一种基于跨模态认知共识对齐的音视频分割方法
本发明属于多模态图像分割领域,给定一段视频和对应的音频,以音频信号为参考,对视频中发出该声音的目标进行提取并生成像素级掩码。本发明通过所提出的跨模态认知共识推断模块和认知共识引导的注意力模块,对音、视频进行显式的语义级跨模态对齐,并获得良好的目标分割结果。
背景技术:
1、随着计算机视觉领域的不断发展,诸如语义分割、实例分割、全景分割的视觉图像目标细粒度分割技术已经取得了显著的成就,上述方法等同对待图像中的每一个目标和背景并对它们进行分割。然而,在真实多媒体应用场景中,往往只需要突出真正感兴趣的目标,这是上述图像分割方法无法实现的。而音视频分割的目的就是在音频信息的指导之下,精细化提取图像中感兴趣目标(发声目标),这种分割方法在现实应用场景中有着广泛的潜在用途与重要的意义。
2、音视频分割的主要挑战在于如下两个方面:一方面,模型需要充分理解视觉、音频两种模态各自的语义内容以及长距离上下文信息;另一方面,模型需要对视觉、音频模态进行显式、准确的对齐。准确来说,一段音频信息中通常只包含全局的音频标签信息,但视频的每一帧图像往往包含不同的局部目标,实现从全局到局部的对齐,并突出感兴趣的目标,是该项任务的关键性难点。
3、在视频、音频数据编码器方面,已经有许多优秀的模型被提出。在视觉模态方面,研究人员通常使用基于卷积神经网络(cnn)的视觉编码器,例如:resnet、vggnet等,或者使用更高性能的基于transformer的视觉编码器,例如:vit、swin transformer、pvt等;在音频模态方面,目前主流的方法是将音频转化为声谱图,并采用卷积网络结构的编码器去提取特征,广为应用的音频编码器有:vggish、panns等。上述高性能视觉、音频编码器为本方法提供了坚实的基础与稳定的保障。
4、本方法在eccv 2022的论文《audio-visual segmentation》的基础上进行进一步改进。在这篇论文提出的方法中,作者利用跨模态注意力模块,对提取的音频、视频特征进行稠密的跨模态交互,并将交互后的多模态特征输入分割头来实现音视频分割。然而,上述方法只对音视频模态进行了特征级的交互及对齐,单一的特征级对齐无法有效解决上述从全局到局部的维度差距问题。所以,为了解决上述问题,提出了一种基于语义级跨模态认知共识的方法,在音视频特征级交互的基础上进一步进行语义级交互,有效弥补维度差距并实现更为精确的分割。
5、本方案未在国内外出版物上公开发表,未在国内外公开使用或者以其他方式为公众所知。
技术实现思路
1、本发明的目的在于解决以下技术问题:
2、其一:现有的音视频分割方法仅仅利用单一的特征级交互来实现跨模态对齐,并无法解决从音频全局信息与视觉多个局部信息之间的维度差异问题;为了解决这一问题,本发明提出了跨模态认知共识推断模块以实现模态之间的语义级对齐;具体来说,本发明通过音视频编码器的分类头对音视频模态分别进行分类,并获得音视频模态各自的分类置信度,将上述置信度与音视频分类标签的语义相似度进行加权打分,以获得模态对齐的语义标签。
3、其二:在获得模态对齐的语义标签之后,本发明利用梯度反传技术,将模态对齐的标签传回视觉编码器中,并获得该语义类别对应的权重向量;本发明提出了认知共识引导的注意力模块,以将语义级对齐信息注入音视频分割框架中,从而实现音视频模态的特征级对齐与语义级对齐的结合;后续,本发明将音视频对齐的特征输入到通用的全卷积分割网络中,以实现对发声目标的分割;本发明通过推断跨模态认知共识并将其与特征级对齐相结合,达到了目前最先进的分割性能。现有的音视频分割方法使用跨模态注意力模块实现稠密的音视频特征级交互,但是由于更高层次的语义级跨模态对齐的缺失,现有方法难以解决音频全局标签与视频多个局部区域的维度差异问题
4、本发明技术方案为:一种基于跨模态认知共识对齐的音视频分割方法,该方法包括:
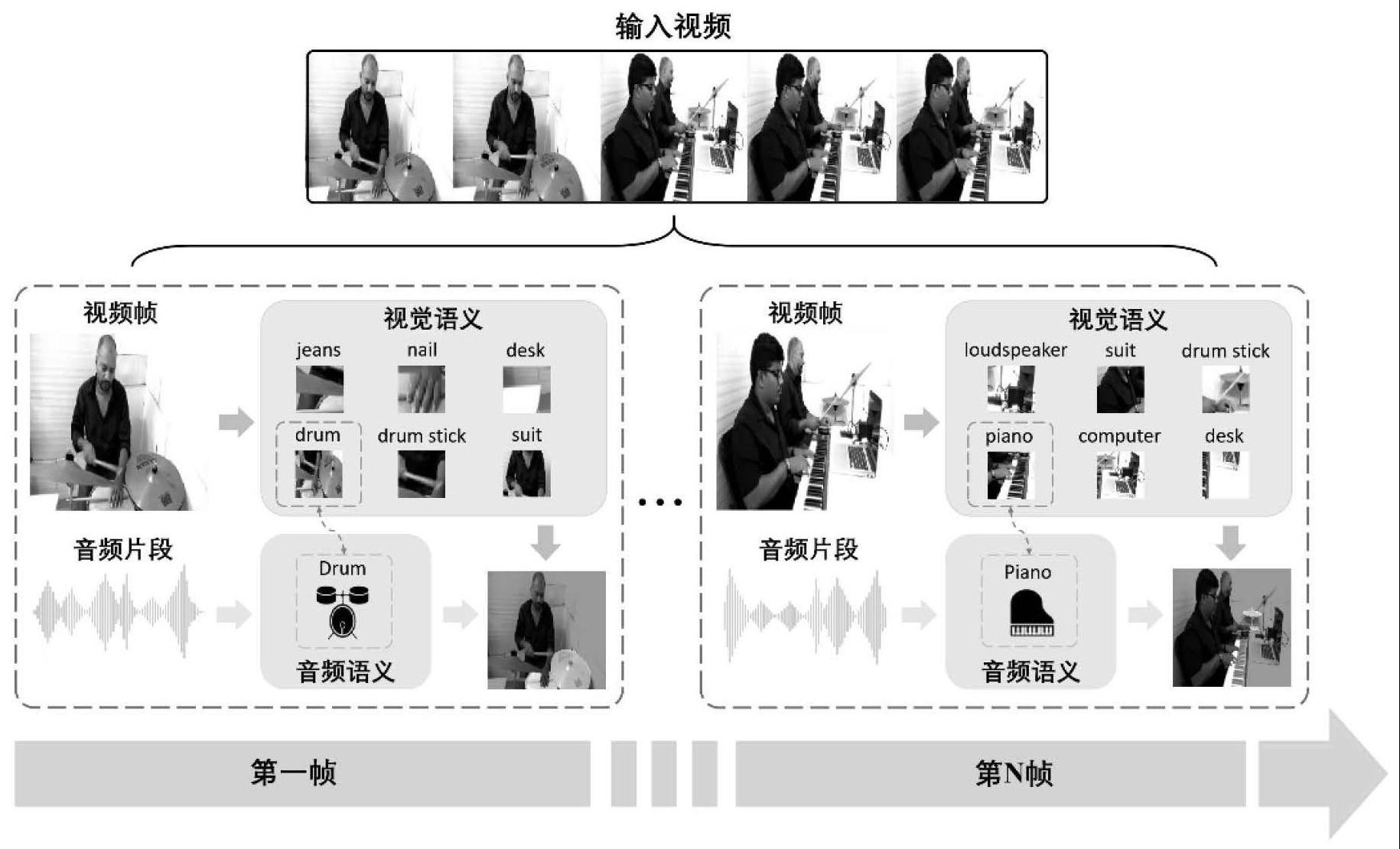
5、步骤1:获得视频帧以及其对应的音频片段;视觉编码器具有四个特征提取阶段,将视频帧输入至视觉编码器,并取视觉编码器四个阶段输出的视觉特征作为层次化视觉特征,并表示为vi,i=1,2,3,4;此外,将音频片段输入音频编码器,提取音频特征fa;层次化视觉特征vi与音频特征fa将用于进行后续计算;
6、步骤2:利用音频编码器和视觉编码器预置的分类头及其分类权重;在视觉编码器输出的层次化视觉特征vi,i=1,2,3,4中,v4为最高层级的视觉特征,并且包含图像的全局性语义信息;分别对视觉特征v4与音频特征fa进行类别置信度打分,计算得到的视觉分类置信度与音频分类置信度接着,计算视觉标签文本与音频标签文本之间的语义级相似度mjk,具体公式如下:
7、
8、其中,||·||f代表frobenius范数,j与k分别代表最终计算得到的语义相似度矩阵msim的行、列索引;接着,计算置信度重加权矩阵mcof(j,k),具体公式如下:
9、
10、其中,α与β为平衡系数,置信度重加权矩阵mcof(j,k)内的值即可看做对应视觉语义与文本语义的认知共识打分;在获取置信度重加权矩阵mcof(j,k)后,找到矩阵中的最大打分值,并获取最大值处对应的视觉标签,以作为模态对齐的语义标签;将模态对齐的语义标签以梯度反向传播的形式传回视觉编码器的四个层次化阶段,并得到类激活权重
11、步骤3:得到类激活权重后,将包含语义级对齐信息的权重集成到编码器提取的特征中,具体公式如下:
12、
13、
14、
15、
16、其中,σ代表sigmoid函数运算,avg指取平均操作,代表带有广播机制的逐点相乘;认知共识引导的注意力模以一种通道—空间的形式,将语义级认知共识权重与视频特征级表征集成在一起,得到集成信息以指导网络进行后续分割;
17、步骤4:首先对音频特征fa进行映射与重复操作,得到接着,将该层级的视觉特征vi通过空洞卷积模块得到via并与音频特征共同输入非本地模块中从而进行音视频特征级跨模态交互,具体公式如下:
18、
19、mi=via+θ4(φ·θ3(via)) (8)
20、公式中的θ1、θ2、θ3以及θ4分别代表不同的三维卷积层,n是特征谱的像素个数,φ是跨模态注意力矩阵,mi是第i级的多模态特征;
21、步骤5:将层级化的多模态特征mi进行融合,融合公式如下:
22、
23、公式中的conv代表卷积层、upsample代表上采样操作,将y1送入全卷积网络以获得网络的预测值最后,使用二值交叉熵损失对网络进行训练:
24、
25、其中,y代表分割掩码的真实值,lseg代表损失值。
26、本发明中,本发明提出了一种音视频跨模态语义级认知共识的方法,并提出了新的跨模态认知共识模块以及认知共识引导的注意力模块。跨模态认知共识模块分别计算音频、视觉分类置信度,并衡量音视频语义标签的互相似度,接着使用分类置信度对互相似度进行加权,得到语义级跨模态认知共识分数并选取语义对齐的标签。随后,将语义对齐的标签梯度反传回视觉编码器获取类激活信息,通过认知共识引导的注意力模块,突出语义一致性高的视觉目标,以指导后续的分割过程。一方面,本发明的方法在音视频分割数据集上达到了目前最先进的性能;另一方面,本发明的方法可以准确有效的分割出视频中的发声目标,并且输出像素级掩码。
- 还没有人留言评论。精彩留言会获得点赞!