插管的准确性和安全性具有重要意义。
技术研发人员:邓思懿,孙欣,叶方全,张勇
受保护的技术使用者:重庆南鹏人工智能科技研究院有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!