基于声音AI模型的虚拟场景生成方法及系统
本发明属于人工智能的教学应用领域,更具体地,涉及基于声音ai模型的虚拟场景生成方法及系统。
背景技术:
1、aigc可根据师生的需求和课程内容,利用人工智能(artificial intelligence,ai)技术自动化生成高质量、个性化的教学资源,为师生提供更好的学习体验。将aigc技术应用于虚拟场景的生成,能够生成逼真的教学情境,为教育元宇宙中学习者提供与学习目标适切的丰富教学资源。利用ai、深度学习等算法构建的声音ai模型在语音处理、声音分析、智能交互等领域作用非常广泛,如通过声音特征识别不同的说话者,也可通过识别说话人声音的音调、语速、语气等特征,判断其情绪状态。在aigc中引入声音ai模型,可为教育元宇宙中虚拟教学场景创设提供了一种新的路径。然而,目前使用声音ai模型生成虚拟场景大多仅使用直接音频数据,且未经过信号增强处理,导致经过媒介反射的混响数据利用效率较低,与环境相关的声音特征未得到充分利用。因此,通过采集、增强多源音频数据,采用ai技术提取声音特征,构建声音ai模型,提取教学环境中师生的声纹、环境轮廓特征,匹配教学空间的模型库,识别、分割、生成教学环境中对象,并聚合环境模型和师生主体。将生成式ai技术应用于教学资源和教学场景的生成,可为教学资源的供给提供自动化、智能化的生成方式。
2、当前基于声音ai模型的虚拟场景生成领域还存在诸多的问题:(1)虚拟场景生成未充分考虑教学环境反射所形成的混响音频数据:仅使用师生对话的直接音频数据难以分析、理解师生所处真实教学环境的概貌;(2)多源音频的特征提取的手段还不丰富:由于多源音频数据的非线性和非平稳性特点,直接使用未经信号增强处理的音频数据难以充分挖掘其隐含特征,可能导致关键信息在特征提取过程中丢失或模糊;(3)虚拟教学环境对象分割尚未自动化、智能化:根据声音特征可生成虚拟教学环境轮廓,缺乏使用3d场景库匹配、分割,智能化创设虚拟教学场景和教学主体的能力。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于声音ai模型的虚拟场景生成方法及系统,为教育元宇宙中虚拟场景生成提供一种智能、系统的方法。
2、本发明的目的是通过以下技术措施实现的。
3、本发明提供一种基于声音ai模型的虚拟场景生成方法,该方法包括以下步骤:
4、(1)多源音频数据采集,采用vr终端内置麦克风录制师生授课、提问、问答的直接音频数据,捕捉经过介质反射传播的混响音频数据;运用模数转换算法将音频信号转换为数字信号,经过预加重、分帧、端点检查和加窗处理;采用基于感知编码的音频压缩算法编码音频帧,存储为acc音频文件格式;
5、(2)声音特征提取,运用声学变换以及时间和频率掩蔽算法处理、增强直接和混响音频信号;采用伽玛通滤波器组处理时频图,使用对数变换运算处理每个滤波器组输出结果,提取师生音频特征;运用残差神经网络层提取教学环境的特征向量;
6、(3)声音ai模型学习,依次堆叠cnn-bilstm模型、fftblock模块,构造声音ai模型;使用随机初始化剪枝算法剔除敏感度低的神经元,采用xavier算法初始化模型中权重和阈值训练参数;采用自适应学习率算法作为优化器,设置多种模型超参数,训练声音ai模型;
7、(4)教学环境轮廓识别,使用已训练的声音ai模型,提取混响信号特征;采用edter算法,设置不同属性对声音反射的影响系数,生成教学环境的形状、纹理、深度和运动信息边缘特征向量;依次使用efficientnet、shufflenet和wide-resnet神经网络层,提取教学环境轮廓的特征;
8、(5)师生状态识别,依次堆叠声音ai模型和嵌入声纹特征孪生残差网络,提取教学环境中师生的声纹特征;采用短时幅度差特征检测算法获取声纹特征的突变点和变化率,分割直接音频信号;使用时空网络提取师生的空间特征向量,采用定位算法,推断师生声源的空间信息;
9、(6)教学环境对象生成,采用基于pixel2mesh的三维重建算法,实现基于图像的人体3d模型生成;运用约束delaunay三角剖分算法生成轮廓点的三角网,平滑教学空间的轮廓;采用粒子群优化算法检索对象模型库,依据最优参数组合,使用立体视觉重建算法,生成环境对象;
10、(7)教学环境动态重构,依据声音ai模型推断教学环境的类别,使用基于生成对抗网络算法调整教学环境长和宽;使用基于空间分割的八叉树算法,重划虚拟教学环境的网格;结合碰撞检测和场景约束布局算法设置网格的尺寸,放置对象和化身到对应网格,聚合虚拟环境中教学主体和教学模型。
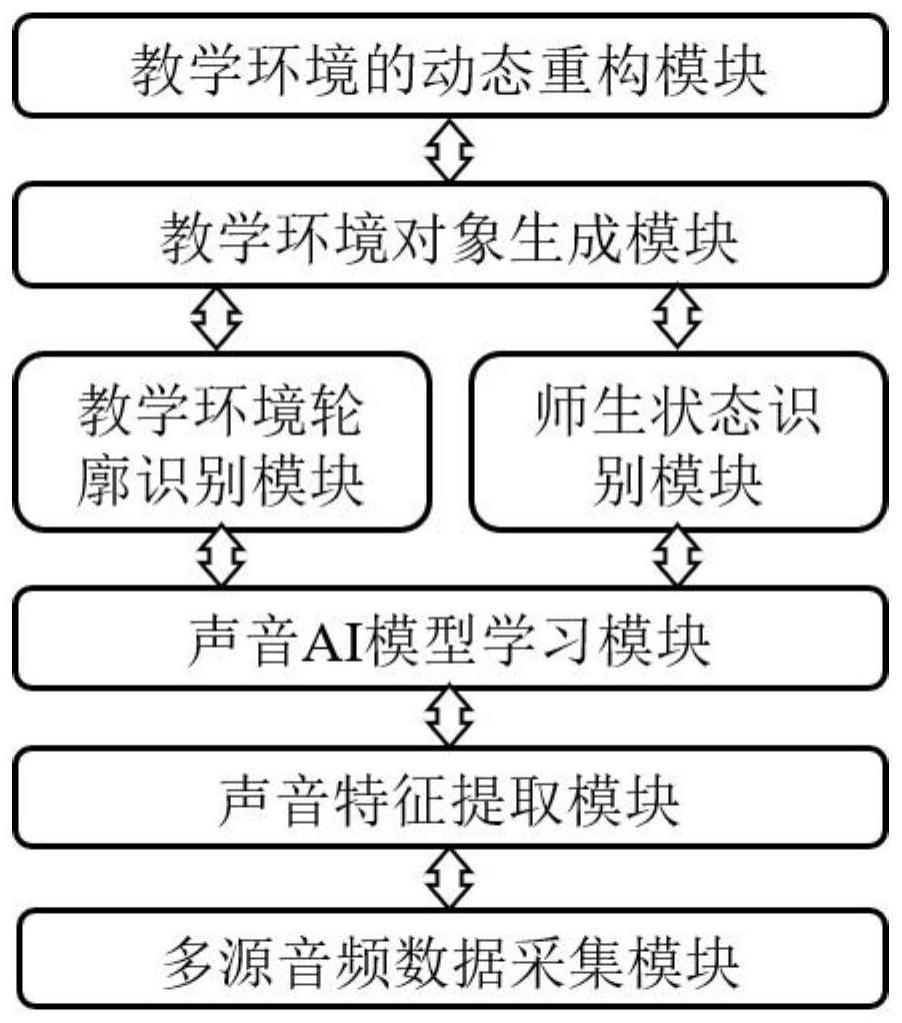
11、本发明还提供一种基于声音ai模型的虚拟场景生成系统,用于实现上述的方法,包括多源音频数据采集模块、声音特征提取模块、声音ai模型学习模块、教学环境轮廓识别模块、师生状态识别模块、教学环境对象生成模块和教学环境动态重构模块。
12、所述多源音频数据采集模块,用于录制师生授课、提问、问答的直接音频数据,捕捉经过介质反射传播的混响音频数据,将音频信号转换为数字信号,采用音频压缩算法编码音频帧。
13、所述声音特征提取模块,用于增强音频信号,使用对数变换运算处理滤波器组输出的结果并提取师生音频特征,运用残差神经网络层提取环境特征向量。
14、所述声音ai模型学习模块,用于堆叠cnn-bilstm和fftblock模块,构造声音ai模型,剔除敏感度低的神经元,采用xavier算法初始化训练参数,设置模型超参数,训练声音ai模型。
15、所述教学环境轮廓识别模块,用于使用声音ai模型提取混响信号特征,采用edter算法生成环境边缘特征向量,使用神经网络层提取教学环境轮廓的特征。
16、所述师生状态识别模块,用于提取教学环境中师生交流的声纹特征,获取声纹的突变点和变化率,分割直接音频信号,采用定位算法推断师生声源的空间信息。
17、所述教学环境对象生成模块,用于生成图像的人体3d模型,运用约束deluanay三角网平滑教学空间的轮廓,依据最优参数组合,生成环境对象。
18、所述教学环境动态重构模块,用于调整教学环境的长、宽参数,使用八叉树算法划分教学环境为网格,运用碰撞检测和场景约束布局算法设置网格尺寸,在虚拟环境中聚合教学主体和教学模型。
19、本发明的有益效果在于:采用vr终端内置麦克风录制师生授课、提问、问答的直接音频数据,捕捉经过介质反射传播的混响音频数据;运用模数转换算法将音频信号转换为数字信号,经过预加重、分帧、端点检查和加窗处理;采用感知编码的音频压缩算法编码音频帧,存储为acc音频文件格式;运用声学变换算法处理、增强直接和混响音频信号;采用伽玛通滤波器组处理时频图,使用对数变换运算处理每个滤波器组输出结果,提取师生音频特征;运用残差神经网络层提取环境的特征向量;依次堆叠cnn-bilstm模型、fftblock模块,构造声音ai模型;使用随机初始化剪枝算法剔除敏感度低的神经元,采用xavier算法初始化模型中的权重和阈值训练参数;采用自适应学习率算法作为优化器,设置多种模型超参数,训练声音ai模型;使用已训练的声音ai模型,提取混响信号特征;采用edter算法,设置不同属性对声音反射的影响系数,生成教学环境的形状、纹理、深度和运动信息边缘特征向量;依次使用efficientnet、shufflenet和wide-resnet神经网络层,提取教学环境轮廓的特征;依次堆叠声音ai模型和嵌入声纹特征孪生残差网络,提取教学环境中师生的声纹特征;采用短时幅度差特征检测算法获取声纹特征的突变点和变化率,分割直接音频信号;使用时空网络提取师生的空间特征向量,采用定位算法,推断师生声源的空间信息;采用基于pixel2mesh的三维重建算法,实现基于图像的人体3d模型生成;运用delaunay三角剖分算法生成轮廓点的三角网,平滑教学空间的轮廓;采用粒子群优化算法检索对象模型库,依据最优参数组合,使用立体视觉重建算法,生成环境对象;依据声音ai模型推断教学环境的类别,使用基于生成对抗网络算法调整教学环境长和宽;使用基于空间分割的八叉树算法,重划虚拟教学环境的网格;结合碰撞检测和场景约束布局算法设置网格的尺寸,放置对象和化身到对应网格,聚合虚拟环境中教学主体和教学模型。
- 还没有人留言评论。精彩留言会获得点赞!