一种视频动作识别的方法及设备与流程
本技术涉及计算机,尤其涉及一种视频动作识别的方法及设备。
背景技术:
1、随着计算机技术的不断发展,基于人体关键点的动作识别在人机交互、运动分析、智能监控等领域有着广泛的应用。目前,对于视频中动作的检测,大多需要多分支处理三维数据,对数据的处理并不简单。通用的动作检测方式:
2、1)逐帧预测的检测方式:使用深度学习卷积算法将视频以图片帧的形式和光流图的形式分别输入不同的rpn网络提取候选框,再将候选框分别输入如fast rcnn等检测网络得到不同的特征,通过后融合方式融合特征并用动态规划算法得到动作在视频中的路径和时间定位结果。
3、该方式的缺点是:将视频帧视为独立的图片,所以目标检测模型也是独立地使用在不同的视频帧中,在这个过程中模型学习不到时序信息;而且由于时空信息和时序信息被分开训练,导致这两种信息没有办法很好地互相促进彼此的效果。
4、2)借鉴目标检测思路的动作管道检测方式:通过3d卷积串联完成视频片段的特征提取,对于目标检测的候选框做3d延伸,生成对于一段视频的候选动作管道,根据管道内的特征进行动作标签预测。
5、该方式的缺点是:候选框生成算法的输出内容会根据视频片段的长度增加而大幅增加,由于不能端到端学习所以模型并不能找到全局最优,导致该模型对短期和轻微位移动作有效,但对于有大幅度位移的动作效果不好。
6、3)运用attention的动作管道检测方式:使用3d和2d分支提取时序特征和空间特征,再采用attention对两个分支提取的特征进行融合,得到特征之间的关系并用动态规划算法得到动作在视频中的路径和时间定位结果。
7、该方式的缺点是:虽然实现了端到端训练,但是两种分支的结构相较于单分支结构花费了两倍的算力,并不能带来很大的准确率的提升,性价比低。
技术实现思路
1、本技术的一个目的是提供一种视频动作识别的方法及设备,解决现有技术中需要多分支处理三维数据并且需要生成锚点或候选框的问题。
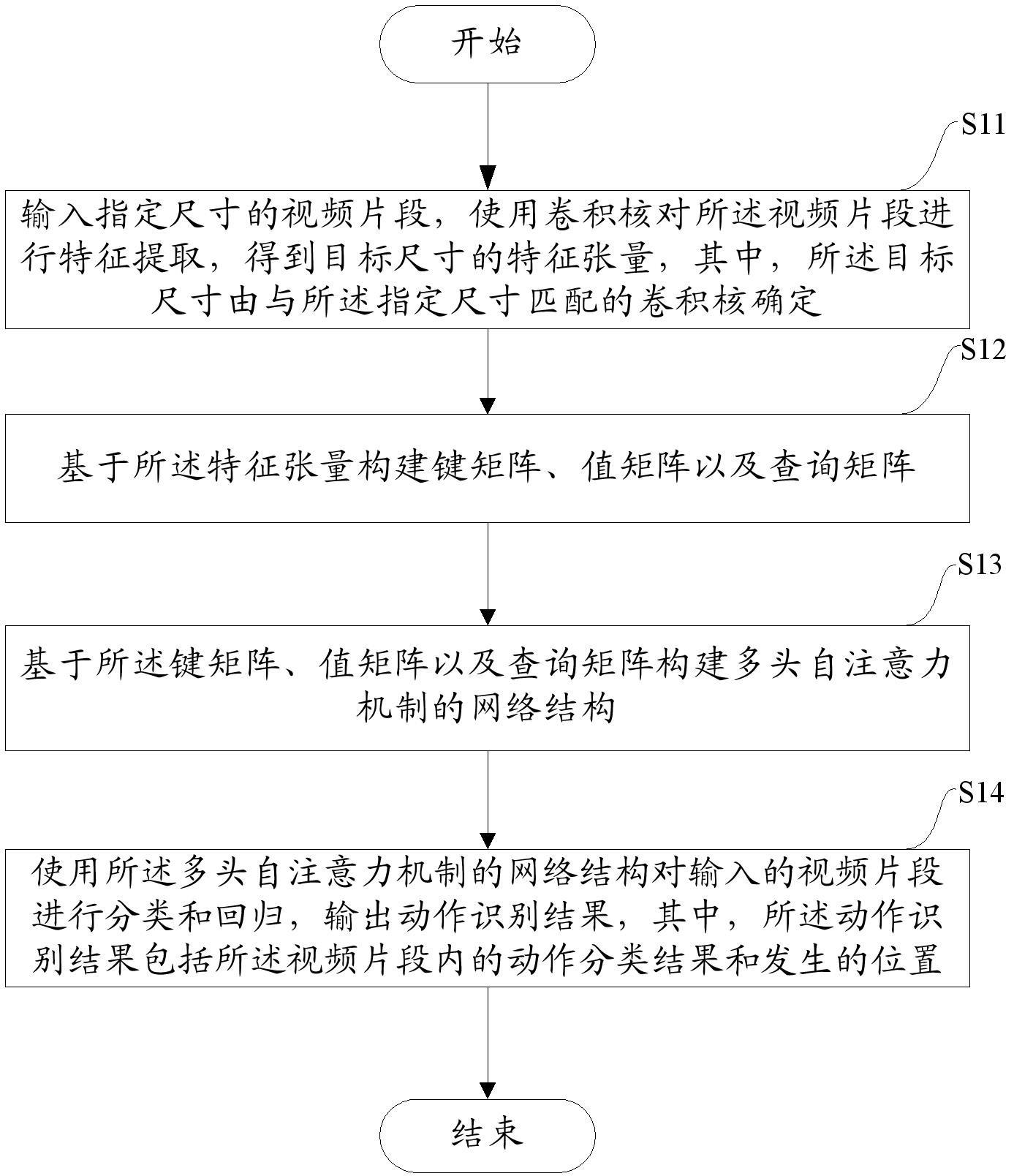
2、根据本技术的一个方面,提供了一种视频动作识别的方法,该方法包括:
3、输入指定尺寸的视频片段,使用卷积核对所述视频片段进行特征提取,得到目标尺寸的特征张量,其中,所述目标尺寸由与所述指定尺寸匹配的卷积核确定;
4、基于所述特征张量构建键矩阵、值矩阵以及查询矩阵;
5、基于所述键矩阵、值矩阵以及查询矩阵构建多头自注意力机制的网络结构;
6、使用所述多头自注意力机制的网络结构对输入的视频片段进行分类和回归,输出动作识别结果,其中,所述动作识别结果包括所述视频片段内的动作分类结果和发生的位置。
7、可选地,使用卷积核对所述视频片段进行特征提取,得到目标尺寸的特征张量,包括:
8、对所述视频片段进行时间方向上的采样;
9、使用与所述指定尺寸匹配的卷积核对采样后的视频片段进行卷积运算,得到特征图像;
10、按照特征图像的特征长度对所述特征图像进行二维转换,得到目标尺寸的特征张量,其中,所述目标尺寸由序列长度和特征长度确定。
11、可选地,基于所述键矩阵、值矩阵以及查询矩阵构建多头自注意力机制的网络结构,包括:
12、基于所述键矩阵、值矩阵以及查询矩阵确定目标尺寸的特征表征;
13、对所述特征表征进行编码操作,得到编码后的张量;
14、对编码后的张量进行解码操作,得到解码后的张量;
15、基于所述解码后的张量构建多头自注意力机制的网络结构的分类分支和回归分支。
16、可选地,基于所述键矩阵、值矩阵以及查询矩阵确定目标尺寸的特征表征,包括:
17、根据所述键矩阵和查询矩阵确定注意力分布矩阵;
18、将所述注意力分布矩阵与所述值矩阵相乘得到输出张量,按照所述目标尺寸对所述输出张量进行变换尺寸,得到变换后的张量;
19、对所述变换后的张量使用全连接层以及非线性激活函数提取目标尺寸的特征表征。
20、可选地,对所述特征表征进行编码操作,得到编码后的张量,包括:
21、步骤1,根据所述特征表征确定键张量、查询张量以及值张量;
22、步骤2,将位置编码加在所述键张量及查询张量上,并将加位置编码后的键张量以及加位置编码后的查询张量以及值张量输入多头自注意力机制模块和全连接层中计算输出张量;
23、按照指定次数重复步骤1和步骤2,得到编码后的张量。
24、可选地,对编码后的张量进行解码操作,得到解码后的张量,包括:
25、初始化所述视频片段对应的目标张量,其中,所述目标张量的形状由所述视频片段的特征长度以及所述视频片段内包含的动作数量确定;
26、基于初始化后的目标张量的值以及编码后的张量确定第一输出张量的值;
27、基于所述第一输出张量的值确定解码后的张量。
28、可选地,基于初始化后的目标张量的值以及编码后的张量确定第一输出张量的值,包括:
29、根据初始化后的目标张量的值初始化目标键张量、目标值张量以及目标查询张量;
30、将位置编码加在初始化后的目标键张量和目标查询张量上,将初始化后的目标值张量、加位置编码后的目标键张量以及加位置编码后的目标查询张量输入到多头自注意力机制模块中计算自注意力机制,输出的张量与所述目标张量计算残差;
31、将所述残差作为第一查询张量,将编码后的张量作为第一值张量和第一键张量;
32、将位置编码加在所述第一键张量和第一查询张量上,将所述第一值张量、加位置编码后的第一键张量以及加位置编码后的第一查询张量输入到多头自注意力机制模块以及全连接层中,得到第一输出张量的值。
33、可选地,基于所述第一输出张量的值确定解码后的张量,包括:
34、步骤a,根据所述第一输出张量的值初始化目标键张量、目标值张量以及目标查询张量;
35、步骤b,将位置编码加在初始化后的目标键张量和目标查询张量上,将初始化后的目标值张量、加位置编码后的目标键张量以及加位置编码后的目标查询张量输入到多头自注意力机制模块中计算自注意力机制,输出的张量与所述目标张量计算残差;
36、步骤c,将所述残差作为第二查询张量,将编码后的张量作为第二值张量和第二键张量;
37、步骤d,将位置编码加在所述第二键张量和第二查询张量上,将所述第二值张量、加位置编码后的第二键张量以及加位置编码后的第二查询张量输入到多头自注意力机制模块以及全连接层中,得到第二输出张量的值;
38、重复上述步骤a至d的过程,重复指定次数,输出解码后的张量。
39、可选地,所述方法包括:
40、将初始化后的目标张量作为输入矩阵输入至解码器中,将所述输入矩阵复制成三份,分别作为目标键张量、目标值张量以及目标查询张量。
41、可选地,基于所述解码后的张量构建多头自注意力机制的网络结构的分类分支和回归分支,包括:
42、将所述解码后的张量输入全连接层,得到第一尺寸的特征;
43、对所述第一尺寸的特征输入全连接层和非线性relu层,得到分类分支的输出;
44、将解码后的张量输入全连接层和非线性relu层,得到新的第一尺寸的特征;
45、将所述新的第一尺寸的特征输入全连接层和非线性relu层,得到第二尺寸的特征;
46、将所述第二尺寸的特征输入全连接层和非线性sigmoid层,作为回归分支的输出。
47、根据本技术另一个方面,还提供一种视频动作识别的设备,该设备包括:
48、一个或多个处理器;以及
49、存储有计算机可读指令的存储器,所述计算机可读指令在被执行时使所述处理器执行如前述所述方法的操作。
50、根据本技术再一个方面,还提供了一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现如前述所述的方法。
51、与现有技术相比,本技术通过输入指定尺寸的视频片段,使用卷积核对所述视频片段进行特征提取,得到目标尺寸的特征张量,其中,所述目标尺寸由与所述指定尺寸匹配的卷积核确定;基于所述特征张量构建键矩阵、值矩阵以及查询矩阵;基于所述键矩阵、值矩阵以及查询矩阵构建多头自注意力机制的网络结构;使用所述多头自注意力机制的网络结构对输入的视频片段进行分类和回归,输出动作识别结果,其中,所述动作识别结果包括所述视频片段内的动作分类结果和发生的位置。从而将视频分成定长的管道,利用自注意力机制学习视频内帧和帧之间的时序信息和空间信息,完成分类和回归任务。相比于传统模型,该方法具有以下两个优势:可以利用自注意力机制学习帧和帧之间的关系,并不需要三维模型也不需要多分支结构去处理三维数据,就可以达到同样甚至更高的精度。另外,能够省去了生成候选通道或者候选锚点的步骤,使得模型可以处理更长时间的数据。
- 还没有人留言评论。精彩留言会获得点赞!