一种企业产品词异常的处理方法、装置及电子设备与流程
本技术涉及数据处理的,具体涉及一种企业产品词异常的处理方法、装置及电子设备。
背景技术:
1、随着人工智能的快速发展,对于人工智能的应用也越来越广泛。用户在查询企业时,往往会借助应用了人工智能的企业数据分类模型对企业信息中的产品词进行提取和分类,最后,将多个产品词中归类为企业主营业务的产品词呈现给用户,以帮助用户快速了解企业的产品。
2、目前,企业在编写企业信息时可能会存在编写错误的情况,从而导致企业产品词中存在异常词的情况,但企业信息中出现异常词为小概率事件,因此异常词的数量不会很多。然而,对于企业数据分类模型来说,在训练企业数据分类模型时,由于异常词组成的负样本数量较少,会导致用于训练企业数据分类模型的训练样本中正样本与负样本存在严重不均衡,从而造成企业数据分类模型对于异常词识别分类的准确率降低。
3、因此,亟需一种企业产品词异常的处理方法、装置及电子设备。
技术实现思路
1、针对用于训练企业数据分类模型的训练样本中正样本与负样本存在严重不均衡,从而造成企业数据分类模型对于异常词识别分类的准确率降低的问题。本技术提供了一种企业产品词异常的处理方法、装置及电子设备。
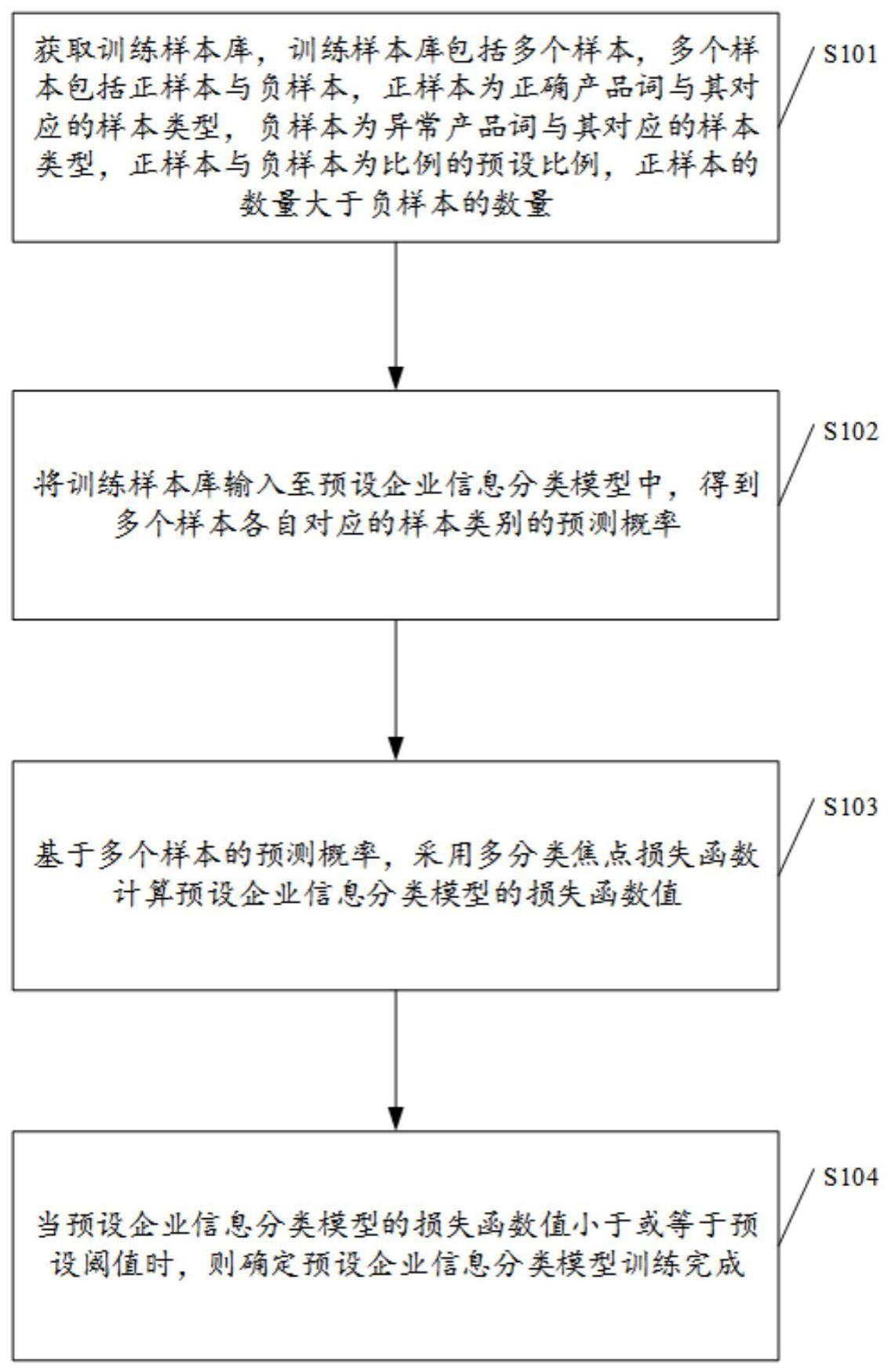
2、第一方面,本技术提供一种企业产品词异常的处理方法,应用于服务器,该方法包括:获取训练样本库,训练样本库包括多个样本,多个样本包括正样本与负样本,正样本为正确产品词与其对应的样本类型,负样本为异常产品词与其对应的样本类型,正样本与负样本的比例为预设比例,正样本的数量大于负样本的数量;将训练样本库输入至预设企业信息分类模型中,得到多个样本各自对应的样本类型的预测概率;基于多个样本的预测概率,采用多分类焦点损失函数计算预设企业信息分类模型的损失函数值;当预设企业信息分类模型的损失函数值小于或等于预设阈值时,则确定预设企业信息分类模型训练完成。
3、通过采用上述技术方案,通过调整训练样本库中正样本与负样本的比例,使正样本的数量大于负样本的数量。以此来模拟训练样本库中样本比例不均衡的问题。然后将训练样本库输入至预设企业信息分类模型中进行训练,再通过引入多分类焦点损失函数以对样本训练库中的正样本减少关注程度,即降低正样本的训练损失,对负样本增加关注程度,即增加负样本的训练损失,从而使得预设企业信息分类模型对于负样本增加更多的迭代次数,从而提升预设企业信息分类模型对异常产品词的识别准确率。
4、第二方面,本技术提供一种企业产品词异常的处理装置,装置为服务器,服务器包括获取模块与处理模块,其中:
5、获取模块,用于获取训练样本库,训练样本库包括多个样本,多个样本包括正样本与负样本,正样本为正确产品词与其对应的产品类型,负样本为异常产品词与其对应的样本类型,正样本与负样本的比例为预设比例,正样本的数量大于负样本的数量;
6、处理模块,用于将训练样本库输入至预设企业信息分类模型中,得到多个样本各自对应的样本类型的预测概率;基于多个样本的预测概率,采用多分类焦点损失函数计算预设企业信息分类模型的损失函数值;当预设企业信息分类模型的损失函数值小于或等于预设阈值时,则确定预设企业信息分类模型训练完成。
7、可选的,所述多分类焦点损失函数为:
8、
9、其中,fl为损失函数值;n为所述训练样本库中样本的总数量;m为样本类型的总数量;pic为第i个样本属于样本类型c的预测概率;yic为第i个样本属于样本类型c的真实标签,若属于样本类型c,则真实标签取1,否则取0;αc为样本类型c的权重值;γ为焦点因子。
10、通过采用上述技术方案,将每个样本的预测概率代入多焦点分类损失函数中进行计算,在这个过程中多分类焦点损失函数增加负样本的分类难度,降低正样本的分类难度,从而使得预设企业信息分类模型经过多次迭代训练后,更专注于学习难学习的负样本。
11、可选的,获取模块获取样本类型c对应的样本的总数量n,样本类型c为多个样本类型中任意一个;处理模型基于n与n的比值,确定样本类型c的权重值。
12、通过采用上述技术方案,根据样本的总数量n与训练样本库中样本的总数量n的比值,调整样本类型的权重,对于负样本增加权重,对于正样本减少权重,从而增加使得预设企业信息分类模型更专注于学习难学习的负样本,从而增加模型的对负样本的异常产品词的准确率。
13、可选的,预设企业信息分类模型包括多层transformer神经网络层,将训练样本库输入至预设企业信息分类模型之前,还包括:处理模块计算训练样本库中样本的总数量;将样本的总数量与预设模型训练库进行匹配,得到样本的总数量对应的transformer神经网络层的层数,预设模型训练数据库中包括样本数量与神经网路模型的对应关系。
14、通过采用上述技术方案,通过计算训练样本库中样本的总数量,以此确定企业信息分类模型需要学习的数据量;再将样本的总数量与预设模型训练库进行匹配,得到与企业信息分类模型需要学习的数据量的神经网络模型,通过参考该神经网络模型的transformer神经网络层的层数,从而确定企业信息分类模型的transformer神经网络层的层数,以此来降低模型难以收敛的概率。
15、可选的,将训练样本库输入至企业信息分类模型之前,还包括:处理模块对多个样本的句首与句尾均连接特征标记。
16、通过采用上述技术方案,通过在句首连接特征标注,用于标记序列的开始,在训练过程中,句首的特征标记可以帮助模型识别句子的语义,以加快模型的训练效率和准确率;在句尾连接特征标注,用于标记序列的结束,以便模型能够正确处理多个句子的输入。
17、可选的,确定预设企业信息分类模型训练完成之后,还包括:获取模块获取用户输入的企业检索词;处理模块基于企业检索词,从预设企业数据库中调用企业检索词对应的目标企业数据,预设企业数据库包括多个企业的企业数据;将目标企业数据输入至预设企业信息分类模型中,得到目标企业数据对应的多个产品词,多个产品词包括正确产品词与异常产品词;将目标企业数据对应的多个产品词向用户进行展示。
18、通过采用上述技术方案,借助于预设企业信息分类模型对异常产品词具有较高的识别度;因此,在对用户输入的企业搜索词,预设企业信息分类模型能够准确识别得到其对应的多个产品词中,其中,不仅包括正确产品词,还包括异常产品词;以此解决了户在查询企业主营业务的产品词时,呈现给用户的主营业务缺失部分产品词的信息的问题。
19、可选的,获取模块基于目标企业数据对应的多个正确产品词的产品类别,确定目标企业数据的主营产品类别;基于主营产品类别,从预设产品词数据库中调用主营产品类别对应的多个产品词,预设产品词数据库包括产品类别与产品词的对应关系;处理模块将目标企业数据对应的多个异常产品词逐一与主营产品类别对应的多个产品词进行匹配,确定多个异常产品词各自对应的正确产品词;将目标企业数据对应的多个异常产品替换为多个异常产品词各自对应的正确产品词。
20、通过采用上述技术方案,异常产品词往往出现缺字或错字的情况。因此,在向用户展示目标企业数据对应的多个产品词之前,通过对异常产品词进行纠正后,再将纠正后的异常产品词展示给用户,从而提升用户的阅读体验感。
21、第三方面,本技术提供一种电子设备,包括处理器、存储器、用户接口及网络接口,所述存储器用于存储指令,所述用户接口和网络接口用于给其他设备通信,所述处理器用于执行所述存储器中存储的指令,以使所述电子设备执行如第一方面中任意一项所述的方法。
22、第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质存储有指令,当所述指令被执行时,执行如第一方面中任意一项所述的方法。
23、综上所述,本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
24、1、通过调整训练样本库中正样本与负样本的比例,使正样本的数量大于负样本的数量。以此来模拟训练样本库中样本比例不均衡的问题。然后将训练样本库输入至预设企业信息分类模型中进行训练,再通过引入多分类焦点损失函数以对样本训练库中的正样本减少关注程度,即降低正样本的训练损失,对负样本增加关注程度,即增加负样本的训练损失,从而使得预设企业信息分类模型对于负样本增加更多的迭代次数,从而提升预设企业信息分类模型对异常产品词的识别准确率。
25、2、将每个样本的预测概率代入多焦点分类损失函数中进行计算,在这个过程中多分类焦点损失函数增加负样本的分类难度,降低正样本的分类难度,从而使得预设企业信息分类模型经过多次迭代训练后,更专注于学习难学习的负样本。
- 还没有人留言评论。精彩留言会获得点赞!