一种基于知识图谱的档案多模态智能编纂方法及系统与流程
本发明属于人工智能,具体涉及自然语言处理、计算机视觉、机器学习等相关技术,与信息科学、图像处理、文本挖掘、数据挖掘、大数据分析等领域密切相关,尤其涉及一种基于知识图谱的档案多模态智能编纂方法。
背景技术:
1、随着技术的不断发展,业务的类型及其数量的不断增加,档案的来源、类型及其数量也不断增加。目前企业档案数据的多样化、海量化,造成了档案数据的难以利用:档案数据利用成本高,需要付出大量的人力成本,耗时耗力,成本难以支撑;档案数据结构复杂、类型多样、来源广泛,通过文本、图像、视频、语音等多种不同类型的形式来进行存储和展示,难以从海量的档案数据中得到关键的档案知识,知识获取难且不全。同时,现存的档案数据中档案大部分为孤本,在开展利用服务时,容易丢失、失控、影响档案的寿命。档案编研工作海量档案数据关键信息人工提取方式落后,且效率低下,档案各主题编纂缺乏数字化、智能化手段支撑,档案作为企业的有价资料,无法得到更好的开发利用,且人工编纂素材收集整理难,过程中存在档案信息缺失、泄露等风险。
2、为了有效解决以上的这些问题,本研究提出了一种基于知识图谱的档案多模态智能编纂方法。通过结合人脸识别、ocr及其语音识别、视频关键帧抽取等相关技术来进行档案多模态关键信息抽取并对知识进行结构化,在此基础上实现档案智能编纂。档案智能编纂根据实际的档案业务主要划分为:关键信息抽取及其智能编纂两大阶段。在关键信息抽取阶段中,考虑到档案数据中数据类型多样,基于预先定义好的关键信息分别针对不同的数据类型采用了不同的关键信息抽取技术。在编纂阶段,基于档案业务需求,设计了多种档案主题模板及其档案抽取规则,并结合生成式模型,实现了档案多模态内容编纂。
技术实现思路
1、本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
2、鉴于上述现有存在的问题,提出了本发明。
3、因此,提供一种基于知识图谱的档案多模态智能编纂方法,旨在借助信息化技术,推动数智赋能档案事业转型升级,加强人工智能技术、大数据技术等新一代信息技术在档案智能化信息建设中的应用,注重档案非结构化资源的整合、数据挖掘、知识关联和知识服务,深化理论实践研究。
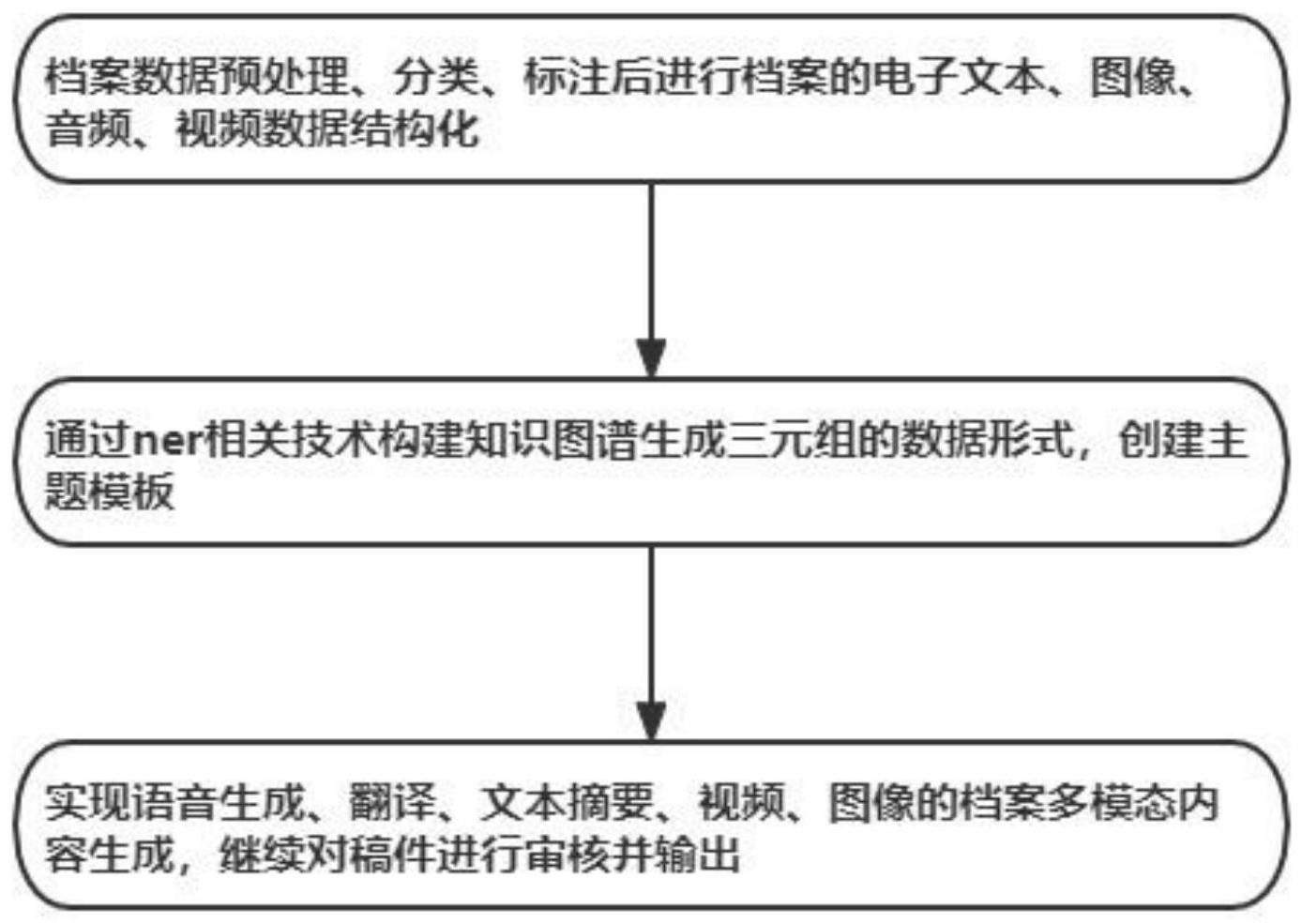
4、为解决上述技术问题,本发明提供如下技术方案,一种基于知识图谱的档案多模态智能编纂方法,包括:
5、档案数据预处理、分类、标注后进行档案的电子文本、图像、音频、视频数据结构化;通过ner相关技术构建知识图谱生成三元组的数据形式,创建主题模板;实现语音生成、翻译、文本摘要、视频、图像的档案多模态内容生成,继续对稿件进行审核并输出。
6、作为本发明所述的基于知识图谱的档案多模态智能编纂方法的一种优选方案,其中:所述档案结构化包括档案电子文本数据结构化、档案图像数据结构化、档案音频数据结构化以及档案视频数据结构化;
7、所述档案电子文本数据结构化包括文本关键信息模型抽取阶段和实体关系联合抽取阶段;
8、所述文本关键信息模型抽取阶段表示为:
9、
10、
11、
12、其中,precision为准确率、recall为召回率,f1为评价指标,tp表示正类被判断为正类的数量,fp表示负类被判断为正类的数量,fn表示正类被判断为负类的数量,tn表示负类被判断为负类的数量;
13、所述实体关系联合抽取阶段具体步骤如下:进行文本多特征获取,使用bert动态获取每个词语的上下文语义特征,采用cnn来获取文本中的词特征嵌入并提取到字符特征、pos进行词性标记,使用word2vec实现向量化得到文本词性特征拼接得到多粒度文本特征,使用bigcn获取区域特征表示,上一阶段的语义特征需要输入到注意力机制层,学习句子间的语义关系得到每个词语在某种特定关系下的权重值,并重新计算新的句子表示,通过lstm机制来实现冗余特征过滤,只保留下关键的特征,最后进行实体关系特征分类,多头注意力机制、bigcn特征获取和crf实体关系预测三个部分,将多头注意力机制获得的语义特征输入到bigcn中进行句间深层语义特征学习,在利用crf实现在某个关系下的头尾实体预测。
14、作为本发明所述的基于知识图谱的档案多模态智能编纂方法的一种优选方案,其中:所述档案图像数据结构化包括利用ocr模型进行文本检测和文本识别;
15、所述文本检测为dbnet文本检测表示为:将图像输入带有特征金字塔的resnet主干网络,通过自上而下地进行上采样,将采样的特征与具有相同尺寸的特征进行级联得到特征图f,特征图f用于预测概率图p和阈值图t,通过p和f计算出近似二值图,概率图p表示像素点为文本的概率,阈值图t表示每个像素点是否为文本,对每一个像素点进行自适应二值化由网络学习得到的,将二值化这一步骤加入网络一起进行训练;
16、所述文本识别为crnn文本识别表示为:输入图片经过卷积层提取得到一个特征序列,利用rnn对特征序列的每一帧进行预测,最后在输出层对rnn的每帧预测结果进行转录,得到最终的一个标签的序列,将rnn预测的每个字符组合得到一个完整的单词。
17、作为本发明所述的基于知识图谱的档案多模态智能编纂方法的一种优选方案,其中:所述档案音频数据结构化包括进行语音识别,在语音识别的基础上对语音识别的结果进一步进行语音数据结构化处理,对内容进行概括,抽取出摘要式的一段文本作为音频数据的关键信息,其中,语音识别采用wer来作为评价指标表示为:
18、
19、其中,word error rate为wer词错误率,num ofword为标准的词序列中词的总个数的百分比,substitution、deletion、insertion为插入、替换或删除的词的总个数。
20、作为本发明所述的基于知识图谱的档案多模态智能编纂方法的一种优选方案,其中:所述档案视频数据结构化包括采用自编码模型进行视频数据特征降维,对降维后的数据采用动态规划和聚类方法来进行关键帧抽取;
21、所述关键帧抽取包括包含人物数据的关键帧和包含文字的关键帧:对于所述包含人物数据的关键帧进行重要人物人脸识别,将数据与人物信息相结合,对于所述包含文字的数据进行所述的ocr识别,将图像ocr结果与视频关键帧相结合,采用的ocr方法同图像ocr方法,对于既包含人物又包含文字的关键帧进行人物信息抽取和ocr处理。
22、作为本发明所述的基于知识图谱的档案多模态智能编纂方法的一种优选方案,其中:所述知识图谱包括通过ner技术抽取出实体三元组,图像数据需要结构化后得到文本三元组,再与原始图像数据相关联,结合nlp相关技术将多来源、多模态档案知识进行知识抽取,并结合知识关联及知识聚类方法实现档案多模态语义知识关联,进行档案知识图谱可视化构建。
23、作为本发明所述的基于知识图谱的档案多模态智能编纂方法的一种优选方案,其中:所述多模态内容生成包括采用自然语言处理法进行语音生成、翻译、文本摘要、视频和图像生成进行深度语义理解与分析;
24、所述语音生成采用fastspeech2实现文本直接生成语音,模型结构为非回归形式的编码器和解码器,在编码层与解码层之间引入variance adaptor来进行音素之间的停顿预测、音调和音量的预测,更好地把握音频特征;
25、所述文本摘要包括模型预训练及其特征获取和句子内容生成两阶段,利用预训练语言模型bert获取新闻文章的词向量,同时利用多维语义特征对新闻中的句子进行打分简单拼接生成输入序列,第二阶段将得到的输入序列输入到指针生成网络模型中,使用coverage机制减少生成重复文字,同时保留生成新文字的能力得到档案文本摘要。
26、本发明的另外一个目的是提供一种基于知识图谱的档案多模态智能编纂方法的系统,结合了ner、语音识别、视频抽帧、ocr、人脸识别等多种深度学习方法对档案多模态非结构化数据进行知识抽取,构建多模态档案聚类库,基于档案知识图谱,结合档案生成规则和档案生成方法,实现了档案多模态关键信息抽取,有效提高了档案编研工作的效率。
27、一种基于知识图谱的档案多模态智能编纂系统,其特征在于,包括人脸识别模块,ocr模块,语音识别模块,摘要抽取模块,语音合成模块,视频关键帧抽取模块。
28、所述人脸识别模块,构建人脸数据库后进行人脸对齐预处理,再利用人脸识别算法提取样本的人脸特征向量并输出与其相似度最高的人脸身份。
29、所述ocr模块,图像文本位置检测阶段使用dbnet模型来进行特征提取,档案文本内容识别阶段使用crnn神经网络模型实现最终的一个标签的序列。
30、所述语音识别模块,采用基于transformer的语言模型实现文本表示结果。
31、所述摘要抽取模块,结合了bert得到档案文本摘要。
32、所述语音合成模块,采用fastspeech2实现文本直接生成语音,在编码层与解码层之间引入variance adaptor音素之间的停顿预测、音调和音量的预测,更好地把握音频特征。
33、所述视频关键帧抽取模块,基于深度学习的方法采用自编码模型进行视频数据降维,对降维后的数据采用动态规划和聚类的方法进行关键帧抽取。
34、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现一种基于知识图谱的档案多模态智能编纂方法的步骤。
35、一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现一种基于知识图谱的档案多模态智能编纂方法的步骤。
36、本发明的有益效果:本发明结合了ner、语音识别、视频抽帧、ocr、人脸识别等多种深度学习方法对档案多模态非结构化数据进行知识抽取,实现了档案多模态关键信息抽取,摒弃了传统的人工知识梳理,提高了档案知识抽取的准确性和抽取效率;构建多模态档案聚类库,以知识图谱的形式将结构化档案多模态知识进行主题聚类后将知识进行关联,将孤立的知识进行关联起来,避免了信息孤岛,提高了档案知识的利用率;基于档案知识图谱,结合档案生成规则和档案生成方法,实现了档案主题多模态内容编研,实现了档案文本、语音、图片及其视频多模态相关内容生成,有效提高了档案编研工作的效率。
- 还没有人留言评论。精彩留言会获得点赞!