一种适于监控视频下的车辆目标跟踪方法
本发明属于智能交通,具体涉及一种适于监控视频下的车辆目标跟踪方法。
背景技术:
1、车辆跟踪技术是智能交通系统中非常重要的一项技术,它可以实现对交通道路中的车辆实时监控和跟踪,为交通管理和控制提供重要的数据支持和决策依据。车辆目标跟踪对于研究车辆目标的行为特点具有重要的实用价值。通过对车辆的实时跟踪和监控,可以获取道路交通数据,对车辆运动行为进行分析,从而优化交通流量,提高道路通行能力和交通的安全性。但是在交通场景下,车辆运动带来的车辆间频繁的遮挡、运动模糊、多尺度和变尺度,以及车辆间的相似性,给车辆准确跟踪带来了巨大挑战。因此,如何准确的对车辆进行跟踪,成为了当下智能交通系统研究的一大难点。
2、车辆跟踪要使用多目标跟踪算法,多目标跟踪算法主要分为两类:一个是基于检测的跟踪范式,另一个是联合检测跟踪范式。现目前使用深度学习的车辆目标跟踪方法大多是基于检测的跟踪模型。基于检测的跟踪范式又称两阶段的跟踪方法,该方法首先对图像中的目标进行检测,确定目标的位置、大小和类型,并利用跟踪算法对相邻帧中的同一目标进行跟踪。此类方法的缺点是目标跟踪的效果依赖于检测的效果,并且检测任务和跟踪任务相互隔离,无法共享信息,难以在复杂场景下准确的进行车辆跟踪。
3、现有的基于检测的跟踪方法实际应用到交通场景中,由于车辆目标间的频繁遮挡、车辆目标的尺度快速变化,以及车辆间的相似性和复杂的交通环境等因素导致难以准确稳定的跟踪车辆。
4、查阅相关专利发现,中国专利公开了一种多目标车辆跟踪方法(公告号:cn113674328a),其提出了一种基于检测模型的车辆多目标跟踪方法,通过rfb-net检测器对输入视频帧进行目标车辆检测,但rfb-net在不同尺度的目标检测上表现不一,可能会出现漏检和误检等问题,此外在拥挤场景中,rfb-net难以准确检测和定位目标。中国专利还公开了一种基于yolov4的多目标车辆检测跟踪方法(公告号:cn113205108a),其通过改进的yolov4目标检测网络对视频帧进行车辆检测,并通过卡尔曼滤波器对车辆位置进行预测,但卡尔曼滤波器难以适应非线性运动车辆的位置预测。上述专利与原技术相比,检测性能有所提高,但仍存在漏检、误检、具有局限性,难以预测非线性运动车辆位置的问题。
5、因此,亟需一种准确性更高、稳定性更强的适于监控视频下的车辆目标跟踪方法。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种适于监控视频下的车辆目标跟踪方法。本发明旨解决现有车辆目标跟踪方法准确性差、稳定性低,难以应用于实际的问题。
2、为达到上述目的,本发明提供了一种适于监控视频下的车辆目标跟踪方法,包括以下步骤:
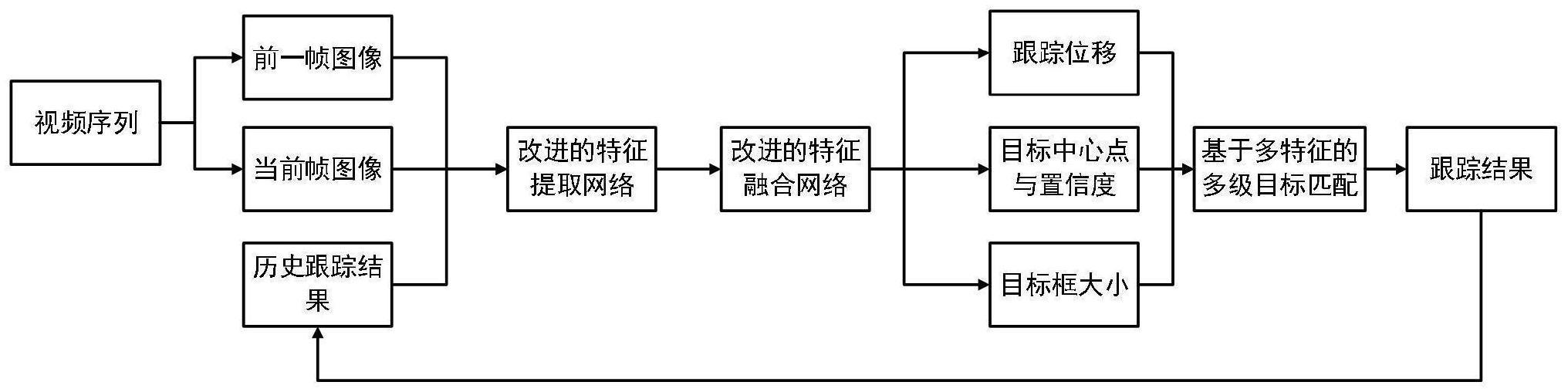
3、s1.改进联合检测跟踪模型transcenter的主干网络结构,利用卷积结构构建注意力模块;
4、s2.改进联合检测跟踪模型transcenter的特征融合网络,利用矩阵分解模型构建多尺度特征融合网络;
5、s3.设计多特征多级车辆目标匹配算法;
6、s4.在公开的车辆目标跟踪数据集ua-detrac上训练联合车辆目标检测跟踪模型;
7、s5.使用训练的模型跟踪监控视频下的车辆目标。
8、进一步,所述步骤s1包括以下子步骤:
9、s1.1通过大核卷积构建多分支大核卷积注意力模块ms-lkca,注意力模块能够利用多分支结构提取图像上不同尺度的特征信息,并进行多尺度特征聚合,聚合后的特征信息能够作为注意力权重;
10、其中,大核卷积能够分解、结合,所述大核卷积包括深度可分离空洞卷积dw-d-conv、深度可分离卷积dw-conv和1×1卷积;
11、s1.2基于ms-lkca构建编码器模块,所述编码器模块包括bn层、1×1卷积、gelu激活层、ms-lkca模块和前馈网络ffn;
12、s1.3基于步骤s1.2构建的编码器模块搭建主干网络,主干网络分为四个阶段:stage1、stage2、stage3和stage4;
13、s1.4将视频序列的当前帧图像和前一帧图像输入主干网络,提取主干网络stage1、stage2、stage3和stage4对应的特征图f1、f2、f3和f4,特征图作为后续网络的输入。
14、进一步,所述步骤s1.3中,在主干网络的四个阶段,输出特征的空间分辨率依次递减,分别为和其中,h表示输入图像的高度;w表示输入图像宽度。
15、进一步,所述步骤s1.3中,四个阶段对应的编码器模块数量分别为3、3、12和3。
16、进一步,所述步骤s2包括以下子步骤:
17、s2.1通过矩阵分解模型md、可变形卷积和通道注意力模块构建多尺度特征融合模块mdff;
18、s2.2基于mdff设计多尺度特征融合网络;
19、将主干网络四个阶段提取到的不同尺度的特征图f1、f2、f3、f4上采样到同一分辨率再将四个特征图在通道维度上级联并通过mdff模块进行特征融合,最终得到融合后的特征图φ,特征图φ用于后续各任务分支。
20、进一步,所述步骤s2.2中,特征图φ的大小为
21、进一步,所述步骤s3包括以下子步骤:
22、s3.1输入当前帧的检测结果和历史跟踪轨迹集,使用giou计算两者之间的运动相似度进行匹配;
23、轨迹匹配成功,更新轨迹的外观特征、边界框信息和目标id信息,并存入历史跟踪轨迹集中;轨迹未匹配成功,保留轨迹,存入失活跟踪轨迹集中,存活周期设置为60帧;
24、s3.2使用giou计算未匹配成功的检测结果和失活的轨迹与历史跟踪轨迹的运动相似度,从而对失活的轨迹进行重识别匹配;
25、轨迹匹配成功,更新轨迹的外观特征、边界框信息和目标id信息,将轨迹从失活跟踪轨迹集中取出存入历史跟踪轨迹集;轨迹未匹配成功,仍保留在失活跟踪轨迹集中;
26、s3.3对于还未匹配成功的检测结果和失活的轨迹再次进行外观特征上的重识别匹配,计算两者外观特征的余弦距离,从而对失活的轨迹进行重识别匹配;
27、轨迹匹配成功,更新轨迹的外观特征、边界框信息和目标id信息,将轨迹从失活跟踪轨迹集中取出存入历史跟踪轨迹集;轨迹未匹配成功,仍保留在失活跟踪轨迹集中;
28、s3.4对于最终还未匹配成功的检测,进行轨迹初始化;对于失活的轨迹,存在周期超过60帧的丢弃,存在周期60帧以内的继续保留在失活跟踪轨迹集中。
29、进一步,所述步骤s4包括以下子步骤:
30、s4.1将从训练集获取的视频序列的当前帧图像、前一帧图像,以及网络得到的历史跟踪结果作为网络的输入;
31、s4.2生成当前帧图像中心点热图、偏移向量和边界框回归特征图作为真实输出;
32、s4.3根据跟踪模型的预测输出与真输出计算出模型的损失值,使用adam优化器,在训练集上训练150个epoch,得到并保存跟踪模型的权重。
33、进一步,所述步骤s5包括以下子步骤:
34、s5.1使用设计的车辆目标跟踪模型,加载步骤s4得到的模型权重;
35、s5.2对输入的监控视频流数据,使用加载权重的车辆目标跟踪模型逐帧跟踪车辆目标。
36、本发明的有益效果在于:
37、本发明从实际交通场景监控视频出发,在联合检测跟踪框架transcenter的基础上,针对原模型主干网络忽略了特征在通道维度的适应性,以及对特征局部信息利用较少,难以有效提取特征的问题,基于多分支大核卷积注意力模块ms-lkca重新设计了主干网络,提升了特征提取能力;针对原模型特征融合网络容易出现特征语义信息流失的问题,设计了多尺度特征融模块mdff,提升融合后特征的质量,从而增强特征对目标的表征能力;针对车辆目标之间频繁的遮挡导致目标丢失以及目标id跳变等问题,提出了一种基于多特征的多级匹配方法;最终形成一套完整的车辆目标跟踪方法,该方法能够有效降低因目标遮挡、目标相似、目标尺度快速变换等因素造成的车辆目标跟踪漂移和跟踪丢失,提高跟踪的准确度和稳定性。
38、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究,对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!