一种动画生成方法、装置、电子设备及存储介质
本公开涉及计算机,具体而言,涉及一种动画生成方法、装置、电子设备及存储介质。
背景技术:
1、随着视频行业的大力发展,越来越多的视频场景需要伴随有虚拟人脸出现在视频中,并同步视频中的言语而运动。人在说话时往往伴随有大量非言语行为,这些因言语活动而产生的非言语行为被称为副语言行为。这些行为动作包括手势、面部表情、头部运动(如点头和摇头)以及眨眼等。为了获得更加自然的人脸动画,这些副语言运动是不可或缺的。因此,需要将虚拟人脸的副语言运动与语音进行同步运动。
2、现有的过程式方法大多利用简易的噪声函数或重放视频的方式,生成的动画效果重复且不自然。另有,通过表演捕捉获得面部表情的动作,但动作的质量非常依赖于演员的能力。此外,大多数这类方法直接生成三维网格模型,动画师难以理解所用参数的含义,也难以修改生成的结果,因此难以与传统动画制作流程相结合。因此,如何基于语音同步驱动虚拟人脸进行更自然的副语言运动,成为视频动画领域需要解决的问题。
技术实现思路
1、本公开实施例提供一种动画生成方法、装置、电子设备及存储介质动画生成方法,该方法通过提取语音音频中的音频特征,驱动虚拟人的脸部进行同步运动,使得脸部副语言行为更加自然。
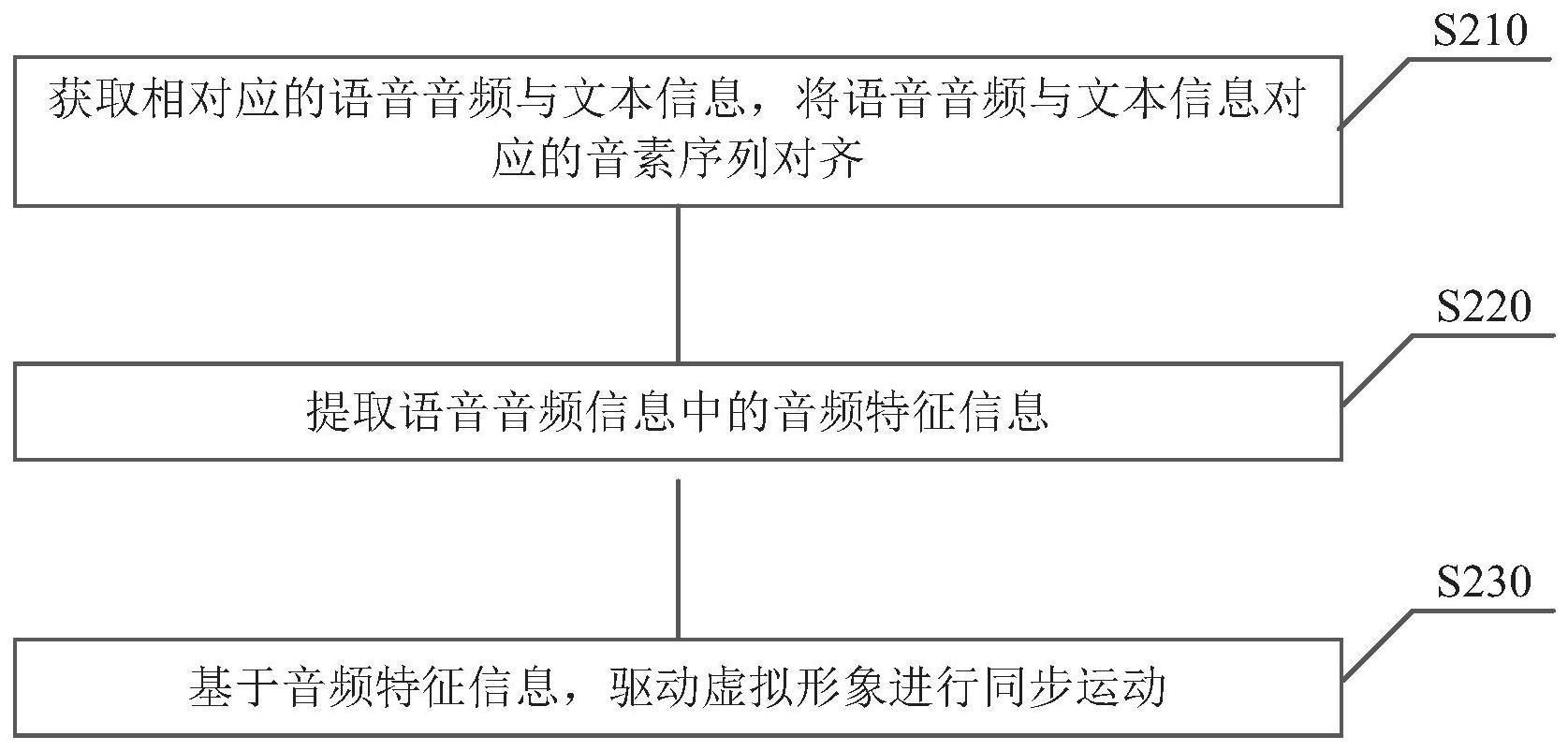
2、根据本公开实施例的第一方面,提供一种动画生成方法,包括:获取语音音频以及与所述语音音频对应的语音音频文本信息文本信息,将所述语音音频与所述文本信息对应的音素序列对齐;基于对齐后的所述音素序列对所述语音音频进行音频分析,提取所述语音音频中的音频特征信息;基于所述音频特征信息,驱动虚拟形象进行同步运动。。
3、在本公开的一些示例性实施例中,所述基于所述音素序列对所述语音音频进行音频分析,提取所述语音音频中的音频特征信息,包括:获取所述语音音频的声学参数;根据所述声学参数和所述对齐后的音素序列,确定所述语音音频中的至少一个音节核;对各个所述音节核的音高运动进行模式化处理,得到所述音节核的音高运动模式化曲线;基于音高运动阈值,根据所述音节核的音高运动模式化曲线,对所述音节核的音高运动进行标记,得到所述音节核对应的音高运动标识;所述音高运动阈值为对音高运动幅度大小进行衡量的阈值;将所述音节核的音高运动模式化曲线和所述音高运动标识作为所述音频特征信息。
4、在本公开的一些示例性实施例中,所述根据所述声学参数和所述对齐后的音素序列,确定所述语音音频中的至少一个音节核,包括:根据所述声学参数和所述对齐后的音素序列,确定元音对应的音量峰值;以所述元音对应的音量峰值为中心,确定所述音量峰值前后音量下降到预设音量阈值的范围内所对应的语音音频为所述音节核。
5、在本公开的一些示例性实施例中,所述对各个所述音节核的音高运动进行模式化处理,得到所述音节核的音高运动模式化曲线,包括:根据所述音节核的基频曲线,将所述音节核划分为至少一个时间段;当所述时间段所对应的基频曲线斜率大于滑音阈值时,确定所述时间段为滑音段;以所述时间段起止时间点对应的基频值之间的连线,为所述时间段对应的所述音高运动模式化曲线;当所述时间段所对应的基频曲线斜率不大于所述滑音阈值时,确定所述时间段为非滑音段;以所述时间段起止时间点之间的水平直线,为所述时间段对应的所述音高运动模式化曲线;将各个所述时间段对应的所述音高运动模式化曲线的组合作为所述音节核的音高运动模式化曲线。
6、在本公开的一些示例性实施例中,所述根据所述音节核的基频曲线,将所述音节核划分为至少一个时间段,包括:确定所述音节核中第一时间段的起止时间点;连接所述第一时间段起止时间点对应的基频值之间的第一时间段连线;所述第一时间段为所述音节核中任一已划分时间段;在所述第一时间段对应的基频曲线上,确定距离所述第一时间段连线最远的点为待定拐点;当所述待定拐点满足预设的拐点条件时,基于所述待定拐点将所述第一时间段划分为两个时间段;重复上述步骤,直至没有满足所述拐点条件的待定拐点。
7、在本公开的一些示例性实施例中,所述拐点条件包括以下至少一个条件:所述待定拐点与所述第一时间段连线的距离大于预设距离阈值;所述待定拐点与所述第一时间段的起止时间点的时间间隔大于预设时间阈值;基于所述待定拐点将所述第一时间段划分为的两个时间段中,至少一个时间段为所述滑音段;基于所述待定拐点将所述第一时间段划分为的两个时间段所对应的基频曲线斜率差大于预设斜率差阈值。
8、在本公开的一些示例性实施例中,所述基于音高运动阈值,根据所述音节核的音高运动模式化曲线,对所述音节核的音高运动进行标记,得到所述音节核对应的音高运动标识,包括:确定所述音节核的音高运动模式化曲线中,音高运动幅度最大的时间段;基于所述音高运动阈值,对所述幅度最大时间段的音高运动进行标记;以所述幅度最大时间段的音高运动标记,作为所述音节核对应的音高运动标识;所述音高运动标识,至少包括:上升、水平或下降。
9、在本公开的一些示例性实施例中,所述基于所述音频特征信息,驱动虚拟形象进行同步运动,还包括:基于所述音节核的音高运动模式化曲线,确定所述音节核的音节核音高变化值;响应于所述音节核音高变化值大于眉毛运动阈值,生成对应于所述音节核的眉毛运动曲线;所述眉毛运动阈值,用于判断是否触发生成所述音节核的眉毛运动曲线;基于所述眉毛运动曲线,驱动所述虚拟形象的眉毛进行同步运动。
10、在本公开的一些示例性实施例中,所述眉毛运动曲线由起始帧、峰值帧、结束帧确定;所述峰值帧与对应所述音节核的开始时间相对应;所述起始帧、结束帧与所述峰值帧之间为预设眉毛运动时间间隔;根据所述音节核音高变化值或相对音高变化值或所述音节核所对应时间段的音量,确定所述峰值帧的运动幅度。
11、在本公开的一些示例性实施例中,当相邻的两个所述眉毛运动曲线的时间间隔小于眉毛间隔阈值时,则根据所述两个眉毛运动曲线,生成合并眉毛运动曲线;所述眉毛间隔阈值,根据所述眉毛运动时间间隔确定。
12、在本公开的一些示例性实施例中,所述基于所述音频特征信息,驱动虚拟形象进行同步运动,还包括:基于所述音频特征信息,生成头部运动曲线;所述头部运动曲线与所述眉毛运动曲线为正相关关系;基于所述头部运动曲线,驱动所述虚拟形象的头部进行同步运动。
13、在本公开的一些示例性实施例中,所述基于所述音频特征信息,驱动虚拟形象进行同步运动,还包括:虚拟形象的眼部处于第一状态时,确定第一眼部注视坐标、第一眼部状态机、第一语言状态和第一眼动间隔;所述第一语言状态,根据所述音素序列确定为说话状态或倾听状态;所述第一眼动间隔,根据所述第一眼部状态机和所述第一语言状态确定;当所述眼部处于第一状态达到所述第一眼动间隔时,生成眼部目标转移至的第二状态;确定第二眼部注视坐标、第二眼部状态机、第二语言状态和第二眼动间隔;所述第二语言状态,根据所述音素序列确定;所述第二眼动间隔,根据所述第二眼部状态机和所述第二语言状态确定;眼部处于眼动状态,驱动眼部由所述第一眼部注视坐标转动至所述第二眼部注视坐标。
14、在本公开的一些示例性实施例中,所述基于所述音频特征信息,驱动虚拟形象进行同步运动,还包括:根据语言状态和眼动状态,确定触发眨眼事件;所述语言状态,根据所述音素序列确定为说话状态或倾听状态;所述眼动状态,根据眼部运动状态确定;响应于触发眨眼事件,驱动虚拟形象的眼睑进行眨眼运动。
15、根据本公开实施例的第二方面,提供一种与音频特征同步的脸部运动生成装置,包括:音频对齐模块,被配置为获取语音音频以及与所述语音音频对应的语音音频文本信息文本信息,将所述语音音频与所述文本信息对应的音素序列对齐;音频分析模块,被配置为基于对齐后的所述音素序列对所述语音音频进行音频分析,提取所述语音音频中的音频特征信息;运动驱动模块,被配置为基于所述音频特征信息,驱动虚拟形象进行同步运动。
16、根据本公开实施例的第三方面,提供一种电子设备,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述可执行指令,以实现如上任一项所述的动画生成方法动画生成方法。
17、根据本公开实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得电子设备能够执行如上任一项所述的动画生成方法动画生成方法。
18、本公开实施例提供的动画生成方法动画生成方法,对语音音频进行音频分析,提取出音频特征信息;基于音频特征信息,驱动虚拟形象进行同步运动。该方法通过提取语音音频中与副语言行为有关联关系的音频特征信息,并基于该音频特征信息驱动虚拟形象进行同步表情运动,使得虚拟形象表情与语音更加自然。
19、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!