一种基于数据聚类算法的海量AIS定位数据索引生成方法与流程
本发明属于智慧海洋应用,更为具体地讲,涉及在不同业务领域对ais数据分类标准和索引需求不同情景下一种基于数据聚类算法的海量ais定位数据索引生成方法。
背景技术:
1、随着海洋事业的快速发展,ais数据的数量和质量得到了很大提升,这也奠定了ais数据辅助建设智慧海洋事业的基础。但是每年数百亿乃至千亿级别数量的ais数据也为相应数据的管理、存储、索引提出了新的问题。传统数据索引构建方法有三类:1、第一类为不考虑时空特性,直接按照特定顺序,例如传入时间、船名、数据获取方式等,赋予ais数据索引信息的非时空索引构建,该方法构建的数据在分析过程中检索复杂;2、第二类不考虑数据的空间特性,以录入时间为基础,结合数据属性,赋予ais数据索引信息,构建数据的时间索引,该方法形成的索引信息不能表达数据在空间分布上的特点,难以用于空间分析和地理分析;3、第三类综合考量数据的时空特性,结合数据属性,空间上以地理网格划分等方式赋予ais数据索引信息,该方法是现在常用的时空索引构建方法,但是该方法由于部分ais轨迹数据常常跨越多个地理网格难以形成统一清晰的划分标准。以上三类方法,均没有考量长短不一的ais数据轨迹引发的空间层面划分困难的问题,也没有考量ais数据中轨迹间相似性和数据区域覆盖性对数据索引构建的影响,这就导致在数据挖掘、数据分析、数据应用过程中,按照传统方法构建索引检索出的数据空间相似性不足,完成模式识别、轨迹匹配、模型训练、轨迹预测等工作时需要大量检索,降低应用执行效率。
技术实现思路
1、本发明的目的在于克服当前海量ais数据索引构建过程中空间相似性考虑不足的问题,提出了一种基于数据聚类算法的海量ais定位数据索引生成方法,实现了在ais数据索引构建过程中对数据空间相似性的深入考量,特别是在ais轨迹数据索引构建过程中综合考量了轨迹区域覆盖相似性和轨迹形态相似性,相比传统方法提升了索引信息在数据挖掘、数据分析、数据应用过程中的可用性。
2、本采用的技术方案为:
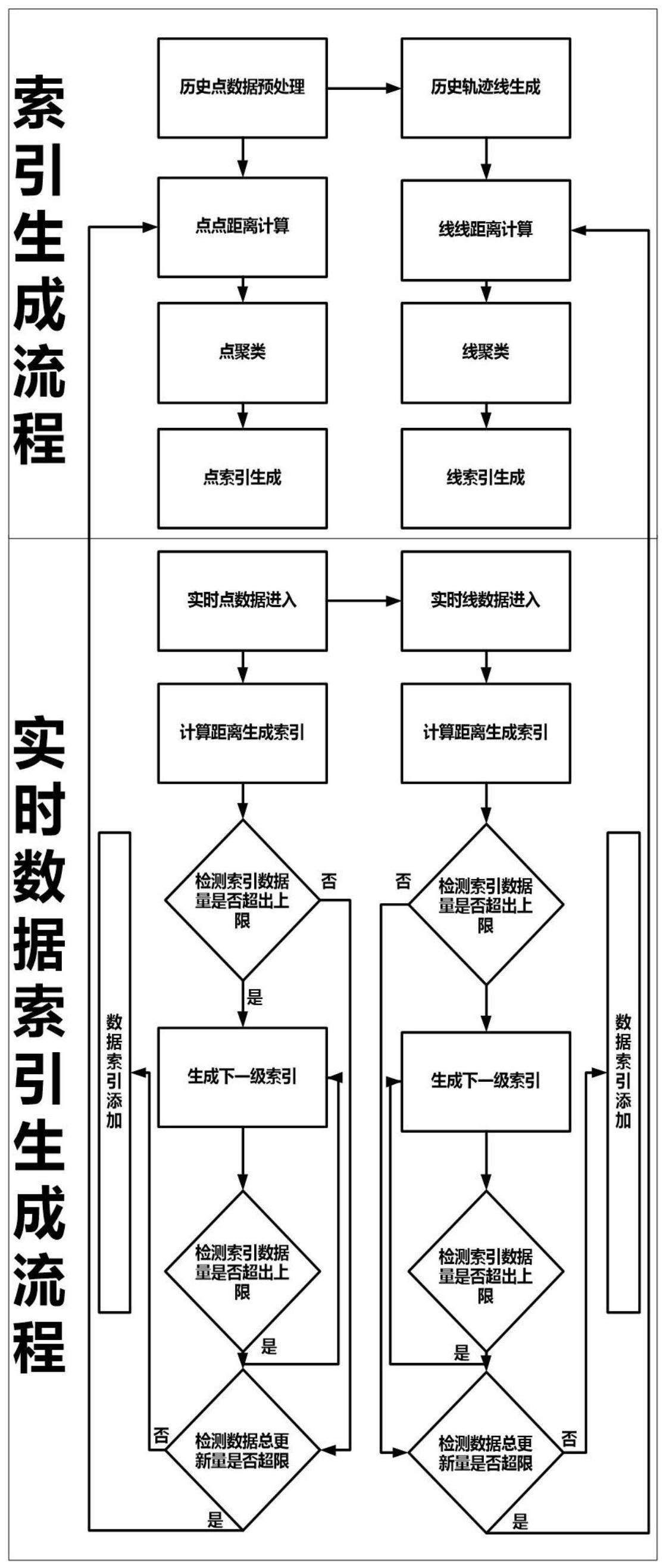
3、一种基于数据聚类算法的海量ais定位数据索引生成方法,包括以下步骤:
4、(1)对输入的ais数据中空、错和歧义值进行处理,生成轨迹点数据;
5、(2)将不同轨迹点数据按照船名进行分类,并按照时间排序切分后生成轨迹片段,生成轨迹线数据;
6、(3)按照欧式距离采用k-means聚类方法对轨迹点数据进行聚类,其中聚簇个数的值设置为轨迹点索引数量kp,提取出的簇中心做为点索引;同时按照线与线之间的距离采用k-means聚类方法对轨迹线数据进行聚类,其中聚簇个数的值设置为轨迹线索引数量kl,识别出簇后以簇中心做为轨迹索引;其中,轨迹点索引数量kp人为设定,确定了轨迹点索引的个数;轨迹线索引数量kl人为设定,确定了轨迹线索引的个数;
7、(4)如果新添加的轨迹点数据量超过索引更新阈值maxrp,则返回步骤(2)对全局索引进行更新,否则执行步骤(5);如果新添加轨迹线数量超过索引更新阈值maxrl,则将新添加轨迹线数量以轨迹点形式存储,返回步骤(2)对全局索引进行更新,否则执行步骤(5);其中,点索引更新阈值maxrp人为设定,确定了新加入点数据占已有点数据的比值超过maxrp时,开始重新构建全局点索引;线索引更新阈值maxrl人为设定,确定了在上一次全局线索引更新后,新加入线数据轨迹运动特征变化窗口数量占上一次全局线索引构建时已有线数据轨迹运动特征变化窗口数量的比值超过maxrl时,开始重新构建全局线索引;
8、(5)计算新添加的轨迹点数据与不同点索引间最短距离,生成索引标签;判断新添加的轨迹线数据是否与相应船舶现有轨迹线相连,如果相连,则加入已有轨迹片段,如果不相连,则计算新轨迹线数据与不同轨迹索引间最短距离,生成索引标签;
9、(6)新数据生成索引标签后,检测相应标签下数据总数量是否对应超过轨迹点上限maxp或者轨迹线上限maxl;如果超过,则检测是否有下一级别索引,有则计算最短距离生成索引,没有则返回步骤(3)计算生成相应标签下数据的下一级别索引;其中,轨迹点上限maxp人为设定,确定了每个点索引可以指向的点数据数量,当某个点索引中点数量超过上限时,对当前索引下点数据构建下一级别点索引;轨迹线上限maxl人为设定,确定了每个线索引可以指向的线数据数量,当某个线索引中点数量超过上限时,对当前索引下线数据构建下一级别线索引。
10、进一步的,步骤(1)中空、错和歧义值处理包括如下步骤:
11、(101)按照正则化表达约束的方式,对文本类型的属性构建映射表,统一映射为中文,并对相同表达方式的内容,采用正则化式对相似内容进行歧义消除;
12、(102)歧义值处理后,对速度和方向属性的错值进行处理;
13、其中,错值判定方法为:当前点与前点和后点任一速度或方向差,超过v或t,且前点或后点与当前点时间间隔不超过tl,则判定为错值;其中速度特征改变比值v人为设定,确定了当下一点运动速度和当前点速度差值与当前点速度的比值超过v时认为当前点为运动特征发生变化点;方向特征改变比值t人为设定,确定了当下一点航向和当前点航向差值与当前点航向的比值超过t时认为当前点为运动特征发生变化点;轨迹线划分阈值tl人为设定,确定了同船名轨迹点按照时间排序后相邻两点间间隔时间超过tl认为此处是轨迹片段的断点;
14、错值处理的方法为:前点和后点与当前点时间间隔均不超过轨迹线划分阈值t时,取前点和后点相应属性平均值做为当前点属性数据填充;前点和后点只有一个与当前点时间间隔不超过轨迹线划分阈值tl时,取不超过时间间隔点的相应属性做为当前点属性数据填充;
15、(103)点数据的空值处理,以当前待处理点数据前后合计为w个的点所对应属性值为依据进行处理;其中值为非数值类型时,取出现最多的值进行填充;值为数据类型时,取均值进行填充;同船舶在当前点前后轨迹点数量均达到w/2时取当前轨迹段前后各w/2的点进行处理;同船舶在当前点之前轨迹点数量不足w/2时向后取不足的量进行补充;同船舶在当前点之后轨迹点数量不足w/2时向后前不足的量进行补充;同船舶在当前点前后轨迹点数量均不足w/2时取当前轨迹段全部点进行处理;其中线运动特征检测窗口大小w的确定由人为设定,确定了轨迹线运动特征发生变化认定时最小窗口的大小,即连续w个点为运动特征发生变化点即认为此处为一个轨迹运动特征变化窗口,与一个窗口连续的运动特征发生变化点也归入相应窗口,即连续的一段超过w个运动特征发生变化点的轨迹称为一个轨迹运动特征变化窗口,一个轨迹运动特征变化窗口内所有点的平均坐标值构成的点称为轨迹运动特征变化中心点。
16、进一步的,步骤(2)中按照时间排序切分后生成轨迹片段,具体为:如果相邻两点间间隔时间超过迹线划分阈值t,则这两点分别是轨迹片段的端点。
17、进一步的,步骤(3)中线与线之间距离的计算,具体过程为:
18、线与线间距离计算采用权重为均衡阈值x的覆盖区域距离和权重为(1-x)的frechet距离的加权和,距离均衡表达了在轨迹线数据间距离度量时轨迹间最短距离和形态相似性;其中,覆盖区域距离是通过计算两轨迹线间所有轨迹运动特征变化中心点间最大欧式距离做为线段间距离;均衡阈值x为0到1的浮点数,确定了线聚类过程中计算线与线距离时,线与线之间覆盖区域距离和frechet距离在最终距离中所占比重,为人为设定。
19、本发明与背景技术相比具有如下优点:
20、(1)本发明提出了一种全新的ais数据索引构建方法,可以很好的将数据的空间信息融入到索引构建过程中,避免了之前方法由于轨迹线过长导致的难以被特定空间网格包含的问题。
21、(2)本发明在索引构建构建过程中很好的兼顾数据间空间相似性,相同索引下的数据在空间上具有更高的相似性,特别是轨迹数据,综合考虑了轨迹间形态相似性和区域覆盖的相似性,可以更好的满足数据挖掘、数据分析、数据应用过程中模式识别、轨迹匹配、模型训练、轨迹预测等算法和应用的数据管理需求。
- 还没有人留言评论。精彩留言会获得点赞!