一种基于跨度级别和对抗训练的双向情感三元组抽取方法与流程
本发明属于情感分析,具体涉及一种基于跨度级别和对抗训练的双向情感三元组抽取方法。
背景技术:
1、情感分析是自然语言处理中的一个重要任务,其目标是从文本中自动识别出表达的情感倾向,通常分为正面、负面和中性三种情感类别。近年来,研究人员逐渐意识到情感分析的应用不仅限于文本分类,还可以扩展到更多实际场景中,如观点挖掘、舆情分析、电商广告推荐等。
2、方面级情感分析是情感分析的一种变体,其目标是从文本中抽取出对应实体(即方面术语)的情感极性,例如对于一条餐厅评论“菜品很好吃,但服务不太友好”,方面级情感分析可以抽取出“菜品”这个方面的情感极性为积极,而“服务”这个方面的情感极性为消极。方面级情感分析在电商、旅游、餐饮等领域有广泛的应用,可以帮助企业和电商平台等更好地了解消费者的需求和反馈,提高产品和服务质量。
3、然而,之前的方面级情感分析研究并没有试图一次性提供一个完整的解决方案,于是文献[peng h,xu l,bing l,et al.knowing what,how and why:a near completesolution for aspect-based sentiment analysis[c]//proceedings of the aaaiconference on artificial intelligence.2020,34(05):8600-8607]提出了方面级情感三元组抽取任务,这个任务的求解器要从输入中提取三元组(方面术语、情感极性,观点术语),这表明目标方面术语是什么,他们的情绪极性是如何的,以及为什么他们有这样的极性(即观点术语)。例如“菜品很好吃,但服务不太友好”中的两个三元组可以是(菜品、积极的、好吃)、(服务、消极的、不太友好),通过抽取出文本中的情感三元组,可以有效地解决方面级情感分析的问题。该文献中同时给出了一个流水线模型:第一阶段通过联合标记抽取候选方面术语、情感极性及观点词;第二阶段将模型输出的方面术语和观点术语进行配对,根据文本信息以及方面术语和观点术语之间的距离信息通过分类器来确定哪些是有效的组合。自该文献首次一次性给出方面级情感分析三元组的解决方案后,该方向就引起一些研究者的重视。
4、文献[xu l,li h,lu w,et al.position-aware tagging for aspect sentimenttriplet extraction[j].arxiv preprint arxiv:2010.02609,2020]首次采用端到端的方式,提出了新颖的位置感知标记方案,捕捉每个单词在三元组中的位置,他们编码情感极性以及方面术语的开始位置与观点术语的起始位置之间的距离信息,该方案能够指定三元组的结构信息,通过标签语义来实现三元组中三个元素之间的连接。端对端的模型可以提升三元组抽取的效果,但是这些模型依赖于每个方面术语和观点术语之间的互相作用来判断整体的情感极性,在方面术语或观点术语包含多个单词的三元组上,这些端对端的模型不能完整的识别词组之间的联系,影响了模型的性能。文献[xu l,chia y k,bingl.learning span-level interactions for aspect sentiment triplet extraction[j].arxiv preprint arxiv:2107.12214,2021]考虑到方面术语和观点术语可能由多个单词组成,提出了一种基于跨度的aste模型(span aste),该模型首次在预测方面词和观点词对的情感关系时直接捕获跨度到跨度的交互,在执行三元组抽取时明确考虑了方面术语和观点术语的整体词组之间的相互作用,从而确保了情感极性的一致性。同时,为了降低词组枚举导致的高计算成本,该文献还提出了一种双通道词组剪枝策略,其结合了方面术语抽取(ate)和观点术语抽取(ote)两个任务的监督,在最大程度上将有效方面术语和候选观点术语配对在一起。
5、文献[wu z,ying c,zhao f,et al.grid tagging scheme for aspect-orientedfine-grained opinion extraction[j].arxiv preprint arxiv:2010.04640,2020]提出一种网格标记方案(grid tagging scheme,gts),通过一个统一的网格标记任务以端到端的方式处理方面级情感三元组抽取任务,并且针对不同观点术语之间潜在的相互指示,设计了一种有效的gts推理策略,利用它们进行更精确的提取情感三元组。
6、综上分析,方面级情感三元组抽取技术是一种从文本中提取情感信息的方法,通常包括方面术语、情感极性和观点术语,虽然该技术在自然语言处理领域已经得到了广泛的应用,但仍然存在一些缺点,包括:
7、1.现有的流水线形式的模型通常分为两个阶段:在第一个阶段抽取文本中所有可能的方面术语和意见术语,并且预测方面术语的情感极性;第二阶段对第一阶段输出的带情感极性的方面术语和观点术语,根据方面术语和观点术语在词嵌入空间的距离信息,通过分类器来进行配对。这类模型的缺点是将aste任务割裂开来,忽略了文本的上下文语义层面的关系,因此效果不佳,并且这类模型的输出是由各个子任务的输出串联而成,如果在某一个子任务中出现错误,后续任务将无法纠正这个错误,出现误差传递问题,导致整个模型的性能下降。
8、2.大多数模型基于令牌(以下统称token)的词级交互,没有充分利用跨度级别信息,这些方法只关注单个词与词之间的相互作用,将多词术语视为一个个独立的词,从而在面对多词方面、观点术语时分离了跨度的语义信息,在提取三元组时难以保证情感一致性。
9、3.与token级方法不同,跨度级方法虽然可以考虑到多词术语间的上下文语义联系,但是其模型的输入不能保证跨度之间互斥,例如在句子“the corned beef was tenderand melted in my mouth”中,类似的跨度beef、corned beef和the corned beef可能会在下游任务中引起混淆;因此,对于跨度级别的模型来说,有效地区分这些相似的跨度是一个关键性的难题。
10、4.受限于数据量和质量,情感三元组抽取技术通常需要大量的标注数据来训练模型,但获取高质量的标注数据是一项昂贵和耗时的工作;此外,训练数据的规模和质量可能会影响情感三元组抽取技术的鲁棒性和泛化能力。
技术实现思路
1、鉴于上述,本发明提供了一种基于跨度级别和对抗训练的双向情感三元组抽取方法,端到端地处理情感三元组抽取任务,避免了训练过程中的误差传递问题,充分利用跨度级别的信息,可以有效解决token级别方法忽略多词方面、观点术语的语义信息问题。
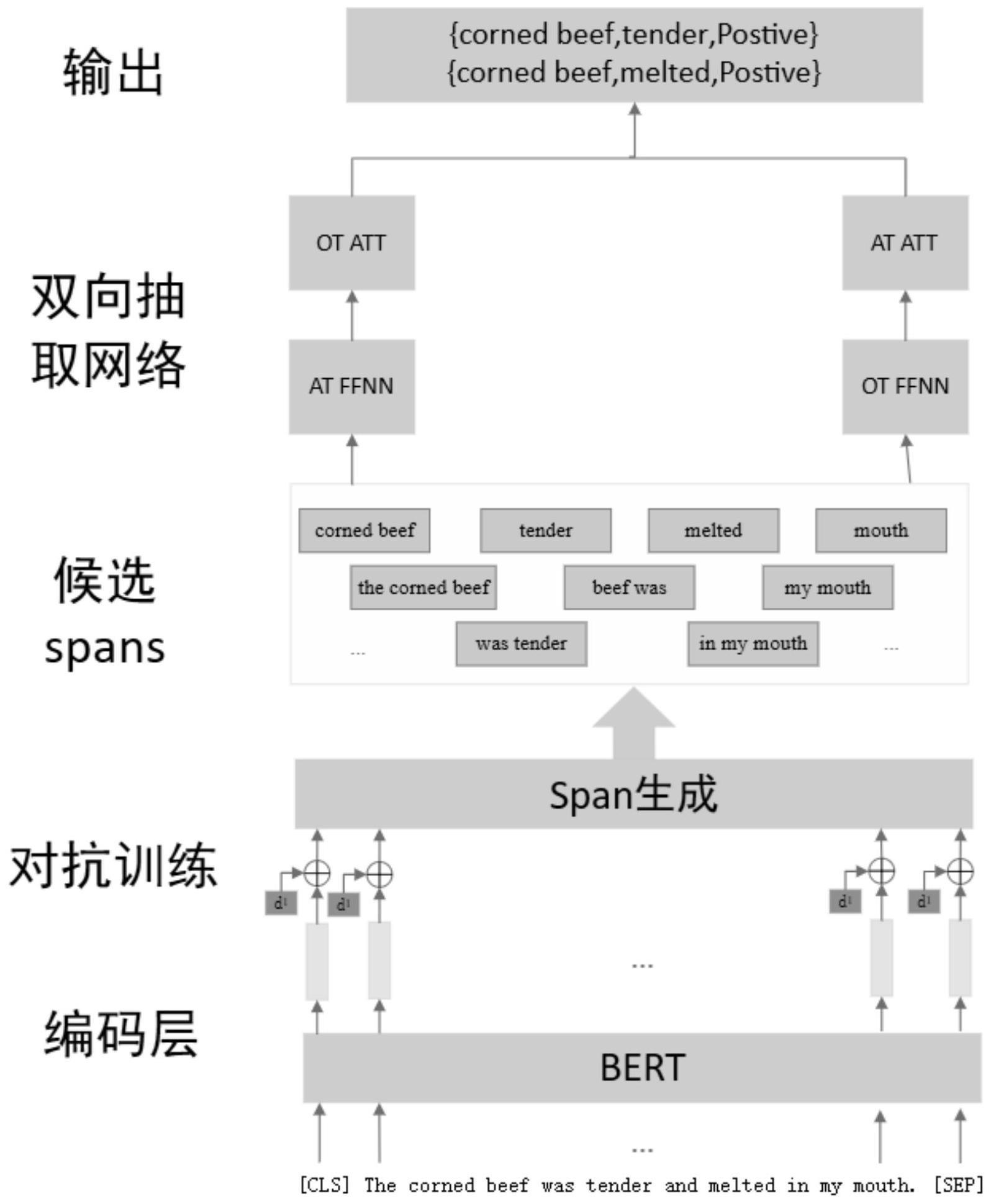
2、一种基于跨度级别和对抗训练的双向情感三元组抽取方法,通过模型实现,整个模型包括编码层、embedding层、span生成模块以及双向解码器;所述双向情感三元组抽取方法包括如下步骤:
3、(1)通过编码层提取输入句子的词嵌入特征向量;
4、(2)针对embedding层加入对抗训练;
5、(3)从输入句子中生成跨度并分离相似跨度;
6、(4)利用双向解码器对跨度进行解码得到三元组。
7、进一步地,所述三元组包括方面术语、意见术语以及两者之间的情感极性,方面术语对应为一项实体。
8、进一步地,所述步骤(1)的具体实现方式为:首先在输入句子开头和末尾分别添加标注cls和sep,然后利用tokenizer对输入句子进行分词处理得到句子的单词序列,进而将单词序列输入至bert(bidirectional encoder representations from transformers)模型中得到单词的上下文嵌入表示作为输入句子的词嵌入特征向量。
9、进一步地,所述bert模型采用bert-base-uncased,其隐藏层为12层,嵌入层维度为768。
10、进一步地,所述步骤(2)的具体实现方式为:首先在词嵌入特征向量中添加细微扰动并作为embedding层的输入,然后采用fgm对抗训练算法对模型进行对抗训练。
11、进一步地,所述步骤(3)的具体实现方式为:首先设定一个合适的跨度大小m,从输入句子中枚举所有长度不超过m的跨度(即文本片段),然后根据词嵌入特征向量生成这些跨度的数学表达,并在模型训练过程中采用均方误差损失函数来分离相似跨度。
12、进一步地,所述跨度的数学表达如下:
13、pmaxpooling(hstart,hstart+1,...,hend)
14、endstart≤m
15、其中:p表示输入句子中的某一跨度,start和end分别为跨度p中起始单词和末尾单词的索引号,hstart和hend分别为词嵌入特征向量中对应下标索引号的特征值,maxpooling()表示最大池化。
16、进一步地,所述步骤(4)的具体实现方式为:使用双向解码器对跨度进行解码,在方面术语到意见术语抽取方向上,首先采用前馈神经网络提取输入句子中的所有方面术语及其情感极性概率;然后,利用解码器识别每个方面术语的所有意见术语及其情感极性,进而计算出意见术语的情感极性概率;最后将方面术语和意见术语的情感极性概率转换为置信度,并根据置信度激活句子中的三元组;在意见术语到方面术语抽取方向上,首先采用前馈神经网络提取输入句子中的所有意见术语及其情感极性概率;然后,利用解码器识别每个意见术语的所有方面术语及其情感极性,进而计算出方面术语的情感极性概率;最后将方面术语和意见术语的情感极性概率转换为置信度,并根据置信度激活句子中的三元组;在训练过程中双向解码器使用交叉熵损失函数。
17、基于上述技术方案,本发明具有以下有益技术效果:
18、1.本发明基于跨度级别的端到端抽取方式,避免了流水线方式的误差传播。
19、2.本发明使用fgm对抗训练的方法,针对模型的embedding层,添加对抗样本,提高了模型的鲁棒性和泛化性。
20、3.本发明能够处理跨越多个词的方面术语或意见术语,将方面术语或意见术语的整个片段作为预测目标从而获得更全面的上下文信息,使得模型能够更准确地理解文本中的含义,从而提高了模型的准确性。
21、4.本发明通过双向解码器联合提取情感三元组,其提取中使用双仿射分类器解析依赖关系,提高了模型的准确性。
- 还没有人留言评论。精彩留言会获得点赞!