一种基于句法结构删减的自动文摘事实性增强方法
本发明涉及大数据资源服务、数据挖掘,具体涉及一种基于句法结构删减的自动文摘事实性增强方法。
背景技术:
1、自动文摘技术可以自动化地对文章内容进行总结和压缩,在保留原文关键信息的基础上生成更小规模的摘要文本。近些年来,随着人工智能技术的快速发展,生成摘要文本在流畅性与概括能力上都得到了显著的提升,但是仍存在一个显著问题,即事实准确性问题。
2、自动文摘模型的事实准确问题是指摘要文本与原文存在事实不一致的情况。据统计,生成式摘要模型产生的摘要结果中至少有30%存在事实错误,这严重地影响到了生成式摘要模型在实际场景中的应用。事实错误不但出现频率高,表现形式也颇为繁多,研究者们简单地将错误类型进行了归纳,具体类型及说明如下表1,在参考文献1(pagnoni a,balachandran v,tsvetkov y.understanding factuality in abstractivesummarization with frank:a benchmark for factuality metrics.arxiv preprintarxiv:2104.13346.2021apr 27)记载。
3、表1事实准确性错误的分类
4、
5、事实准确性问题的研究主要有两大方向,一是对摘要事实准确性的评估,二是对于事实准确性问题的改善。摘要事实准确性评估模型有多种实现方式,有基于数据增强方法构建的数据集训练实现,也有基于文本蕴含模型、依存关系分析或问答模型实现,各个评价模型对于不同错误类型的敏感程度也有所不同。对于事实准确性问题的改善包括对于模型训练数据的清洗与纠正,对于模型结构的改进,以及对于生成摘要的后纠错。其中后纠错方法能直接适用于不同实现形式的自动文摘模型,具有极高的通用性,近些年越来越受到人们的重视。
6、后纠错模型以可能带有事实错误的摘要文本作为输入,在参考原文的基础上,输出事实错误被纠正的摘要。常见的后纠错模型都是基于transformer结构的序列到序列模型,不同模型之间的区别主要在于训练数据的差异。序列到序列的后纠错模型的训练数据由错误摘要、纠正后摘要、参考原文三个部分组成。由于事实性错误种类繁多,且较为隐蔽,人工标注成本极高,因此后纠错模型训练数据集的构建往往需要使用数据增强的方法。但是受限于数据增强方法生成的错误摘要与真实存在的错误摘要之间的差异,这类后纠错模型在真实场景中表现不稳定。还有一类后纠错模型是对摘要文本的语法结构进行微调。例如通过问答模型,检查摘要文本中的实体词,并将不正确的实体词替换。这类后纠错模型具有较强的稳定性与可解释性,但是前人的工作中由于纠错手段单一,能应对的错误类型有限,还具有很大的提高空间。
7、上述两类后纠错模型存在共同的缺陷,即纠错手段单一,能应对的错误类型有限。纠错手段单一是指仅使用替换作为主要纠错手段,序列到序列纠错模型虽然并不涉及具体的语法结构调整,但是由于训练数据构建过程中,错误摘要往往是通过替换原有摘要的语法结构得到,因此仅从结果上看,替换操作是其最常使用的纠错手段。应对错误类型有限是指仅以实体词作为纠错对象,这仅能覆盖一小部分错误类型,经过统计,在22.5%的错误摘要中甚至不含有可以被识别的实体词。
8、表2不包含可识别实体摘要句数量统计
9、 数据集 摘要句总数 未包含可识别实体摘要句数量 占比 frank(cnn/dm部分) 3915 921 23.5% frank(xsum部分) 1027 192 18.7% frank 4842 1113 22.5%
10、frank数据集是一个基于真实摘要模型产生的错误人为标注的数据集,其中包含由9个摘要系统产生的2250条摘要数据。该数据集除了简单地给出摘要中是否包含事实错误外,还注明了错误的类型,方便研究者进行后续的进一步筛选与实验。frank(cnn/dm部分)与frank(xsum部分)是frank数据集中按照原文数据来源不同抽样构建的两个部分。
11、目前,在使用后纠错方式提高事实准确性的工作中,zhu等人在2020年最先尝试通过实体替换等数据增强方式构建训练数据,训练bart模型直接输出纠正后的摘要,但是使用这种方式生成的训练数据与真实存在的错误摘要之间存在差距,因此该纠错模型对于真实环境下的错误摘要纠错效果不佳。balachandran等人在2022年通过填空模型改进了数据增强方式,这样生成的错误摘要与真实错误摘要更加接近,但是受限于训练数据,训练出来的模型仍只能使用实体替换作为主要纠错手段。fabbri等人在2022年通过文本简化模型构建出来的训练数据集进一步优化了纠错模型的效果,训练出来的模型能删减一些错误内容,但是依旧只能识别实体上的错误。
12、除此之外,也有一些后纠错方法借助已有的自然语言处理技术直接对摘要文本进行调整。例如dong等人在2020年使用问答模型检查并纠正摘要中的错误实体(参考文献2:dong y,wang s,gan z,et al.multi-fact correction in abstractive textsummarization[j].arxiv preprint arxiv:2010.02443,2020.),chen等人在2021年通过替换摘要中的实体生成候选摘要,并从候选摘要中选出事实性最佳的摘要(参考文献3:chen s,zhang f,sone k,et al.improving faithfulness in abstractivesummarization with contrast candidate generation and selection[j].arxivpreprint arxiv:2104.09061,2021.)。但这些方法同样也存在纠错范围上的限制,仅能使用实体替换作为主要纠错手段。
技术实现思路
1、本发明针对现有纠错模型的纠错效果不佳、纠错手段主要仅为实体替换等问题,提出一种基于句法结构删减的自动文摘事实性增强方法,通过采用后纠错的形式对文摘中可能存在的事实错误进行修正,构建语法依存树指导删减操作的进行,以提高模型生成摘要的事实准确性,并适用于各种已有的摘要模型,具有极高的通用性。
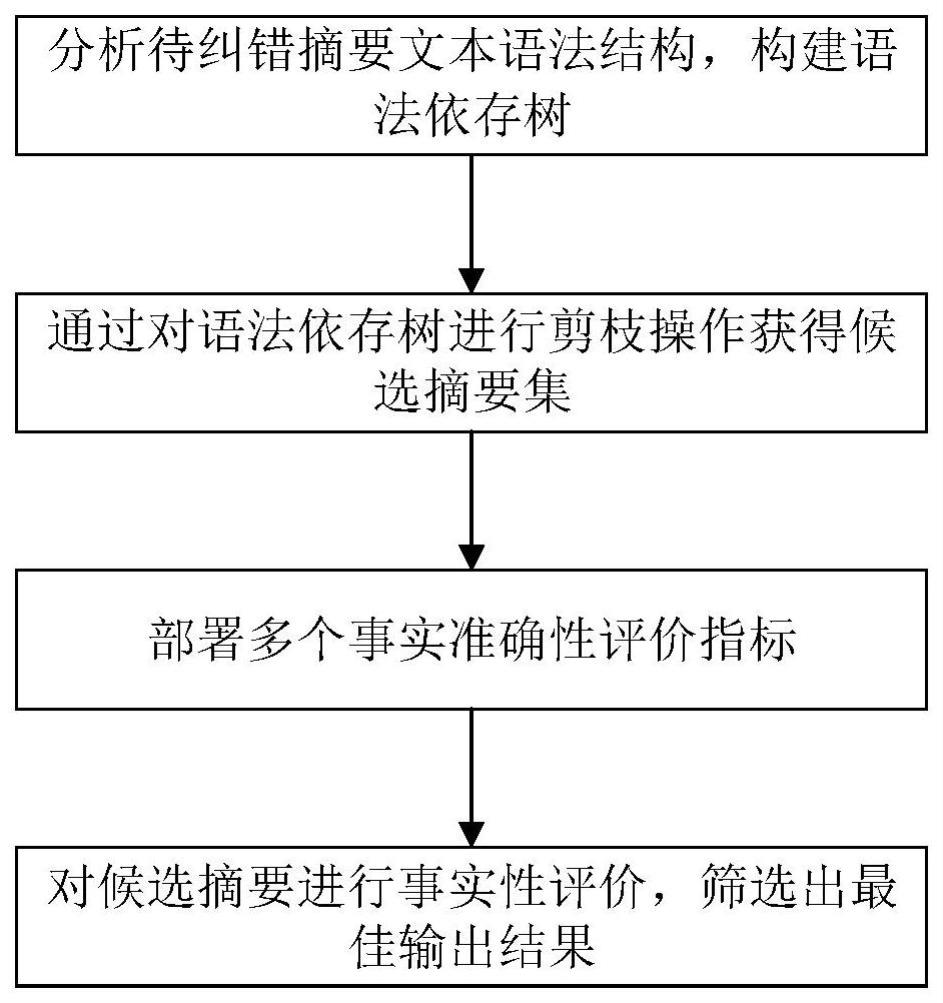
2、本发明的一种基于句法结构删减的自动文摘事实性增强方法,包括如下步骤:
3、步骤1:将待纠错摘要文本输入语法依存树构建模块,语法依存树构建模块分析待纠错摘要文本语法结构,输出摘要文本对应的语法依存树。
4、语法依存树中记录摘要文本中单词之间的语法依存关系。
5、步骤2:剪枝模块对语法依存树进行剪枝操作,获得候选摘要集。
6、预先将语法依存关系分类,分为三类:第一类语法依存关系所引导的子树能直接删减;第二类语法依存关系所引导的子树能删减,但要核查删减后的文本语法准确性,若语法出现错误则不能删减子树;第三类语法依存关系所引导的子树不能删减。
7、剪枝模块对语法依存树进行后序遍历,依次访问每个子树,判断引导子树的节点与该节点的父节点间的语法依存关系类型,对于属于第一类和第二类的语法依存关系,则尝试剪枝该节点引导的子树,若能删减子树,生成一个删减子树后的候选摘要;在后续遍历过程中,先将被剪枝的子树还原,然后继续按序访问下一个子树,尝试剪枝子树,生成候选摘要;在对语法依存树遍历完成后,获得一个候选摘要集。
8、步骤3:预先在服务器部署多个事实评价指标模型。
9、将每个事实评价指标模型的实现进行封装并统一调用形式,部署在服务器并开放调用接口。
10、步骤4:最佳摘要输出模块实时调用服务器上多个事实评价指标模型,对候选摘要集中的每个候选摘要及原始摘要进行事实性评价,根据评价结果输出最佳摘要。
11、相对于现有技术,本发明方法的优势在于:
12、(1)本发明方法是第一次将语法结构删减应用于后纠错的方案。事实错误种类多样,但是错误产生的具体原因归结而言是含有事实错误的语法结构或语法结构之间的错误搭配。前人的方法仅采用实体替换作为纠错的主要手段,这仅能应对一小部分错误类型。本发明方法引入语法结构删减这一纠错手段,从本质上更加贴近错误产生的原因,极大地增加了纠错方法能应对的错误类型。
13、(2)本发明方法使用语法依存树辅助完成句法结构的删减。句法结构的删减不是直接通过序列到序列模型生成,而是通过对语法依存树剪枝实现。本发明基于剪枝操作的句法结构删减,在保证语法准确性的同时,具有更好的可解释性,同时使用这种方式生成的候选摘要集也更加完整。
14、(3)本发明方法部署并封装了多个事实评价指标。不同于在代码运行的过程中载入事实评价模型,本发明方法在使用事实评价指标时,先完成评价指标的部署,再通过调用接口的形式使用评价指标。通过这种方式能够避免不同评价指标依赖环境版本不同造成的冲突,提高代码调用的便捷程度以及执行效率。
15、(4)本发明方法综合各个评价指标的优势来筛选最佳摘要。前人参考事实评分结果进行摘要句的筛选或修改时,往往仅使用单个指标作为参考依据。单个指标存在对于特定错误类型不敏感的问题。本发明通过结合多个实现原理不同的评价指标,能弥补这一缺陷,使得评价结果更加稳定与全面。在此基础上选择出来的修改后摘要,在事实性上更有保证。并且本发明方法所应用的纠错模型的纠错性能还可以随着评价指标的优化而进一步优化。
16、(5)本发明方法通过构建语法依存树指导删减操作,保证了候选摘要集的完整性以及候选摘要的语法准确性;在选取事实准确性最高的摘要作为纠错结果的过程中,应用了多种事实评价指标,通过综合多个指标评价的结果,回避了单个指标对特定类型错误不敏感的问题,保证了纠错效果的稳定性。本发明方法适用于后纠错方式,可以提高自动文摘模型生成摘要的事实准确性,能广泛地作用于已有的自动文摘模型中,不受到自动文摘模型实现方式的限制。
17、(6)本发明方法使用语法结构的删减作为主要纠错手段,弥补了之前后纠错方法在纠错对象与纠错形式上的不足,极大地扩充了可以应对的错误范围。本发明方法可以与之前各类提高事实准确性方法共同作用,进一步提高事实准确性。
- 还没有人留言评论。精彩留言会获得点赞!