一种基于模型融合的化工过程故障诊断方法
本发明涉及化工故障诊断,具体涉及一种基于模型融合的化工过程故障诊断方法。
背景技术:
1、化学工程是一门专业性强的复杂学科,涉及许多基础理论及新技术的应用。在化工生产过程中,会产生许多的故障问题。如何提高这些故障的诊断准确率,是一个值得深入研究的问题。化工过程数据具有非线性、高维、非高斯分布等特征,因此对于故障检测过程提取故障的信息会更加复杂。
2、目前,比较流行的pca、ica、kpca、kica、mica等传统方法虽然可以有效地检测出生产过程中某种物料产生损失导致的阶跃型故障,或物料之间的组成发生改变导致的随机变化型故障等。但对于某些扰动性故障:如反应动力学常数发生变化导致的慢漂移类型故障,或冷凝器冷却水阀门发生改变引起的粘滞型故障等的检出率极低。因此,传统的方法依旧未能完全准确地提取出这些故障的信息。
3、传统的方法主要存在对化工故障数据进行特征提取需要大量的专家知识和信号处理技术,并且对于不同的任务,没有统一的程序来完成。另,传统的方法如pca方法进行特征提取时因为数据的尺度不统一,需要对数据进行标准化操作,因此数据中的噪声经过这种操作后对数据的影响变得更为明显。此外该方法原理主要为了消除变量之间的相关性,并且假设数据之间的相关性是线性的,而化工故障数据是非线性的,因此特征提取能力不高。并且该方法假设数据是服从高斯分布的,而化工数据一般是非高斯分布,所以该方法提取信号的高维非线性关系方面能力有限,也就是特征提取能力较差。最后是对故障数据的诊断精度不是很高,达不到故障诊断任务的要求。
技术实现思路
1、针对上述的传统方法的特征提取能力较差,对故障数据的诊断精度低的技术问题,本技术方案提供了一种基于模型融合的化工过程故障诊断方法,通过对原始的transform模型进行改进优化,并与膨胀卷积网络结合,加强模型特征提取的效果;对故障数据使用正交位置编码获取位置信息,将获得的位置编码信息与原始故障数据融合,提高模型对故障诊断的精度;能有效的解决上述问题。
2、本发明通过以下技术方案实现:
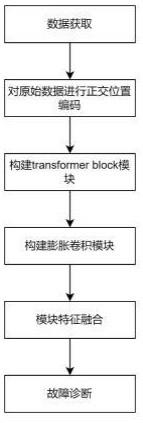
3、一种基于模型融合的化工过程故障诊断方法,通过对原始的transform模型进行改进优化,并与膨胀卷积网络结合,加强模型特征提取的效果;对故障数据使用正交位置编码获取位置信息,将获得的位置编码信息与原始故障数据融合,提高模型对故障诊断的精度;化工故障诊断方法的具体步骤包括:
4、步骤1:获取化工历史时序数据,并将其作为训练样本集和测试样本集;
5、步骤2:对于获取的化工历史时序数据进行正交位置编码操作,获取数据的位置编码信息;通过如下公式构造对称矩阵:
6、d=[dij]=r|i-j| i,j=1,2,…,l3 0<r<1
7、其中,r是超参数;dij代表元素之间的位置关系,dij值大,表示两个元素位置越接近;i,j为每一批输入网络的化工数据的大小,一般为正整数;l3为分解得到的特征向量的个数,一般为正整数;d是实对称矩阵,可以被分解为vλvt,其中λ为对角矩阵;
8、计算矩阵d的特征向量并将其表示为:
9、
10、
11、最后,位置编码通过如下公式来设计:
12、
13、其中u是化工时序数据中每一个变量的位置,一般为正整数;是计算得到的特征向量,由特征向量v1,u到组成的p(u)就是最后获得的位置编码;将获得的位置编码信息与原始化工数据融合,得到可用于模型训练的数据;
14、步骤3:构建神经网络模型并进行模型训练,神经网络模型结构包括transformerblock模块和膨胀卷积模块两个部分;
15、步骤3.1:构建transformerblock块;每个block块中包括多头自注意力机制、层归一化层和前馈层,前馈层使用卷积层代替全连接层,层与层之间引入稠密连接增强模型的特征复用能力;
16、步骤3.2:利用transformerblock块对步骤2得到的可用于模型训练的数据进行特征提取;
17、步骤3.3:构建膨胀卷积网络模型来提取原始化工时序数据的数据特征,膨胀卷积网络模型包括膨胀卷积层、池化层、全局池化层、和批量归一化层;
18、步骤3.4:利用膨胀卷积网络模型对步骤2得到的可用于模型训练的数据进行特征提取;
19、步骤4:使用concat函数将transformerblock块和膨胀卷积网络模型提取到的特征进行融合;
20、步骤5:在训练过程中采用adam梯度优化器优化网络使其损失函数的总体损失最小,损失函数采用交叉熵损失函数,公式如下:
21、
22、式中,y为输出实际值,为输出预测值;
23、步骤6:使用softmax函数进行最后故障的分类。
24、进一步的,步骤1所述的训练样本集用于建立本方法的故障诊断模型,测试样本集用于验证本方法的诊断精度。
25、进一步的,步骤2中所述的对角矩阵,其中的对角元素为特征值λi,i=1,2,…,l3,是正交矩阵,正交矩阵中的列是特征值λi对应的特征向量。
26、进一步的,步骤3.2所述的利用transformerblock块对步骤2得到的可用于模型训练的数据进行特征提取,其具体的方式为:
27、将可用于模型训练的数据输入到多头自注意力机制进行特征提取,多头自注意力机制由自注意力机制构成,自注意力机制通过下式进行计算:
28、
29、式中,q为query向量,k为key向量,v为value向量,kt为k向量的转置,为缩放因子;
30、通过下式计算多个自注意力机制组成的多头自注意力机制:
31、multihead(q,k,v)=concat(head1,…,headh)w0
32、
33、式中,q为query向量,k为key向量,v为value向量,headh为第h个自注意力机制的结果,w0为权重矩阵,为query权重矩阵,为key权重矩阵,为value权重矩阵,concat为特征拼接函数;
34、可用于模型训练的数据经过多头自注意机制进行特征提取后进入层归一化层,对数据进行归一化操作;然后数据进入前馈层。
35、进一步的,所述的前馈层使用两层卷积神经网络对数据特征进行进一步的提取;层与层之间使用稠密连接增强模型的特征复用能力。
36、进一步的,步骤3.4所述的利用膨胀卷积网络模型对步骤2得到的可用于模型训练的数据进行特征提取,其具体的方式为:
37、可用于模型训练的数据进入膨胀卷积层提取数据的特征信息,膨胀卷积通过下式计算:
38、
39、其中,x为输入的时序数据,f为卷积滤波器,为膨胀系数为d的卷积运算符号,k为卷积核大小,s-d·i为卷积计算进行的方向;
40、通过使用膨胀卷积可以扩大感受野,捕获非相邻数据的相关性特征;其次可以捕获多尺度信息,在膨胀卷积中,可以设置膨胀系数,当设置不同膨胀系数时,具有不同的感受野,能获取对应数据的多尺度信息;
41、在经过膨胀卷积层提取特征后,数据特征进入批量归一化层,即为bn层,通过bn层的使用减少协变量偏移,加快网络训练的收敛速度,提高网络泛化能力;
42、使用relu函数进行非线性变换,公式如下:
43、g(x)=max(0,x)
44、式中,x为输入的时序数据;
45、然后对数据进行下采样,使用最大池化操作,其运算可描述为:
46、
47、式中,为池化后第i个特征图中第j个神经元的输出值,为第l层第i个特征图中第t个神经元的输入值,w为池化核的宽度。
48、进一步的,所述膨胀卷积网络模型的最后一层使用全局池化层,改变数据的维度。
49、有益效果
50、本发明提出的一种基于模型融合的化工过程故障诊断方法,与现有技术相比较,其具有以下有益效果:
51、(1)本技术方案使用transformerblock模块和膨胀卷积模块作为模型的特征提取部分,transformerblock模块可以更好的学习化工故障信息长时间内的时序特征和全局特征,膨胀卷积模块可以获取故障信息的局部特征,将两个模块得到的特征信息进行融合,可以得到更加准确的故障关系。使用了正交位置编码,减轻了由加法运算引起的数据间相关性的恶化,丰富了数据的特征信息。相比于普通卷积神经网络,具有特征提取能力更强,诊断准确率更高。
52、(2)本技术方案提出了正交位置编码技术,通过使用这种位置编码方式,丰富了数据的特征信息,提高了故障诊断的准确率。并对原始transformer进行改进优化,在前馈层使用卷积层代替全连接层,减少模型的参数,提高训练的速度;层与层之间引入稠密连接增强模型的特征复用能力。使用transformerblock模块学习化工故障信息长时间内的时序特征和全局特征,使用膨胀卷积模块获取故障信息的局部特征;通过将两个模型提取到的特征进行融合,并且采用了并行的网络架构,最大程度避免了特征丢失,保留了数据特征的全局和局部信息。该模型能够挖掘数据中隐藏特征,学习到的特征通常是逐层加深的,具有更强的特征提取能力;具有更高的鲁棒性,且对故障的诊断精度得到了很大的提高。
- 还没有人留言评论。精彩留言会获得点赞!