基于深度学习的多摄像头视频图像拼接方法
本发明涉及计算,尤其涉及一种基于深度学习的多摄像头视频图像拼接方法。
背景技术:
1、图像拼接是将多张连续或有重叠部分的图像拼接成为一幅无缝的全景图或高分辨率图像的技术。目标检测技术是一种基于目标集合和统计特征得图像分割。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音的数据的解释有很大的帮助。三种技术大量运用于医疗病灶诊断成像,无人机航拍,自动驾驶,军事目标检测等。
2、传统的图像拼接流程是通过手动提取两张需要拼接图像中的对应特征点,计算得到一个能够完成图像平移、旋转、缩放和理想点变换的3×3大小的单应性矩阵,使用单应性矩阵对一张图像进行投影变换来和另外一张图像对齐,然后将对齐后的两张图像融合得到最终的全景图。但是传统方法学习特征和融合图像的能力有限,图像对齐效果并不佳,并且通过融合阶段最终得到的图片中往往有错位和鬼影的缺陷。
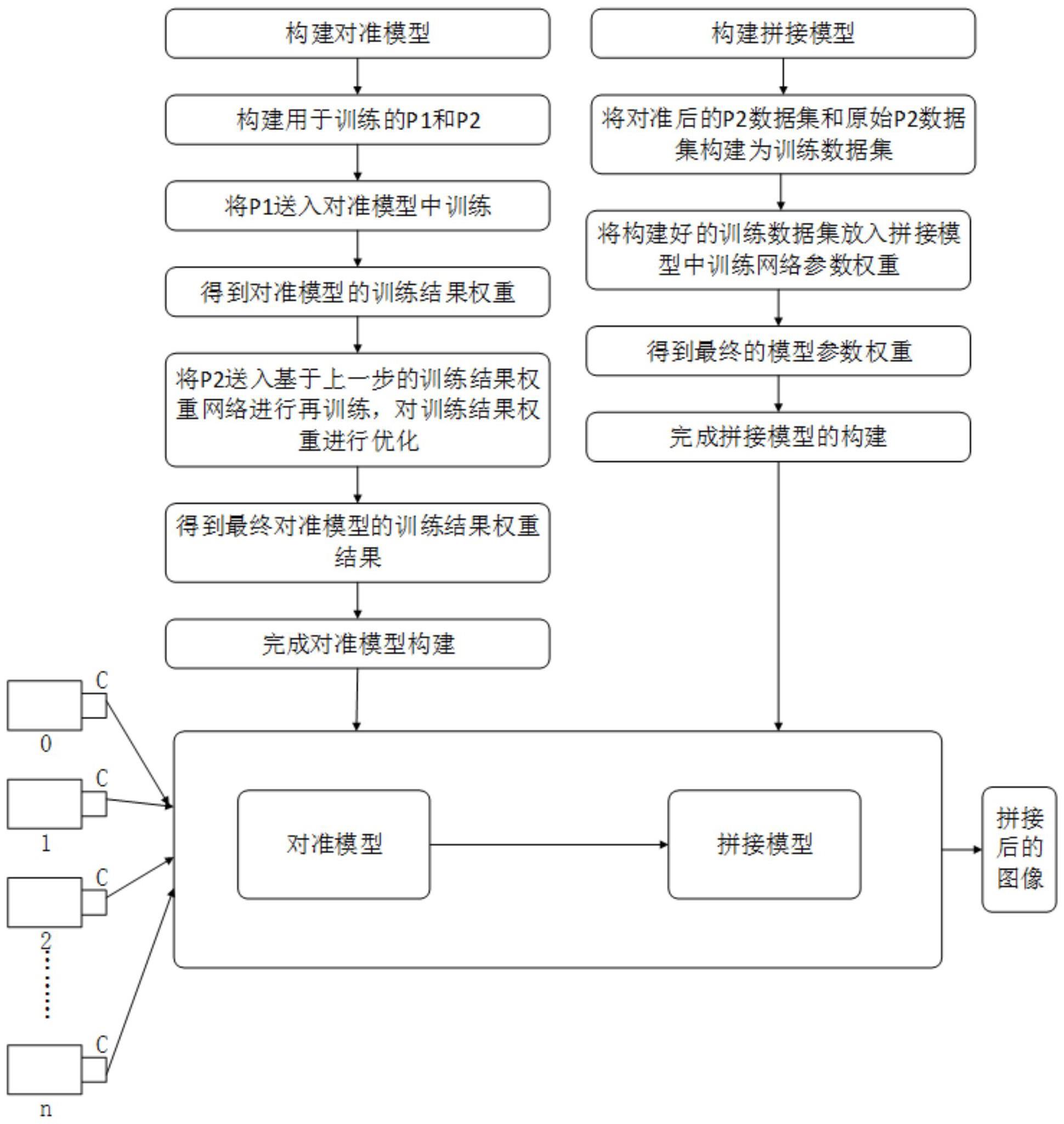
3、得益于深度学习技术强大的自动特征学习能力,基于神经网络的图像拼接方法已经成为主流。基于深度学习的图像拼接算法主要由两阶段组成,第一阶段是图像的对准,使用卷积神经网络提取需要拼接的两张图片对应的特征点,然后通过投影变换对准图像。第二阶段是图像的融合,将对准后的两张图片作为神经网络的输入,输出得到重叠区域过渡平滑的全景拼接图像。
4、对于目前多数基于深度学习的拼接算法,第一阶段使用的网络结构比较简单,参数量较大,训练和推理时间都很长。并且训练都是基于监督学习的方法,使用的训练图像是通过单应性变换人工自动生成的,和真实世界图像的多景深、多平面对齐任务存在偏差,并且对准的算法往往仅使用单个单应性矩阵对目标图像进行投影变换。以上要素都会导致最后图像对齐没有达到完美的效果,存在很大改进空间。在当前主流拼接算法的第二阶段中,往往通过对输出图像添加多项人工设计的损失函数来约束拼接图像的质量,这种做法难以使得拼接图像真正达到真实图像的纹理效果,融合得到的图像存在伪影和较为明显的拼接痕迹。
5、现有的基于深度学习的拼接算法的泛用性较低,并且都是两图片输入无法做到实时调整输入图像的数量做到多头输入。因此对于实际的应用场景还有很大的距离。
技术实现思路
1、本发明的目的就在于为了解决上述问题设计了一种基于深度学习的多摄像头视频图像拼接方法。
2、本发明通过以下技术方案来实现上述目的:
3、基于深度学习的多摄像头视频图像拼接方法,包括:
4、s1、构建对准模型和拼接模型,对准模型的输出作为拼接模型的输入,对准模型包括两个分支和 t个分析层,两个分支分别用于提取参考图像和目标图像的特征图,分析层用于分析网格顶点偏移量,每个分支包括第一卷积层和 t个特征提取层,第一卷积层和 t个特征提取层按照从输入到输出依次串联,两个分支的第 t个特征提取层的输出均作为第 t个分析层的输入,每个特征提取层从输入到输出依次包括第一自注意力机制模块和cps模块,每个分析层从输入到输出依次包括若干第二卷积层和回归网络,拼接模型包括对抗神经网络, t为小于或等于 t的正整数, t为大于1的正整数;
5、s2、获取训练集导入对准模型和拼接模型,对其进行训练优化,得到优化后的对准模型和优化后的拼接模型;
6、s3、获取同一时刻 k个摄像头的拍摄的视频帧, k为大于1的正整数;
7、s4、视频帧 k和视频帧 k+1导入优化后的对准模型和优化后的拼接模型进行图像拼接,获得拼接图, k为小于 k的正整数;
8、s5、判断 k+1是否等于 k,若是,则拼接图作为最终图像,并输出最终图像;若否,则令 k= k+1,然后令拼接图作为视频帧 k,并返回s4。
9、本发明的有益效果在于:读取每个摄像头中的视频帧,再将图片输入对准模型中进行对准,再将对准后的结果输入拼接模型进行拼接,在对准模型中引入了自注意力机制显著提高参考图像和目标图像中的特征提取效率和精度,为图像对准提供了更优的特征保障,在拼接模型中引入了自注意力机制显著提高参考图像和目标图像中的特征检测效率和精度,为图像拼接提供了更优的特征保障。拼接后的最终图像根据时间序列进行排序,再将这个时间序列的视频输入预训练好的目标检测神经网络模型中进行推理实现实时目标检测。
技术特征:
1.基于深度学习的多摄像头视频图像拼接方法,其特征在于,包括:
2.根据权利要求1所述的基于深度学习的多摄像头视频图像拼接方法,其特征在于,cps模块包括至少三个第一cbs层和第二cbs层,多个第一cbs层依次串联,第一自注意力机制模块的输出作为第一个第一cbs层和第二cbs层的输入,第一个第一cbs层和倒数第二个第一cbs层的输出均作为最后一个第一cbs层的输入。
3.根据权利要求1或2所述的基于深度学习的多摄像头视频图像拼接方法,其特征在于,对抗神经网络包括生成器和判别器,生成器的输出作为判别器的输入,生成器从输入到输出依次包括两层第三卷积层、第二自注意力机制模块、第四卷积层、第三自注意力机制模块和三层第五卷积层,判别器从输入到输出依次包括第六卷积层、第一全连接层、第四自注意力机制模块和第二全连接层。
4.根据权利要求1所述的基于深度学习的多摄像头视频图像拼接方法,其特征在于,在s2中,对准模型利用损失函数l进行训练优化,表示为,拼接模型的生成器利用损失函数进行训练优化,表示为,拼接模型的判别器利用损失函数进行训练优化,表示为,其中,ia表示目标图像,ib表示参考图像,hi(·)表示投影矩阵,e表示和图像形状大小相同的、全为1的矩阵,λi表示每个变换矩阵对应的损失权重,ʘ表示像素级乘法,‖·‖1表示一范数,γ表示合成标签,φ表示真实标签,pm表示真实图像m地分布,真实图像包括原始图像对,pz表示对准地目标图像和参考图像z地分布,d(·)表示判别器,g(·)表示生成器,ø表示判别器对生成数据输出的预测值地约束,n表示投影矩阵hi(·)的数量,z表示参考图像,m表示真实图像,表示计算的期望,表示真实图像m在经过判别器d(·)计算得出的标签值与真实标签φ做差再平方,表示计算 的期望,表示对准地目标图像和参考图像z在通过生成器和判别器后得出的标签值与合成标签做差再平方,通过将和相加得到拼接模型地判别器损失函数。
5.根据权利要求1所述的基于深度学习的多摄像头视频图像拼接方法,其特征在于,回归网络的回归拟合表示为,将上述等式进行展开得到x’=(ax+by+c)(gx+hy+i)和y’=(dx+ey+f)(gx+hy+i),其中,x、y为参考图像的像素点坐标,x’、y’为目标图像的像素点坐标,a、b、c、d、e、f、g、h、i分别为3*3的投影矩阵h的9个值,在回归网络中拟合最终得到投影矩阵h,表示为。
技术总结
本发明公开了基于深度学习的多摄像头视频图像拼接方法,包括S1构建对准模型和拼接模型,S2获取训练集导入对准模型和拼接模型,对其进行训练优化;S3获取同一时刻K个摄像头的拍摄的视频帧;S4图像拼接视频帧k和视频帧k+1,获得拼接图;S5判断k+1是否等于K,若是,则拼接图作为最终图像,并输出最终图像;反之,则令k=k+1,然后令拼接图作为视频帧k,并返回S4;读取每个摄像头中的视频帧,再将图片输入对准模型中进行对准,再将对准后的结果输入拼接模型进行拼接,对准模型中引入自注意力机制显著提高参考图像和目标图像中的特征提取效率和精度,拼接模型中引入自注意力机制显著提高参考图像和目标图像中的特征检测效率和精度。
技术研发人员:杨汶,杨智鹏,李露莹,李孝杰,朱辛
受保护的技术使用者:成都信息工程大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!