事件论元抽取方法、装置
本发明涉及事件抽取,尤其涉及一种基于句子级的事件论元抽取方法、装置。
背景技术:
1、事件抽取是信息抽取领域中的重要任务之一,其目标是对于给定的非结构化文本,从中抽取出结构化的事件信息,包含事件触发词、事件类型、事件论元及其扮演的角色。按照所涉及文本范围的不同,事件抽取可以分为句子级和篇章级两类,本发明关注的是句子级事件抽取,下文在不引起混淆的情况下简称为事件抽取。目前,事件抽取任务通常采用基于深度学习的方法,根据结果获取方法的不同又可以分为两类:基于分类的方法和基于生成的方法。前者将事件抽取视为词级别的多分类任务,通过对输入文本中的所有单词进行标签分类得到最终的抽取结果;后者采用端到端的形式,直接生成事件的触发词和论元内容,通过生成内容与原文本进行对比定位得到最终的结构化事件结果。
2、现有的事件抽取方法在两个子任务上均取得较好的效果,然而现有方法忽略了训练数据本身存在的失衡问题,这导致模型在训练过程中出现部分性能损失。所谓训练数据失衡包含两个方面,一方面是事件检测中不同的事件类型其训练样本在数量上的巨大差异,现有方法一般通过训练单一模型来识别所有事件类型,这种方法虽然能够简化算法的实现和管理,但是由于不同事件类型之间的数据量可能存在差异,单一模型在不同事件类型上的表现也可能存在偏差。另一方面是事件论元抽取时论元角色在原始文本中存在与否所引起的数量上的不均衡,现有方法都假定句子中包含所有的论元角色。但实际上,一个句子往往并不包含所有的论元角色,模型训练的负样本构建过多,导致在测试集上的召回率非常低。
技术实现思路
1、针对上述的问题,本发明提出一种事件论元抽取方法、装置,其通过事件类型表示增强的两阶段事件抽取方法来实现,解决了事件抽取中缺乏对训练数据失衡的考量的问题。
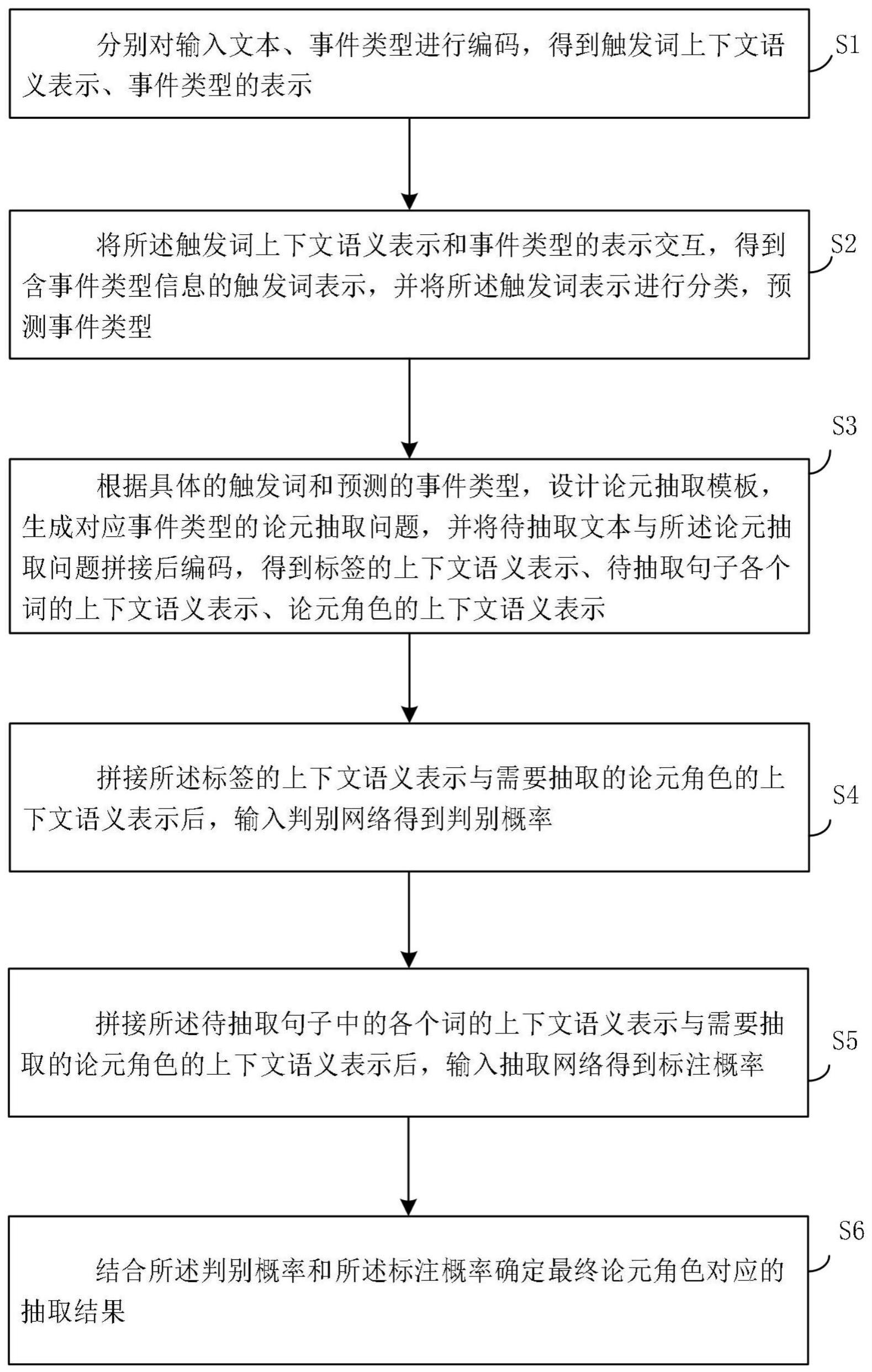
2、为了实现上述目的,本发明一方面提供一种事件论元抽取方法,包含:
3、分别对训练数据、事件类型进行编码,得到触发词上下文语义表示、事件类型的表示;
4、将所述触发词上下文语义表示和事件类型的表示交互,得到含事件类型信息的触发词表示,并将所述触发词表示进行分类,预测事件类型;
5、根据具体的触发词和预测的事件类型,设计论元抽取模板,生成对应事件类型的论元抽取问题,并将待抽取文本与所述论元抽取问题拼接后编码,得到标签的上下文语义表示、待抽取句子各个词的上下文语义表示、论元角色的上下文语义表示;
6、拼接所述标签的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到判别概率;
7、拼接所述待抽取句子中的各个词的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到标注概率;
8、结合所述判别概率和所述标注概率确定最终论元角色对应的抽取结果。
9、可选的,对训练数据进行编码,得到触发词上下文语义表示,包含:
10、对训练数据进行预处理,
11、使用bert预训练语言模型对预处理后的所述训练数据进行预编码,得到每个字经bert预训练模型编码后的分布式语义表达;
12、聚合其中触发词对应的分布式语义表达,得到触发词上下文语义表示。
13、可选的,对事件类型进行编码,得到事件类型的表示,包含:
14、根据事件类型的层级关系构建图神经网络,其中图节点为事件类型和子事件类型的标签节点,当子事件类型从属于事件类型时,其对应节点间出现连边;
15、在图节点间进行信息传递,得到事件类型的表示。
16、可选的,将所述触发词上下文语义表示和事件类型的表示交互,得到含事件类型信息的触发词表示,包含:
17、将所述触发词上下文语义表示和事件类型的表示进行注意力计算,得到含事件类型信息的触发词特征;
18、依据所述触发词特征与所述触发词上下文语义表示的加权之和,得到所述触发词表示。
19、可选的,根据事件的触发词和预测的事件类型,设计论元抽取模板,生成对应事件类型的论元抽取问题,包含:
20、将所述触发词、预测的事件类型、论元抽取模板进行拼接,得到论元抽取问题;
21、其中,事件类型提供给定事件类型的定义,事件的触发词描述指定需抽取论元的对应触发词,论元抽取模板表示给定事件类型的结构。
22、可选的,将待抽取文本与所述论元抽取问题拼接后编码,得到标签的上下文语义表示、待抽取句子各个词的上下文语义表示、论元角色的上下文语义表示,包含:
23、将待抽取文本与所述论元抽取问题进行拼接后进行预处理并输入至bert预训练语言模型进行预编码,得到标签的上
24、下文语义表示、待抽取句子各个词的上下文语义表示、以及论元角色对应片段的上下文语义表示;
25、聚合其中论元角色对应片段的上下文语义表示,得到需要抽取的论元角色的上下文语义表示。
26、可选的,拼接所述标签的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到判别概率,包含:
27、选择标签的上下文语义表示与需要抽取的论元角色的上下文语义表示拼接,得到该论元角色在该文本中的判别特征;
28、将所述判别特征输入一个两层的判别网络进行特征建模;
29、通过softmax函数建模该论元角色在该文本中可抽取的概率,确定判别概率:
30、
31、其中,表示该论元角色在文本中没有答案的判别概率,表示该论元角色在文本中有答案的判别概率。
32、可选的,拼接所述待抽取句子中的各个词的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到标注概率,包含:
33、将所述待抽取句子中的各个词的上下文语义表示与需要抽取的论元角色的上下文语义表示拼接,得到各个词针对该论元角色的抽取特征;
34、将所述抽取特征分别输入三个两层的判别网络,分别建模词作为角色对应论元指称的start标签特征、end标签特征和bio标签特征;
35、
36、
37、
38、
39、
40、
41、其中,zstart、zend、zbio分别表示start标签特征、end标签特征和bio标签特征,表示判别特征,均为可学参数;
42、分别依据词作为角色对应论元指称的start标签特征、end标签特征和bio标签特征,通过softmax函数建模该词作为该角色对应论元指称的start标签概率、end标签概率和bio标签概率,确定标注概率;
43、
44、
45、
46、其中,标注概率包含start标签概率、end标签概率和bio标签概率,表示词不作为该论元指称start标签概率、end标签概率,表示词作为该论元指称start标签概率与end标签概率,表示该token不作为论元指称的一部分的概率,表示该token作为该论元指称起始位置的概率,表示该token作为该论元指称中间内容的概率。
47、可选的,所述结合所述判别概率和所述标注概率确定最终论元角色对应的抽取结果,包含:
48、依据论元角色在文本中有答案的判别概率,得到有答案的判别得分;
49、依据所述标注概率得到有答案的目标抽取得分,包含:
50、依据作为该论元指称的start标签概率与作为该论元指称的end标签概率的加权之和取均值,得到第一抽取得分;
51、依据token作为该论元指称起始位置的概率与token作为该论元指称中间内容的概率的加权之和取均值,得到第二抽取得分;
52、依据所述第一抽取得分与所述第二抽取得分加权之和,得到有答案的目标抽取得分;
53、依据所述判别得分和所述目标抽取得分加权之和,得到抽取片段为问题回答的综合得分;
54、依据所述综合得分,确定最终论元角色对应的抽取结果,包含:
55、在所述综合得分超过一分数阈值时,表示问题可回答,将该抽取片段添加至角色对应论元指称的结果中;
56、在所述综合得分未超过一分数阈值时,表示问题不可回答,将该抽取片段丢弃。
57、本发明另一方面还提供了一种事件论元抽取装置,采取上述的事件论元抽取方法,至少包含:
58、文本与事件类型编码模块,用于分别对训练数据、事件类型进行编码,得到触发词上下文语义表示、事件类型的表示;
59、交互与预测模块,用于将所述触发词上下文语义表示和事件类型的表示交互,得到含事件类型信息的触发词表示,并将所述触发词表示进行分类,预测事件类型;
60、问题编码模块,用于根据具体的触发词和预测的事件类型,设计论元抽取模板,生成对应事件类型的论元抽取问题,将待抽取文本与所述论元抽取问题拼接后编码,得到标签的上下文语义表示、待抽取句子各个词的上下文语义表示、论元角色的上下文语义表示;
61、论元角色判别模块,用于拼接所述标签的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到判别概率;
62、论元角色抽取模块,用于拼接所述待抽取句子中的各个词的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到标注概率;
63、论元角色解码模块,用于结合所述判别概率和所述标注概率确定最终论元角色对应的抽取结果。
64、由以上方案可知,本发明的优点在于:
65、本发明提供的事件论元抽取方法,用于基于句子级的事件论元抽取,主要分为事件检测与论元抽取两个过程。其中,在事件检测过程中,通过分别对训练数据、事件类型进行编码,得到触发词上下文语义表示、事件类型的表示;以及将触发词上下文语义表示和事件类型的表示交互,得到含事件类型信息的触发词表示,并将所述触发词表示进行分类,预测事件类型的事件检测,该过程在事件检测任务中引入了事件类型的层级关系构建图神经网络进行事件类型编码,这类关系这种层次关系在给定数据集上永久成立,无需人工设计,避免了使用人工设计或第三方工具引入的额外知识而引入噪声。其中,在论元抽取过程中,通过生成对应事件类型的论元抽取问题,并将待抽取文本与所述论元抽取问题拼接后编码,得到标签的上下文语义表示、待抽取句子各个词的上下文语义表示、论元角色的上下文语义表示;然后,拼接所述标签的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到判别概率;拼接所述待抽取句子中的各个词的上下文语义表示与需要抽取的论元角色的上下文语义表示后,输入判别网络得到标注概率;最后,结合所述判别概率和所述标注概率确定最终论元角色对应的抽取结果。该事件论元抽取任务中引入了判别网络,在计算成本增加较少的情况下,通过两阶段的结果融合,有效地缓解样例不均衡问题。同时,结合了判别概率和标注概率进行论元角色抽取,进一步提升论元抽取性能。
- 还没有人留言评论。精彩留言会获得点赞!