一种故障诊断模型训练方法及装置与流程
本技术涉及故障诊断,更具体地,涉及一种故障诊断模型训练方法及装置。
背景技术:
1、轴承作为机械传动的关键零件,被广泛应用于各种机械设备中,其健康状况对于机械设备的安全性与稳定性具有重要影响。然而设备在高速、重载等恶劣环境下长期工作时,轴承将会不可避免地发生退化,产生裂纹、磨损等。一旦发生故障将直接影响整个设备的正常运行,轻则给企业造成经济损失,重则引发事故,威胁生命安全。因此,为保证机械设备的正常运行,对轴承的健康状况进行监测以及时排除安全隐患具有重大的工程意义。
2、目前,对于滚动轴承的故障诊断方法主要分为基于解析模型和基于数据驱动两方面。基于解析模型的方法需要对故障诊断问题进行解析化表达,对于复杂度较高的系统建模难度大,且建立的模型在其他系统上的普适性较低,实际推广使用具有一定局限性。而基于数据驱动的故障诊断方法因其特征提取能力不足,难以挖掘提取故障数据中更深层次的微小特征,从而限制了诊断准确率的提升。
3、随着互联网、物联网等快速兴起与普及,当前社会数据的增长速度比以往任何时期都要迅猛。大数据给深度神经网络提供了充足的训练“原料”,给基于数据驱动的机械智能故障诊断的深入研究和应用提供了新的机遇,当前基于深度学习的故障诊断方法因能有效对故障信息进行表征而被广泛应用于故障诊断领域。但在实际工业活动中,工作人员在缺乏专业知识情况下易赋予故障模式错误的标签分类。因而在真实的工业数据集中,标注错误(即标签噪声)问题是不可避免的。
4、然而,当前大多数基于数据驱动的故障诊断方法过于依赖标注完备的数据集,当存在标签噪声时,模型会因过拟合于噪声标签数据而导致模型特征表达能力不足,影响诊断精度。
技术实现思路
1、本技术提供一种故障诊断模型训练方法及装置,通过引入基于特征编码向量表示的注意力权重实现动态划分样本,以对损失函数进行正则化,对于标签噪声样本具有较高诊断鲁棒性,减少标签噪声样本引起的梯度表示,避免模型过拟合于噪声标签数据,提高模型特征的表达能力和诊断精度。
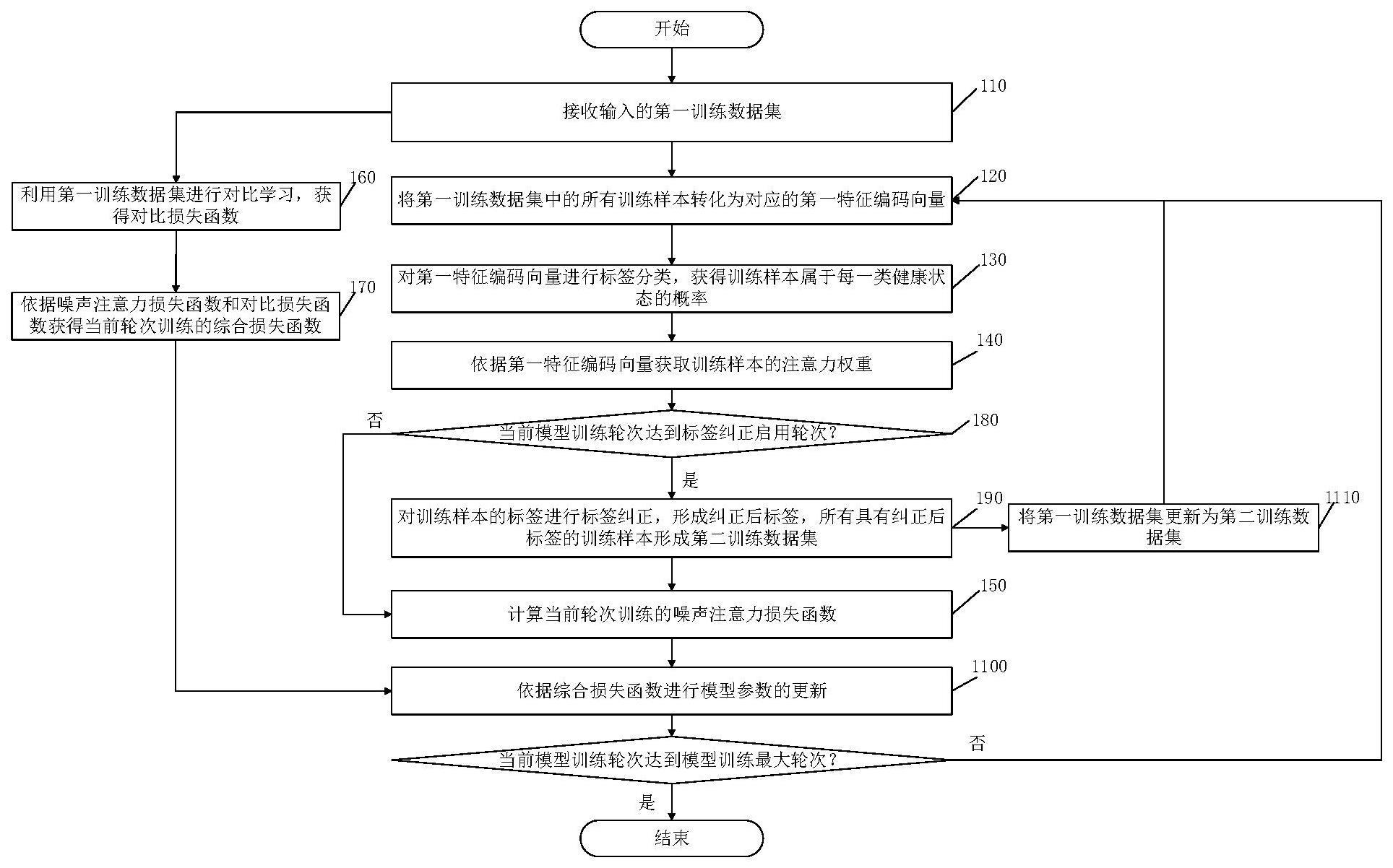
2、本技术提供了一种故障诊断模型训练方法,包括:
3、接收输入的第一训练数据集,第一训练数据集中的所有训练样本均具有标签,其中一部分训练样本具有正确标签,另一部分训练样本具有错误标签;
4、循环执行如下步骤,直到当前模型训练轮次达到模型训练最大轮次:
5、将第一训练数据集中的所有训练样本转化为对应的第一特征编码向量;
6、对第一特征编码向量进行标签分类,获得训练样本属于每一类健康状态的概率;
7、依据第一特征编码向量获取训练样本的注意力权重;
8、依据所有训练样本的概率、注意力权重以及训练样本的标签计算当前轮次训练的噪声注意力损失函数;
9、依据噪声注意力损失函数进行模型参数的更新。
10、优选地,故障诊断模型训练方法还包括:利用第一训练数据集进行对比学习,获得对比损失函数;
11、依据噪声注意力损失函数和对比损失函数获得当前轮次训练的综合损失函数;
12、并且,
13、依据综合损失函数进行模型参数的更新。
14、优选地,利用第一训练数据集进行对比学习,获得对比损失函数,具体包括:
15、对第一训练数据集中的训练样本进行两种不同的数据增强,形成数据增强样本集;
16、对数据增强样本集内的任意两个数据增强样本组成的样本对进行对比学习,以获得对比损失函数。
17、优选地,对数据增强样本集内的任意两个数据增强样本组成的样本对进行对比学习,获得对比损失函数,具体包括:
18、对于任意样本对,首先,将样本对中的两个数据增强样本分别转化为第一特征编码向量和第二特征编码向量;然后,分别将第一特征编码向量和第二特征编码向量映射为空间表示向量;最后计算两个空间表示向量之间的相似度;
19、利用所有样本对的相似度计算样本间互信息,依据所有样本间互信息计算对比损失函数。
20、优选地,计算噪声注意力损失函数之前,还包括:
21、判断当前模型训练轮次是否达到标签纠正启用轮次,标签纠正启用轮次小于模型训练最大轮次;
22、若是,则对标签进行标签纠正,形成纠正后标签,所有具有纠正后标签的训练样本形成第二训练数据集;
23、依据所有训练样本的概率、注意力权重以及与训练样本对应的纠正后标签计算当前轮次训练的噪声注意力损失函数;
24、并且,将第一训练数据集更新为第二训练数据集,利用第二训练数据集进行后续轮次的训练。
25、本技术还提供一种故障诊断模型训练装置,包括训练数据接收模块、第一转化模块、分类模块、权重获得模块、第一损失函数计算模块以及参数更新模块;
26、训练数据接收模块用于接收输入的第一训练数据集,第一训练数据集中的所有训练样本均具有标签,其中一部分训练样本具有正确标签,另一部分训练样本具有错误标签;
27、第一转化模块用于将第一训练数据集中的所有训练样本转化为对应的第一特征编码向量;
28、分类模块用于对第一特征编码向量进行标签分类,获得训练样本属于每一类健康状态的概率;
29、权重获得模块用于依据第一特征编码向量获取训练样本的注意力权重;
30、第一损失函数计算模块用于依据所有训练样本的概率、注意力权重以及训练样本的标签计算当前轮次训练的噪声注意力损失函数;
31、参数更新模块用于依据噪声注意力损失函数进行模型参数的更新。
32、优选地,故障诊断模型训练装置还包括对比学习模块和第二损失函数计算模块;
33、对比学习模块用于利用第一训练数据集进行对比学习,获得对比损失函数;
34、第二损失函数计算模块用于依据噪声注意力损失函数和对比损失函数获得当前轮次训练的综合损失函数;
35、并且,参数更新模块用于依据综合损失函数进行模型参数的更新。
36、优选地,对比学习模块包括数据增强模块和样本对对比学习模块;
37、数据增强模块用于对第一训练数据集中的所有训练样本进行两种不同的数据增强,形成数据增强样本集;
38、样本对对比学习模块用于对数据增强样本集内的任意两个数据增强样本进行对比学习,以获得对比损失函数。
39、优选地,样本对对比学习模块包括第二转化模块、映射模块、相似度计算模块以及对比损失函数计算模块;
40、第二转化模块用于将样本对中的两个数据增强样本分别转化为第一特征编码向量和第二特征编码向量;
41、映射模块用于分别将第一特征编码向量和第二特征编码向量映射为空间表示向量;
42、相似度计算模块用于计算两个空间表示向量之间的相似度;
43、对比损失函数计算模块用于利用所有样本对的相似度计算样本间互信息,依据所有样本间互信息计算对比损失函数。
44、优选地,故障诊断模型训练装置还包括判断模块、标签纠正模块以及数据集更新模块;
45、判断模块用于判断当前模型训练轮次是否达到标签纠正启用轮次;
46、标签纠正模块用于在当前模型训练轮次达到标签纠正启用轮次时,对标签进行标签纠正,形成纠正后标签,所有具有纠正后标签的训练样本形成第二训练数据集;
47、数据集更新模块用于将第一训练数据集更新为第二训练数据集,利用第二训练数据集进行后续轮次的训练;
48、第一损失函数计算模块用于依据所有训练样本的概率、注意力权重以及与训练样本对应的纠正后标签计算当前轮次训练的噪声注意力损失函数。
49、通过以下参照附图对本技术的示例性实施例的详细描述,本技术的其它特征及其优点将会变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!