基于跨模态上下文序列转导的连续手语识别方法和装置
本发明涉及计算机视觉和自然语言处理交叉,尤其涉及一种基于跨模态上下文序列转导的连续手语识别方法和装置。
背景技术:
1、手语是利用手/手臂位置和身体姿势等信号来帮助全球听力障碍患者进行沟通交流,手语不仅为聋哑人士和听力障碍者提供了一种有效的沟通工具,使得他们能够交流和表达自己的想法和情感,手语还可以作为聋哑人士的基础教育,使他们能够获取知识、交流和参与社交活动。总的来说,手语是提高聋哑人士和听力障碍者的生活质量不可或缺的工具。
2、相关技术中,为了方便聋哑人士与正常人之间的交流,人们提出连续手语识别任务,旨在通过输入手语视频,将其识别为对应的gloss(手语中的最小语义单元)语言序列。因此,如何准确地识别手语视频对应的gloss语言序列是本领域技术人员亟须解决的技术问题。
技术实现思路
1、针对现有技术中的问题,本发明实施例提供一种基于跨模态上下文序列转导的连续手语识别方法和装置。
2、具体地,本发明实施例提供了以下技术方案:
3、第一方面,本发明实施例提供了一种基于跨模态上下文序列转导的连续手语识别方法,包括:
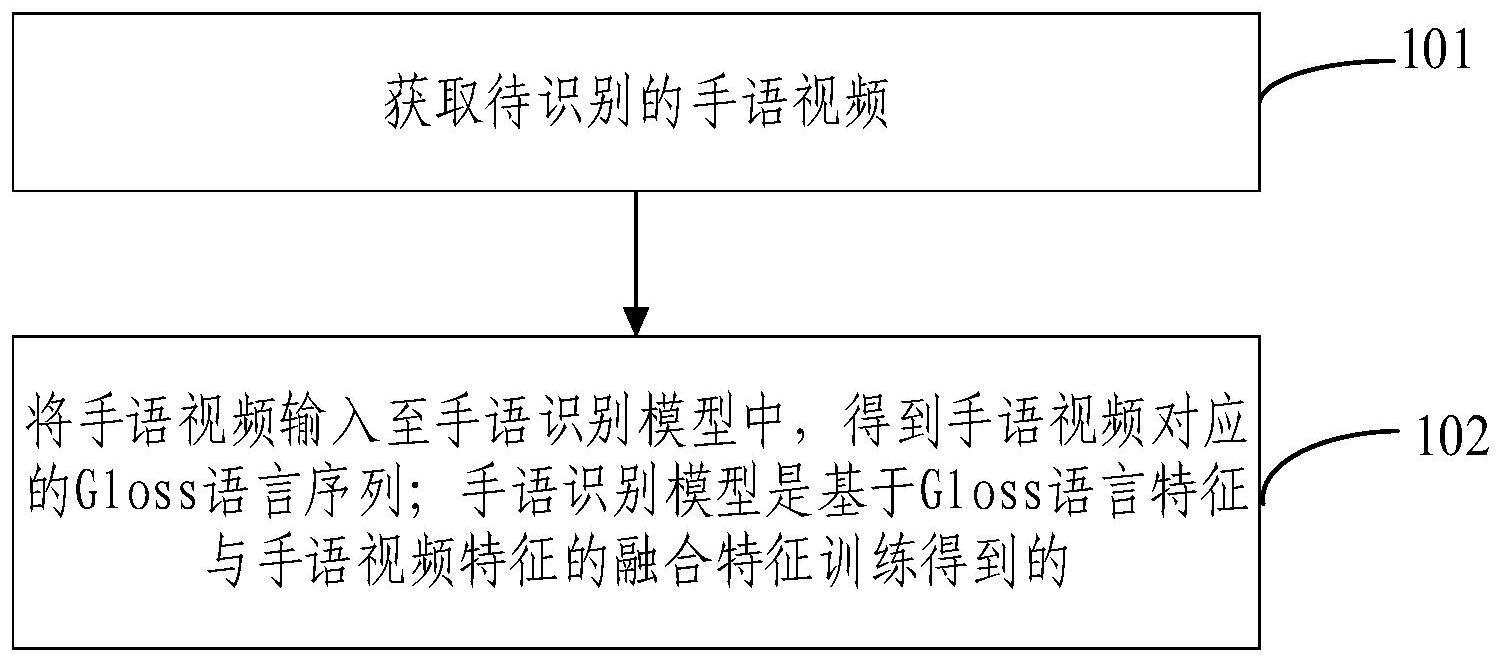
4、获取待识别的手语视频;
5、将手语视频输入至手语识别模型中,得到手语视频对应的gloss语言序列;手语识别模型是基于gloss语言特征与手语视频特征的融合特征训练得到的。
6、进一步地,手语识别模型,包括以下至少一项:
7、手语视频局部时序特征提取模块;手语视频局部时序特征提取模块用于将待识别的手语视频对应的视频帧中相邻n帧的语义进行聚合,生成多个手语视频局部时序特征;
8、手语视频全局时序特征提取模块;手语视频全局时序特征提取模块用于根据多个手语视频局部时序特征,得到手语视频全局时序特征;手语视频全局时序特征包括手语视频局部时序特征之间的时序关系;
9、gloss语言特征提取模块;gloss语言特征提取模块用于提取gloss语言特征;gloss语言特征包括gloss文本的上下文特征信息;
10、gloss语言特征与手语视频特征融合模块;gloss语言特征与手语视频特征融合模块用于将第s个手语视频全局时序特征和/或手语视频局部时序特征与第1个至第s-1个gloss语言特征进行融合,得到第s个融合特征;s为大于1的正整数;
11、解码模块;解码模块用于根据第1个至第s个融合特征,得到待识别的手语视频对应的gloss语言序列。
12、进一步地,解码模块用于:
13、根据第1个至第s个融合特征,得到融合特征在所有对齐路径中概率最大的对齐路径所对应的gloss语言序列;将gloss语言序列作为待识别的手语视频对应的gloss语言序列;对齐路径为基于动态规划算法所规划的融合特征至各个候选gloss语言序列的对齐路径。
14、进一步地,gloss语言特征与手语视频特征融合模块用于利用如下公式确定第s个gloss语言特征与手语视频特征的融合特征:
15、
16、其中,表示第s个融合特征;ls表示第s个手语视频全局时序特征或第s个手语视频局部时序特征;表示第1个至第s-1个gloss语言特征。
17、进一步地,手语识别模型是基于如下方式进行训练的:
18、将手语视频样本输入手语视频局部时序特征提取模块,得到手语视频样本对应的手语视频局部时序特征;
19、将手语视频样本输入手语视频全局时序特征提取模块,得到手语视频样本对应的手语视频全局时序特征;
20、将数据集样本中手语视频的标注信息输入至gloss语言特征提取层,得到gloss语言特征;
21、将gloss语言特征分别与手语视频样本对应的手语视频局部时序特征和手语视频全局时序特征进行融合,得到目标融合特征;
22、通过动态规划算法规划目标融合特征至各个候选gloss语言序列的对齐路径;确定目标融合特征至各个候选gloss语言序列的对齐路径的概率之和;
23、基于目标损失函数对手语识别模型训练,使得目标融合特征至各个候选gloss语言序列的对齐路径的概率之和达到预设条件。
24、进一步地,目标损失函数基于如下公式确定:
25、
26、其中,表示目标损失函数;p(z∣j)表示目标融合特征j转导为对齐路径z的条件依赖概率;stc(z,y)表示真实标注与对齐路径之间的编辑距离。
27、进一步地,利用如下公式确定目标融合特征j识别为gloss序列z的条件依赖的概率:
28、
29、其中,p(z∣j)表示目标融合特征j转导为对齐路径z的条件依赖概率;j表示目标融合特征;p(zs∣z<s,j)表示根据目标融合特征j和第1个至第s-1个gloss得到对齐路径z中第s个gloss的概率。
30、第二方面,本发明实施例还提供了一种基于跨模态上下文序列转导的连续手语识别装置,包括:
31、获取模块,用于获取待识别的手语视频;
32、识别模块,用于将手语视频输入至手语识别模型中,得到手语视频对应的gloss语言序列;手语识别模型是基于gloss语言特征与手语视频特征的融合特征训练得到的。
33、第三方面,本发明实施例还提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述基于跨模态上下文序列转导的连续手语识别方法。
34、第四方面,本发明实施例还提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述基于跨模态上下文序列转导的连续手语识别方法。
35、第五方面,本发明实施例还提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如第一方面所述基于跨模态上下文序列转导的连续手语识别方法。
36、本发明实施例提供的基于跨模态上下文序列转导的连续手语识别方法和装置,将gloss语言序列先验知识融合到视觉表示中,从而实现更好的手语语义建模,也就使得训练后的手语识别模型可以基于手语视频特征,可以更加准确高效地进行手语的识别,提升了手语识别的准确性。
技术特征:
1.一种基于跨模态上下文序列转导的连续手语识别方法,其特征在于,包括:
2.根据权利要求1所述的手语识别方法,其特征在于,所述手语识别模型,包括以下至少一项:
3.根据权利要求2所述的手语识别方法,其特征在于,所述解码模块用于:
4.根据权利要求3所述的手语识别方法,其特征在于,所述gloss语言特征与手语视频特征融合模块用于利用如下公式确定第s个gloss语言特征与手语视频特征的融合特征:
5.根据权利要求4所述的手语识别方法,其特征在于,所述手语识别模型是基于如下方式进行训练的:
6.根据权利要求5所述的手语识别方法,其特征在于,所述目标损失函数基于如下公式确定:
7.根据权利要求6所述的手语识别方法,其特征在于,利用如下公式建模目标融合特征j转导为对齐路径z的条件依赖概率:
8.一种基于跨模态上下文序列转导的连续手语识别装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述的基于跨模态上下文序列转导的连续手语识别方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如权利要求1至7任一项所述的基于跨模态上下文序列转导的连续手语识别方法。
技术总结
本发明提供一种基于跨模态上下文序列转导的连续手语识别方法和装置,该方法包括:获取待识别的手语视频;将手语视频输入至手语识别模型中,得到手语视频对应的Gloss语言序列;手语识别模型是基于Gloss语言特征与手语视频特征的融合特征训练得到的。本发明的方法将Gloss语言序列先验知识融合到视觉表示中,从而实现更好的手语语义建模,也就使得训练后的手语识别模型可以基于手语视频特征,可以更加准确高效地进行手语的识别,提升了手语识别的准确性。
技术研发人员:张怀文,郭子航,高嘉怿
受保护的技术使用者:内蒙古大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!