预训练语言的学习微调方法、计算机装置及计算机可读存储介质与流程
本发明涉及大规模语言训练的,具体地,是一种针对大规模预训练语言模型的强化学习微调方法,还涉及实现该方法的计算机装置及计算机可读存储介质。
背景技术:
1、大规模预训练语言模型是近年来取得突破性进展的人工智能技术,其中最著名的模型是open ai的gpt,这种模型使用无标签的大规模文本数据进行预训练,从而学习到丰富的语言表示,然后,通过微调这些预训练模型,可以使其适应特定领域的任务或问题。
2、在强化学习领域,研究人员已经提出了多种方法来将预训练语言模型与强化学习相结合。例如,现有一种常用的方法是使用基于奖励信号的强化学习算法,通过与环境的交互来微调预训练模型,这种方法允许模型在特定任务中进行自我学习和优化。
3、关于针对特定领域的微调方法,现有一些文献提出了不同的技术和策略。例如,smith等人在其2019年的论文“offline reinforcement learning:tutorial,review,andperspectives on open problems”中介绍了离线强化学习的方法,该方法可以在没有实时交互的情况下进行微调。另外,li等人在其2020年的论文“train your own model(tyom):aself-supervised model for speech recognition”中介绍了一种自我监督的微调方法,该方法使用自动生成的标签来微调预训练模型,以适应特定的语音识别任务。
4、尽管大规模预训练语言模型在自然语言处理领域取得了巨大成功,但它们也存在一些问题和缺点。首先,这些模型往往需要大量的计算资源和时间进行预训练。其次,预训练的通用表示可能无法直接适应特定领域的细节和特征。此外,微调过程中可能会面临领域特定数据不足的挑战,特别是对于某些特定的垂直领域或任务。这些问题和困难限制了大规模预训练语言模型在特定领域应用中的效果和性能。
5、总而言之,目前的大规模预训练语言模型的核心能力来源于大量的训练数据和庞大的网络模型参数,但这种大规模效应在带来智能化的同时也使得模型难以被本地化部署和难以二次训练,在此背景下,微调训练被广泛的用于大规模预训练模型的知识增强。然而,目前针对微调训练并没有非常有效且具体的方式来进行。
6、公开号为cn115423118a的发明专利申请公开了一种预训练语言模型微调方法,该方法针对每一类任务通过初始预训练语言模型制定文本提示模板;将训练数据整理成批次数据并进行合并;打乱合并后的批次数据顺序;通过多任务学习微调预训练语言模型的参数。然而,该方法没有考虑到模型出现过拟合或者欠拟合的处理方式,尤其是没有针对过拟合进行有效的测试,导致训练获得的模型会存在过拟合的情况,影响训练模型的质量。
技术实现思路
1、本发明的第一目的是提供一种可以避免训练获得的模型过拟合或者欠拟合的预训练语言的学习微调方法。
2、本发明的第二目的是提供一种实现上述预训练语言的学习微调方法的计算机装置。
3、本发明的第三目的是提供一种实现上述预训练语言的学习微调方法的计算机可读存储介质。
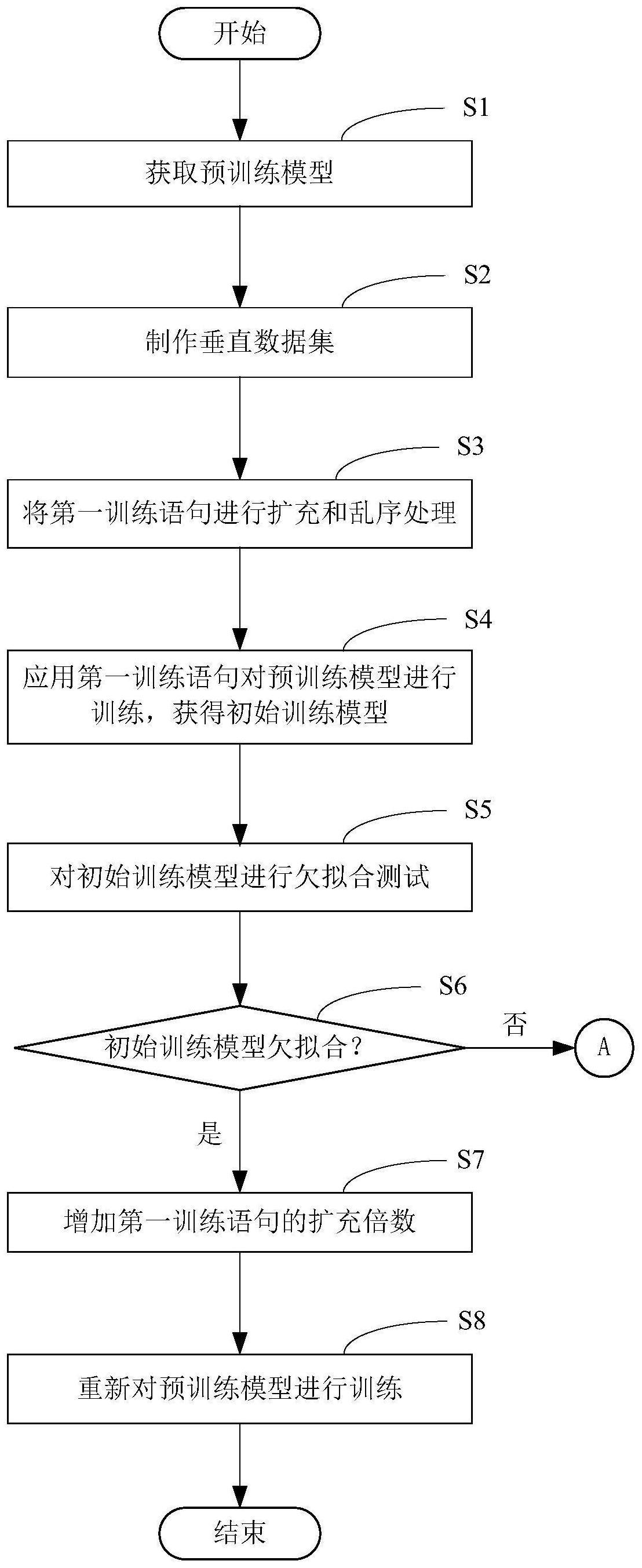
4、为实现本发明的第一目的,本发明提供的预训练语言的学习微调方法包括获取预训练模型,并制作垂直领域的垂直数据集,垂直数据集包括多组具有逻辑关系的第一训练语句,将第一训练语句进行扩充和乱序处理后,对预训练模型进行训练,获得初始训练模型;并且,应用第一训练语句对初始训练模型进行测试,根据初始训练模型对第一训练语句的答复准确率判断初始训练模型是否存在欠拟合的情况;如初始训练模型存在欠拟合的情况,则增加垂直数据集中第一训练语句的扩充倍数,对预训练模型进行重新训练;建立常识数据集,常识数据集包含有多组第二训练语句,将第二训练语句增量到垂直数据集中形成增量垂直数据集,应用增量垂直数据集对初始训练模型进行训练,获得增量训练模型,根据增量训练模型对增量垂直数据集中的训练语句的答复准确率判断初始训练模型是否存在过拟合的情况;如初始训练模型存在过拟合的情况,则减小垂直数据集中第一训练语句的扩充倍数,对预训练模型进行重新训练。
5、由上述方案可见,在训练获得初始训练模型后,需要对初始训练模型是否存在过拟合以及欠拟合的情况进行测试,并且针对过拟合、欠拟合的情况对扩充倍数进行动态调整,从而获得更加的训练模型,提升训练获得的模型质量。
6、另外,针对过拟合测试,设置了常识数据集,通过增加第二训练语句后的数据集对增量训练模型进行测试,能够有效判断出初始训练模型是否存在过拟合的情况,从而准确的对初始训练模型进行调整。
7、一个优选的方案是,制作垂直领域的垂直数据集时,应用前端界面输入第一训练语句,前端界面具有提示语输入框、问题输入框以及答案输入框。
8、由此可见,在进行训练时,用户可以快速的通过前端界面输入第一训练语句,操作简单,可以提升模型的训练效率。
9、进一步的方案是,前端界面还设置有数据导入按钮、数据扩充按钮、数据乱序按钮。
10、这样,用户可以通过数据导入按钮、数据扩充按钮、数据乱序按钮针对第一训练语句进行自动化的扩充、乱序处理,提升测试效率。
11、更进一步的方案是,建立常识数据集时,应用前端界面输入第二训练语句。
12、可见,应用相同的前端界面还可以输入第二训练语句,使得常识数据集的制作非常简单、方便。
13、一个优选的方案是,前端界面还设置有欠拟合检测按钮以及过拟合检测按钮;该方法还包括:在获取欠拟合检测按钮被按下的信号时,执行欠拟合检测操作,在获取过拟合检测按钮被按下的信号时,执行过拟合检测操作。
14、由此可见,进行过拟合测试以及欠拟合测试时,都是通过对前端界面的相应操作按钮进行的,通过前端界面就可以实现过拟合测试以及欠拟合测试,对初始训练模型的测试操作非常便捷。
15、优选的方案是,前端界面还设置有模型导出按钮;该方法还包括:在获取模型导出按钮被按下的信号时,导出微调后的训练模型。
16、这样,在确定训练模型满足要求,即不存在过拟合以及欠拟合的时候,可以通过模型导出按钮快速的导出训练获得的模型。
17、进一步的方案是,对第一训练语句的扩充倍数进行增加或者减少时,增加或者减少后的扩充倍数为整数倍。
18、这样,使得用于训练的第一训练语句与第二训练语句实现整数倍的扩充,训练效果更佳。
19、更进一步的方案是,第一训练语句为问答方式;和/或,第二训练语句为问答方式。
20、为实现上述的第二目的,本发明提供的计算机装置包括处理器以及存储器,存储器存储有计算机程序,计算机程序被处理器执行时实现上述预训练语言的学习微调方法的各个步骤。
21、为实现上述的第三目的,本发明提供计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述预训练语言的学习微调方法的各个步骤。
技术特征:
1.预训练语言的学习微调方法,包括:
2.根据权利要求1所述的预训练语言的学习微调方法,其特征在于:
3.根据权利要求2所述的预训练语言的学习微调方法,其特征在于:
4.根据权利要求2所述的预训练语言的学习微调方法,其特征在于:
5.根据权利要求4所述的预训练语言的学习微调方法,其特征在于:
6.根据权利要求2所述的预训练语言的学习微调方法,其特征在于:
7.根据权利要求1至6任一项所述的预训练语言的学习微调方法,其特征在于:
8.根据权利要求1至6任一项所述的预训练语言的学习微调方法,其特征在于:
9.计算机装置,其特征在于,包括处理器以及存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至8中任意一项所述预训练语言的学习微调方法的各个步骤。
10.计算机可读存储介质,其上存储有计算机程序,其特征在于:所述计算机程序被处理器执行时实现如权利要求1至8中任意一项所述预训练语言的学习微调方法的各个步骤。
技术总结
本发明提供一种预训练语言的学习微调方法、计算机装置及计算机可读存储介质,该方法包括获取预训练模型,并制作垂直领域的垂直数据集,垂直数据集包括多组具有逻辑关系的第一训练语句,将第一训练语句进行扩充和乱序处理后,对预训练模型进行训练,获得初始训练模型;并且,应用第一训练语句对初始训练模型进行测试,根据初始训练模型对第一训练语句的答复准确率判断初始训练模型是否存在欠拟合的情况;并且判断初始训练模型是否存在过拟合的情况,根据欠拟合或者过拟合的情况对第一训练语句的扩充倍数进行调整。本发明还提供实现上述方法的计算机装置及计算机可读存储介质。本发明能避免训练模型过拟合或者欠拟合。
技术研发人员:王瑞平,吴士泓,王志刚,冯荣
受保护的技术使用者:远光软件股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!