一种面向健康监测的标准数据库建立与更新方法与流程
本发明涉及数据库领域,具体地,涉及一种面向健康监测的标准数据库建立与更新方法。
背景技术:
1、随着对设备可靠性、寿命和维护费用的要求日益苛刻,基于数据的设备健康监测技术已广泛应用于工业过程中,以便预防及时识别设备的状态、发现故障早期征兆,及时消除故障隐患,实现设备的智能维护。但目前工业过程中普遍存在多种工况且各工况之间的数据极度不平衡,同时数据库的数据量很大。目前的数据库是通过mysql等软件根据数据表建立的,存储原则是有数据就存,不做任何选择性存储的策略,不管数据量有多大,直接进行查询和调取,随着数据量越来越大,查询和调取的时间会越来越大,这导致基于数据的设备健康监测技术在查询和调取所需数据时费时费力,对于新工况或者某些数据较少的工况,容易出现所需数据较少,严重影响监测技术的有效性和实时性。
技术实现思路
1、本发明目的是构建数据量少且能够全面代表原始数据的数据库,以便减少基于数据的设备健康监测技术在查询和调取所需数据时时间和工作量。
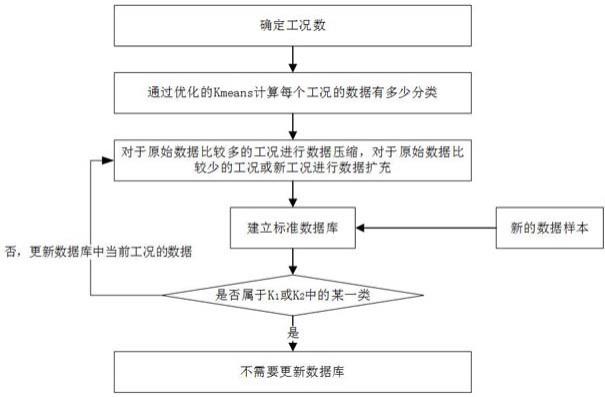
2、为了实现上述发明目的,本发明提供了一种面向健康监测的标准数据库建立与更新方法,所述方法包括:
3、步骤1:构建数据库;
4、步骤2:获得设备的原始数据;
5、步骤3:基于原始数据确定设备的工况数,基于设备的工况数获得每种工况对应的原始数据;
6、步骤4:基于聚类算法计算获得每种工况对应的原始数据的分类数目;
7、步骤5:基于分类数目,对每种工况对应的原始数据进行分类,获得每个类别对应的原始数据;
8、步骤6:判断每个类别对应的原始数据是否满足数据数量预设要求,若不满足,则对相应类别对应的原始数据进行数据扩充或压缩处理,获得每个类别对应处理后的数据;
9、步骤7:将每个类别对应处理后的数据以类别作为标签存入所述数据库中。
10、其中,本方法首先确定工况数,然后基于聚类算法计算获得每种工况对应的原始数据的分类数目,基于分类数目对每种工况对应的原始数据进行分类,获得每个类别对应的原始数据;然后判断每个类别对应的原始数据是否满足数据数量预设要求,若不满足,则对相应类别对应的原始数据进行数据扩充或压缩处理,获得每个类别对应处理后的数据;通过本方法既能适应所有工况,又能通过对原始数据比较少的工况或新工况的数据进行扩充来确保每个工况的数据量足够,还能通过对原始数据比较多的工况进行压缩,用尽可能少的数据有效且较全面的代表原始数据,以便减少数据库的数据量。
11、在一些实施例中,所述步骤6具体包括:
12、判断每个类别对应的原始数据的数据量是否大于n1且小于n2,若某类别对应的原始数据的数据量小于n1,则对该类别对应的原始数据进行数据扩充处理,即对于数据量较小的类别则对其进行数据扩充处理,保障其数据量和全面性,保障每种工况的数据量足够;若某类别对应的原始数据的数据量大于n2,则对该类别对应的原始数据进行数据压缩处理,即对于数据量较大的类别,则对其进行数据压缩处理,以减少数据库的数据量。
13、在一些实施例中,所述步骤4具体包括:
14、步骤4.1:初始化聚类个数、聚类算法的迭代次数和初始聚类中心种子;
15、步骤4.2:利用粒子群优化算法初始化粒子,粒子以聚类个数、聚类算法的迭代次数和初始聚类中心种子为坐标;
16、步骤4.3:将粒子的坐标值作为超参数赋给聚类算法以ch指标为目标函数进行聚类;其中,calinski-harabaz指标(ch指标)越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果;
17、步骤4.4:计算聚类后的ch值,判断ch值是否满足收敛条件,若不满足则更新粒子坐标返回执行步骤4.3,若满足则输出最优的超参数作为工况对应的原始数据的分类数目。
18、在一些实施例中,ch值的计算方式为:
19、;
20、其中,s为ch值,n为容量,k为聚类个数,bk为类间的协方差矩阵,wk为类内数据的协方差矩阵,为bk的秩,为wk的秩。
21、在一些实施例中,bk的计算公式为:
22、;
23、wk的计算公式为:
24、;
25、其中,cq表示类q的中心点,ce表示数据集的中心点,nq表示类q中的数据的数目,表示类q的数据集合,x为类q中的数据,t表示将(x-cq)进行转置。
26、在一些实施例中,所述聚类算法为k-means算法。
27、在一些实施例中,所述步骤2还包括对原始数据进行清洗,获得清洗后的数据,原始数据中可能存在杂质数据,清洗可以去掉不相关的数据,提高的数据的有效性。
28、其中,在一些实施例中,所述方法还包括步骤8,对数据库中的数据进行定期备份处理,由于数据库中的数据比较重要,单独存在数据库中,当数据库被攻击或异常时会导致数据丢失,因此定期对数据库进行备份可以保障数据的安全性。
29、在一些实施例中,当某工况对应的原始数据数据量大于第一阈值时,对于该工况中的每个类别,如果该类别的数量大于n1,则选取距离聚类质心最近的n1个样本;如果该类别的数量小于n1,则将该类别中的样本数量扩充到n1个,得到个样本,,k1为聚类个数。以便在满足数据量约束的基础上,用尽可能少的数据有效且较全面的代表原始数据。
30、在一些实施例中,当某工况对应的原始数据数据量小于第二阈值时,对于该工况中的每个类别,如果该类别的数量大于n2,则选取距离聚类质心最近的n2个样本,如果该类别的数量小于n2,则将该类别中的样本数量扩充到n2个,得到个样本,,k2为聚类个数。以便在满足数据量约束的基础上,确保数据能有效代表当前原始数据。
31、在一些实施例中,所述方法还包括:
32、获得新样本数据,根据新样本数据中的工况信息确定所属工况信息;
33、基于所属工况信息获得与该工况信息对应的分类信息;
34、基于分类信息判断新样本数据是否属于其中的某一类别;
35、若新样本数据属于其中的某一类别,则将该类别作为新样本数据的标签将新样本数据存入所述数据库中;
36、若新样本数据不属于其中的某一类别,则基于新样本数据更新该工况对应的原始数据,然后执行步骤4至步骤7对所述数据库进行更新。
37、其中,本方法利用上述步骤可以实现数据库的新样本数据处理功能,完整数据库的更新操作。
38、在一些实施例中,基于分类信息判断新样本数据是否属于其中的某一类别,具体包括:
39、基于分类信息获得新样本数据与类心的距离;
40、若新样本数据与类心的距离均大于最大类内距离,则判断新样本数据不属于其中的某一类别;
41、若存在新样本数据与类心的距离小于最大类内距离,则选择与新样本数据的距离最小的类别为新样本数据所属的类别。
42、本发明提供的一个或多个技术方案,至少具有如下技术效果或优点:
43、通过本方法既能适应所有工况,又能通过对原始数据比较少的工况或新工况的数据进行扩充来确保每个工况的数据量足够,还能通过对原始数据比较多的工况进行压缩,用尽可能少的数据有效且较全面的代表原始数据,以便减少数据库的数据量,这样减少了基于数据的设备健康监测技术在查询和调取所需数据时时间和工作量。
44、本方法制定的更新数据库的规则能有效应对出现新工况或已有工况中出现新类别的情况。
- 还没有人留言评论。精彩留言会获得点赞!