一种基于无监督伪语义数据增强的零样本多语言理解算法
本发明属于自然语言处理领域,涉及到一种数据增强多语言算法,具体是一种基于无监督伪语义数据增强的零样本多语言理解算法。
背景技术:
1、多语言表示学习在自然语言理解任务中利用资源丰富的语言信息去提升资源匮乏语言表示的准确性,并在下游任务上进行实验验证,如文本分类、情感分析、信息抽取、问答等。现有的多语言工作依靠有监督的平行语料和浅层无监督数据增强机制,显式地在多语言之间分享语义信息。这些数据增强方法可被分为两大类一类是平行语料数据增强,一类是无监督浅层数据增强。
2、a.平行语料数据增强工作利用双语词典和翻译工具等将不同语言之间语义进行对齐,但这些语料耗费时间和依赖人工标注。
3、b.无监督浅层数据增强工作利用无监督eda操作(回译、随机删除、随机替换等)来为训练数据引入大量上下文语义信息。
4、然而这些方法都仅仅关注字符串表面信息去对齐多语言间的数据,没有考虑到深层的句子上下文内在表示。如图1所示。
5、相关现有技术:
6、a.多语言预训练模型
7、现有多语言预训练模型分为两大类:
8、(1)单语训练数据,m-bert和xlm-r等预训练模型利用单语言文本通过掩码语言模型任务来训练模型,通过高资源语义到低资源语言的知识迁移能力来获得最终对多语言输入的表示。
9、(2)多语言训练数据,一些工作将xlm-r的进行扩展,利用对齐技术在不同语言的表示层面进行映射对齐后进行训练。还有一些工作利用对齐工具在双语言语料中进行操作,以鼓励模型学习到更多语言知识。
10、b.多语言数据增强
11、现有多语言数据增强工作可分为两大类:
12、(1)有监督的数据增强,cosda-ml工作提出了一种编码转换框架利用已经映射好的平行多语言字典,给训练语句注入多语言知识。mulda引入一个多语言命名实体识别模型,其中多语言部分利用翻译器来引入其他语言的信息。也有工作利用对齐工具将源语言和目标语言的表示空间进行整合。
13、(2)无监督的数据增强,一些工作利用对抗训练为训练数据引入增强的知识。也有一些工作借助生成模型来生成多语言样本,并将这些样本所包含的知识导入模型内部。同时,回译、单词替换、低资源语言句子选择机制等数据增强技术也较为高频地被用来提升模型在多语言上的表示能力。
14、c.mbert预训练模型
15、mbert是由bert衍生的多语言预训练模型,可以将多种语言表示在相同的语义空间中。它首先通过预训练建立的词表库对输入文本进行分词,然后将每个token映射到词表中唯一的索引位置,再根据索引位置去构建模型的三个输入信息,即语义嵌入,片段嵌入和位置嵌入。接着利用自注意力机制计算每个token之间的相互信息交互的程度,对句子的上下文语义进行全局建模。再通过添加多头注意力机制来进一步捕捉表示空间多层次语义。最后在全连接前馈网络引入了非线性激活函数,变换了attention输出的空间,增加了模型的表现能力。其模型结构如图2所示。
技术实现思路
1、为解决依赖平行语料和关注浅层数据增强的问题,本发明的目的是提供一种基于无监督伪语义数据增强的零样本多语言理解算法,该算法以一种无监督的聚类方式减轻对多语言平行语料的依赖,且可以充分利用深层语义关系对低资源语言进行数据增强,最终算法使得模型在下游任务上表现较好。
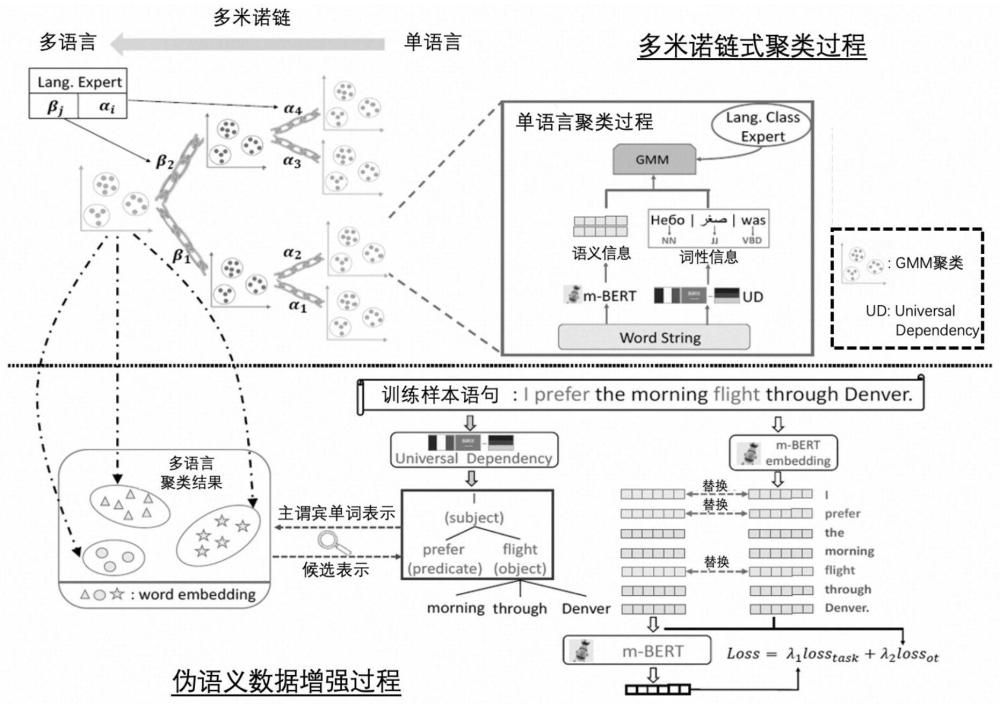
2、一种基于无监督伪语义数据增强的零样本多语言理解算法,具体步骤如下:
3、s1:利用文本编码器对文本进行编码;
4、s2:利用多米诺链式聚类过程来进行聚类,把不同语言的相似语义单词聚类到一起;多米诺链式聚类过程由3个接续阶段组成,单语言聚类阶段、语系聚类阶段和多语言聚类阶段;每个聚类阶段用gmm算法将具有相似语义的多语言单词聚到一个类中;
5、s3:伪语义数据增强过程首先将上下文感知语义去表示当做伪语义单词单元;句子利用多语言句法解析器将句子解析成树结构,并将句子的主谓宾看做句子主要组成部分;利用主谓宾单词所属同一类的任一多语言元素表示来替换主谓宾原有表示;除此之外,设计一个去偏最优传输仿射正则模块去解决替换前后句子表示所在空间偏差问题,以获得更快速和更稳定的收敛过程;
6、s4:联合任务损失和去偏最优传输正则损失去更新模型参数;最终得到一个较为精确的多语言模型;其中:
7、所述文本编码器:
8、设训练语句si由l个单词组成,
9、si=(wi1,wi2,…,wij,…,wil)
10、利用m-bert来当做文本编码器,并取第一层表示和最后一层表示的平均来当做文本最终表示;故单词wij的表示为其中表示模型第一层对单词wij处理后的结果,表示模型最后一层对单词wij处理后的结果,
11、
12、同理,句子si的表示为
13、
14、所述多米诺链式聚类过程,具体是:
15、利用3个接续聚类阶段来获得多语言聚类过程;
16、a.单语言聚类阶段:利用单词的词性和单词编码后的表示一起作为聚类指标来进行聚类,以获得单语言聚类结果;其中|sinm|是参与聚类的第m个单语言的单词总数,表示第m个单语言聚类后的类数,表示单语言聚类后的第1个类集合,
17、
18、b.语系聚类阶段:将单语言的各聚类中心表示hsin赋以专家权重asin后送入gmm聚类器,获得的语系聚类结果,其中表示第n个语系聚类后的类数,表示语系聚类后的第1个类集合,
19、
20、c.多语言聚类阶段:将语系聚类的各聚类中心表示hfam赋以专家权重bfam后送入gmm聚类器,获得的多语言聚类结果,其中表示多语言聚类后的第1个类集合,
21、
22、所述伪语义数据增强过程,具体是:
23、a.利用编码器获得句子的表示并利用多语言句法解析器获得句子的句子主谓宾成分,其中是句子中第一个token的嵌入表示,和分别是句子里主谓宾成分的嵌入表示,|ls|是句子的token总数,
24、
25、选取主谓宾成分所在聚类的任一多语言表示和去替换句子表示中主谓宾成分的表示,替换后句子的表示为
26、
27、然后将替换后的句子表示通过transformers进行句子表示整合;
28、b.去偏最优传输正则化,
29、为整合替换前后句子表示空间差异的问题,借助最优传输wasserstein距离收缩损失lossot、去偏特征值收缩损失losseig、去偏距离收缩损失lossdis一起构成正则化损失lossreg,其中ρ1、ρ2和ρ3是可训练的比例超参数,
30、
31、模型训练目标:
32、模型整体训练优化目标losstotal由任务损失losstask和去偏最优传输正则化损失lossreg构成,其中λ1和λ2是比例控制参数,
33、losstotal=λ1losstask+λ2lossreg。
34、本发明的有益效果:本发明借助无监督聚类操作将相同语义不同语言的单词进行对齐,减轻了模型在多语言情境下对平行语料或者翻译器的依赖;对低资源语言从深层语义角度出发对其进行数据增强,而非传统的从字符串表面进行简单增强;算法作用下的预训练模型,在文本分类、情感分析、信息抽取、问答任务上均取得了较好的实验效果,且消融实验结果也验证了算法各个组成部分的有效性。
- 还没有人留言评论。精彩留言会获得点赞!